


OpenAIs neues Open-Source-Modell "Whisper" kann viele Sprachen transkribieren und als Grundlage für Audio-Anwendungen dienen.
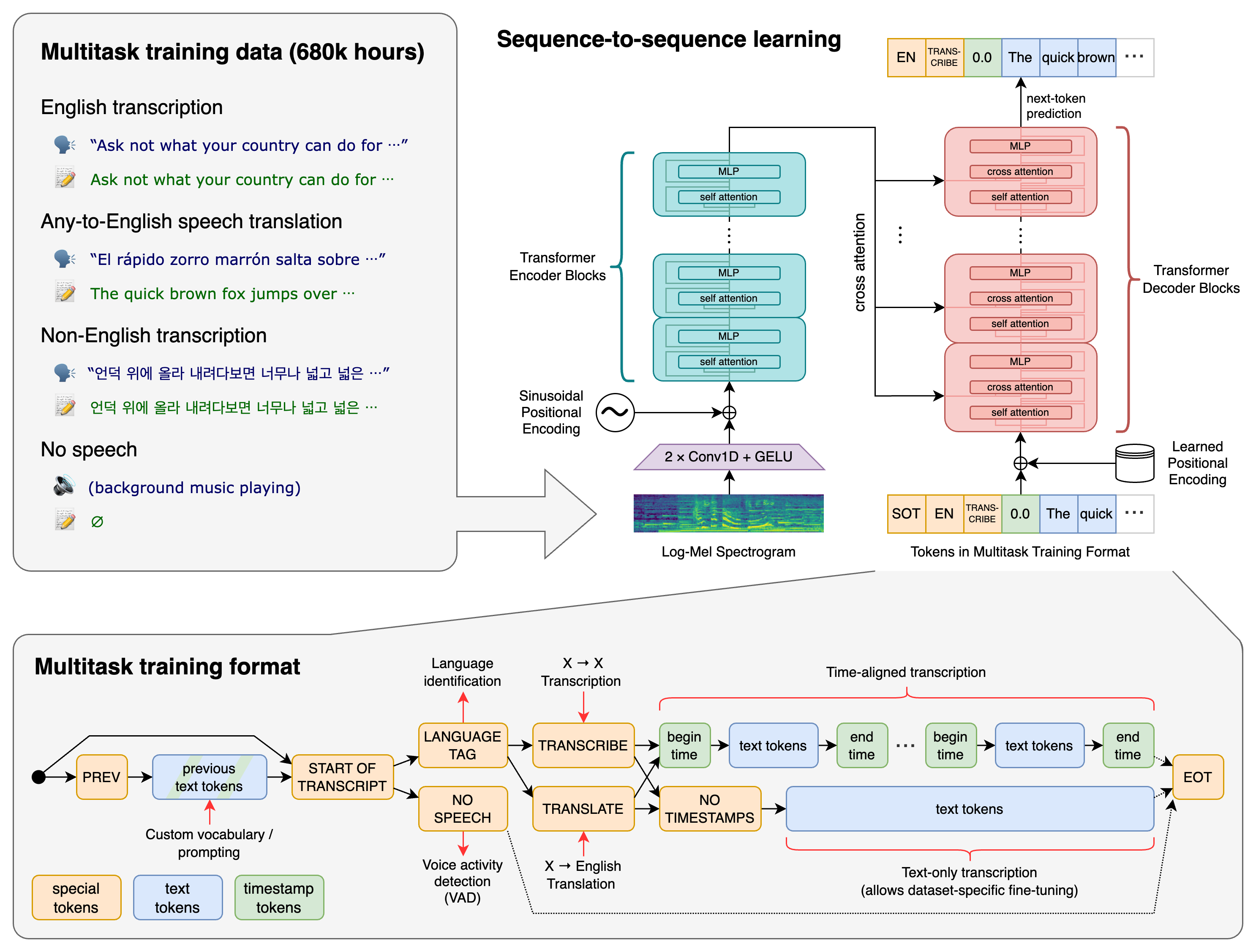
Whisper wurde laut OpenAI mit 680.000 Stunden Audio- und Multitasking-Daten (bspw. Transkription, Übersetzung, mit Hintergrundmusik etc.) trainiert. Das Transformer-basierte Modell beweist laut OpenAI, dass dieses umfassende Datentraining Spracherkennung robuster macht gegenüber Akzenten, Hintergrundgeräuschen und technischer Sprache.
Whisper unterstützt die Erkennung, Transkription und Übersetzung in verschiedenen Sprachen sowie die Identifikation einer Sprache. In der englischen Sprache, die rund zwei Drittel des Trainingsdatensatzes ausmachte, soll sich Whispers Spracherkennungsfähigkeit menschlichem Niveau annähern.
Whisper, a neural net that approaches human level robustness and accuracy on English speech recognition. Attached is transcriptions of the same voicemail with iOS vs Whisper. Available today as open-source: https://t.co/fyHWviSfa4 pic.twitter.com/jgNAsBkB2H
— Greg Brockman (@gdb) September 21, 2022
OpenAI hebt Zero-Shot-Fähigkeit hervor
Im Spracherkennungsbenchmark LibriSpeech erreicht Whisper nicht die Performance kleinerer, spezialisierter KI-Sprachmodelle, die etwa mit Audio-Text-Paaren speziell für diesen Benchmark trainiert wurden.
Jedoch hebt OpenAI Whispers Zero-Shot-Fähigkeit ohne vorherige Feineinstellung hervor, dank der das Modell bei Tests über viele verschiedene Datensätze hinweg eine um 50 Prozent geringere Fehlerrate aufweist als zuvor genannte Systeme. Whisper ist laut OpenAI "viel robuster" als auf LibriSpeech spezialisierte Spracherkennungsmodelle.
Diese Messungen gelten für die englische Spracherkennung. Die Fehlerrate steigt bei im Datensatz unterrepräsentierten Sprachen. Zudem warnt OpenAI, dass Whisper Wörter transkribieren könnte, die nicht gesprochen wurden: Die Firma führt das auf die im Datentraining enthaltenen verrauschten Audioaufnahmen zurück.
Whisper ist laut OpenAI App-fähig
OpenAI stellt Whisper als Open-Source-Modell kostenlos bei Github zur Verfügung. Die Firma veröffentlicht Whisper laut eigenen Angaben hauptsächlich für die Forschung und als Grundlage für weitere Arbeiten für bessere Spracherkennung.
Die Whisper-Modelle könnten zwar nicht direkt für Spracherkennungsanwendungen verwendet werden. Doch die Geschwindigkeit und Größe der Modelle ließen wohl aufbauende Anwendungen zu, die eine Echtzeit-Spracherkennung und -Übersetzung in Echtzeit bieten. Die Geschwindigkeit und Genauigkeit von Whisper sei die Grundlage für Anwendungen für eine bezahlbare automatische Transkription und Übersetzung großer Mengen an Audiodaten.
Möglich, dass OpenAI Whisper auch für eigene Zwecke nutzt: Für das Training von Sprachmodellen wie GPT-3 und demnächst GPT-4 benötigt die Firma große Mengen Text. Durch die automatische Transkription von Audiodateien hätte OpenAI Zugang zu noch mehr Textdaten.