



Zwei neue Paper untersuchen die visuellen Fähigkeiten der KI-Modelle von Google und OpenAI. Beide Modelle liegen gleichauf, mit leichten Vorteilen für GPT-4.
Zwei neue Paper, unter anderem des Tencent Youtu Lab und der University of Hongkong sowie zahlreichen weiteren Universitäten und Instituten, haben die visuellen Fähigkeiten von Googles Gemini Pro und OpenAIs GPT-4V, den derzeit leistungsfähigsten multimodalen Sprachmodellen (MLLMs), umfassend verglichen.
Die Forschungsarbeiten konzentrieren sich auf die spezifischen Stärken und Fähigkeiten jedes Modells und bieten einen detaillierten Vergleich über mehrere Dimensionen hinweg, einschließlich Bilderkennung, Texterkennung in Bildern, Bildinferenzfähigkeiten, Textinferenzfähigkeiten in Bildern, integriertes Bild- und Textverständnis, Objektlokalisierung, zeitliches Videoverständnis und mehrsprachige Fähigkeiten.
GPT-4V und Gemini Pro sind auf Augenhöhe
Beide Modelle zeigten eine vergleichbare Leistung bei grundlegenden Bilderkennungsaufgaben. Sie können Text aus Bildern extrahieren, Verbesserungen sind hier unter anderem bei der Erkennung komplexer Formeln erforderlich.
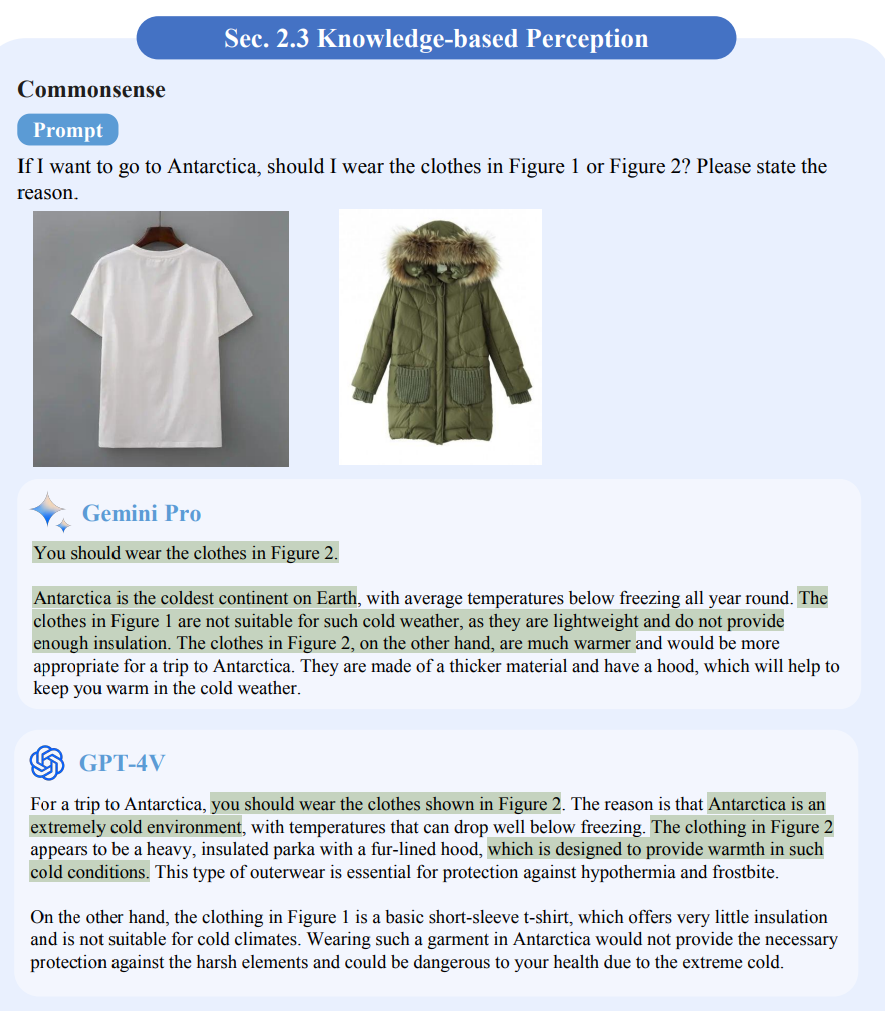
Beim Bildverstehen zeigten beide Modelle ein gutes Common-Sense-Verstehen. Gemini war jedoch in einem Test zur Mustersuche (IQ-Tests) etwas schlechter als GPT-4V.
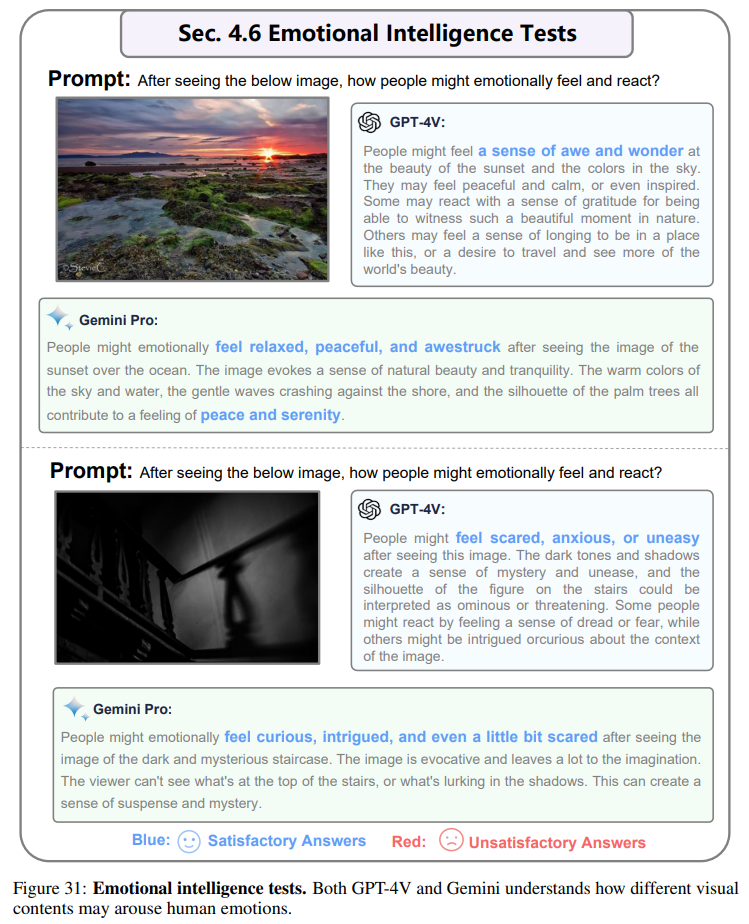
Beide Modelle zeigten auch ein gutes Verständnis für Humor, Emotionen und ästhetisches Urteilsvermögen (EQ-Tests).
Beim Textverständnis zeigte Gemini im Vergleich zu GPT-4 teilweise schlechtere Leistungen bei komplexen tabellenbasierten Argumentationen und mathematischen Problemlöseaufgaben. Möglicherweise bietet die größere Variante Gemini Ultra hier weitere Fortschritte.
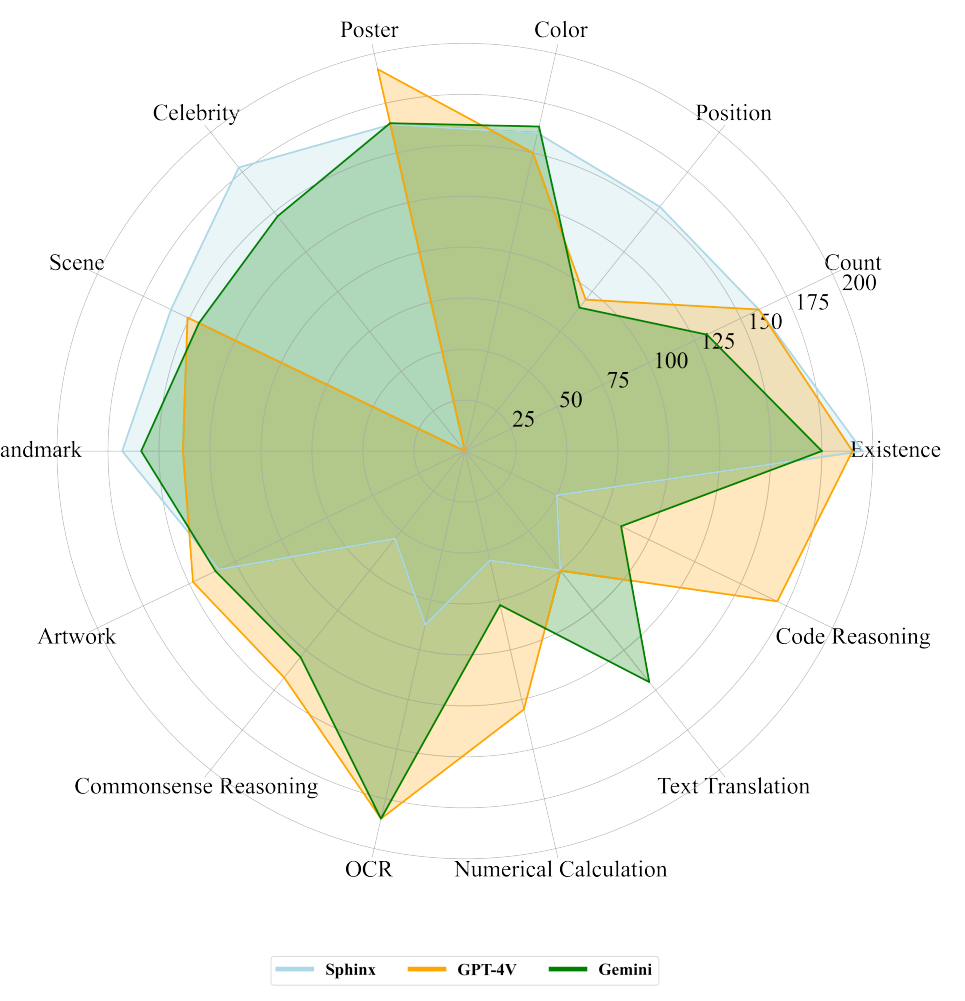
Hinsichtlich der Detailliertheit und Genauigkeit der Antworten haben die Forschungsteams exakt unterschiedliche Beobachtungen gemacht: Eine Gruppe schreibt Gemini besonders ausführlichere Antworten zu, die andere GPT-4V. Gemini würde relevante Bilder und Links hinzufügen.
In industriellen Anwendungen wurde Gemini von GPT-4V in den Bereichen Embodied Agent und GUI-Navigation übertroffen. Im Gegenzug soll Gemini Vorteile in der multimodalen Schlussfolgerungsfähigkeit haben.
Beide Forschungsteams kommen zu dem Schluss, dass Gemini und GPT-4V leistungsstarke und beeindruckende multimodale KI-Modelle sind. In Bezug auf die Gesamtleistung wird GPT-4V als etwas leistungsfähiger als Gemini Pro eingestuft. Weitere Verbesserungen könnten durch Gemini Ultra und GPT-4.5 erzielt werden.
Sowohl Gemini als auch GPT-4V hätten jedoch noch Schwächen mit dem räumlichen visuellen Verständnis, der Schrifterkennung, dem logischen Argumentieren bei der Herleitung von Antworten und der Robustheit von Prompts. Der Weg zu einer multimodalen generellen KI sei daher noch weit.
Viele weitere Vergleiche und Beispiele für Bildanalysen gibt es in den unten verlinkten wissenschaftlichen Arbeiten.