


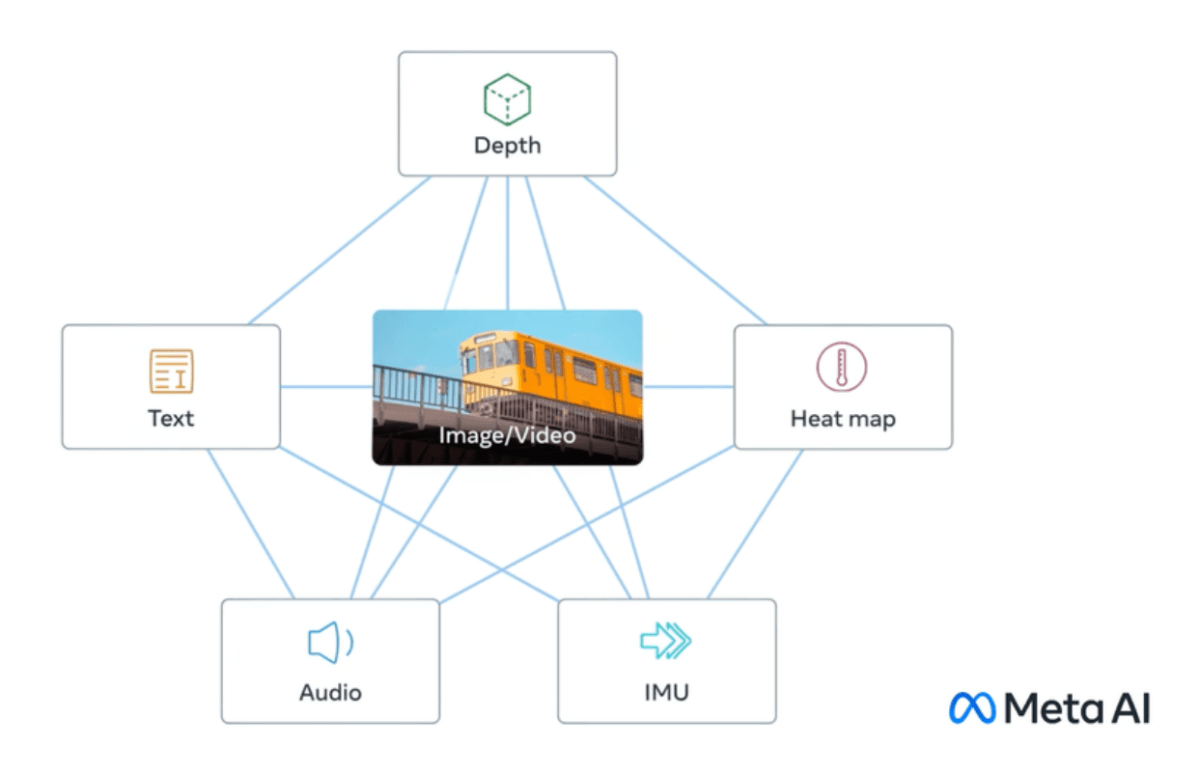
ImageBind von Meta ist ein neues multimodales Modell, das sechs Datentypen kombiniert. Meta veröffentlicht es als Open Source.
ImageBind lässt das Metaverse etwas weniger als eine ferne Zukunftsvision erscheinen: Das KI-Modell versteht neben Text auch Audio, visuelle Daten, Daten von Bewegungssensoren sowie Wärme- und Tiefendaten.


Zumindest theoretisch ist es damit als wichtiger Baustein für generative KI-Modelle vielseitig einsetzbar. Es könnte zum Beispiel als Grundlage für generative Modelle dienen, die Sensordaten und 3D kombinieren, um immersive virtuelle Welten zu entwerfen (VR), schreibt Meta, oder digitale Daten kontextsensitiv in die Realität einblenden (AR). VR und AR sind zwei Schlüsseltechnologien in der langfristigen Metaverse-Vision von Meta.
Als weitere Beispiele nennt Meta eine Videoaufnahme eines Sonnenuntergangs, die automatisch mit einem passenden Soundclip unterlegt wird, oder ein Bild eines Shih Tzu, das 3D-Daten ähnlicher Hunde generiert, oder einen Aufsatz über die Rasse.
Für ein Video, das mit einem Modell wie Make-A-Video von Meta erstellt wurde, könnte ImageBind einem generativen KI-Modell helfen, die passenden Hintergrundgeräusche zu erzeugen oder die Tiefendaten aus einem Foto vorherzusagen.
ImageBind führt verschiedene Datentypen in einem Raum zusammen
KI-Systeme arbeiten häufig mit verschiedenen Datentypen (sogenannten Modalitäten) wie Bildern, Text und Ton. Die KI versteht und verknüpft diese verschiedenen Datentypen miteinander, indem sie sie in Zahlenlisten - sogenannte Embeddings - umwandelt und in einem gemeinsamen Raum zusammenfasst. Diese Embeddings helfen der KI, die in den Daten enthaltenen Informationen zu erkennen und Beziehungen zwischen ihnen herzustellen.
Das Besondere an ImageBind ist, dass es eine gemeinsame Sprache für diese unterschiedlichen Datentypen schaffen kann, ohne dass Beispiele benötigt werden, die alle Datentypen enthalten. Solche Datensätze wären nur aufwendig oder gar nicht zu beschaffen.
Erreicht wird dies durch den Einsatz großer Vision-Language-Modelle, also KI-Modelle, die darauf trainiert sind, sowohl Bilder als auch Text zu verstehen. ImageBind erweitert die Fähigkeit dieser Modelle, neue Modalitäten wie Video-Audio- und Tiefenbilddaten zu verarbeiten, indem die natürlichen Verbindungen zwischen diesen Datentypen und Bildern genutzt werden.
Bilddaten als Brücke zwischen den Modalitäten
Um vier zusätzliche Modalitäten (Audio, Tiefe, Wärmebild und IMU) zu integrieren, verwendet ImageBind unstrukturierte Daten. Die KI kann aus den natürlichen Verbindungen zwischen den Datentypen lernen, ohne dass explizite Markierungen erforderlich sind - daher auch der Name des Modells, das alles an Bilder bindet.
Dies ist laut Meta möglich, da Bilder häufig mit verschiedenen anderen Modalitäten kombiniert und als Brücke zwischen diesen verwendet werden können. Beispielsweise treten Bilder und Text im Internet häufig gemeinsam auf, sodass das Modell die Beziehung zwischen ihnen lernen kann.
In ähnlicher Weise können Bewegungsdaten von tragbaren Kameras mit IMU-Sensoren mit den entsprechenden Videodaten verknüpft werden. Durch die Nutzung dieser natürlichen Paarungen schafft ImageBind einen gemeinsamen Einbettungsraum, der es der KI ermöglicht, mehrere Modalitäten besser zu verstehen und mit ihnen zu arbeiten.
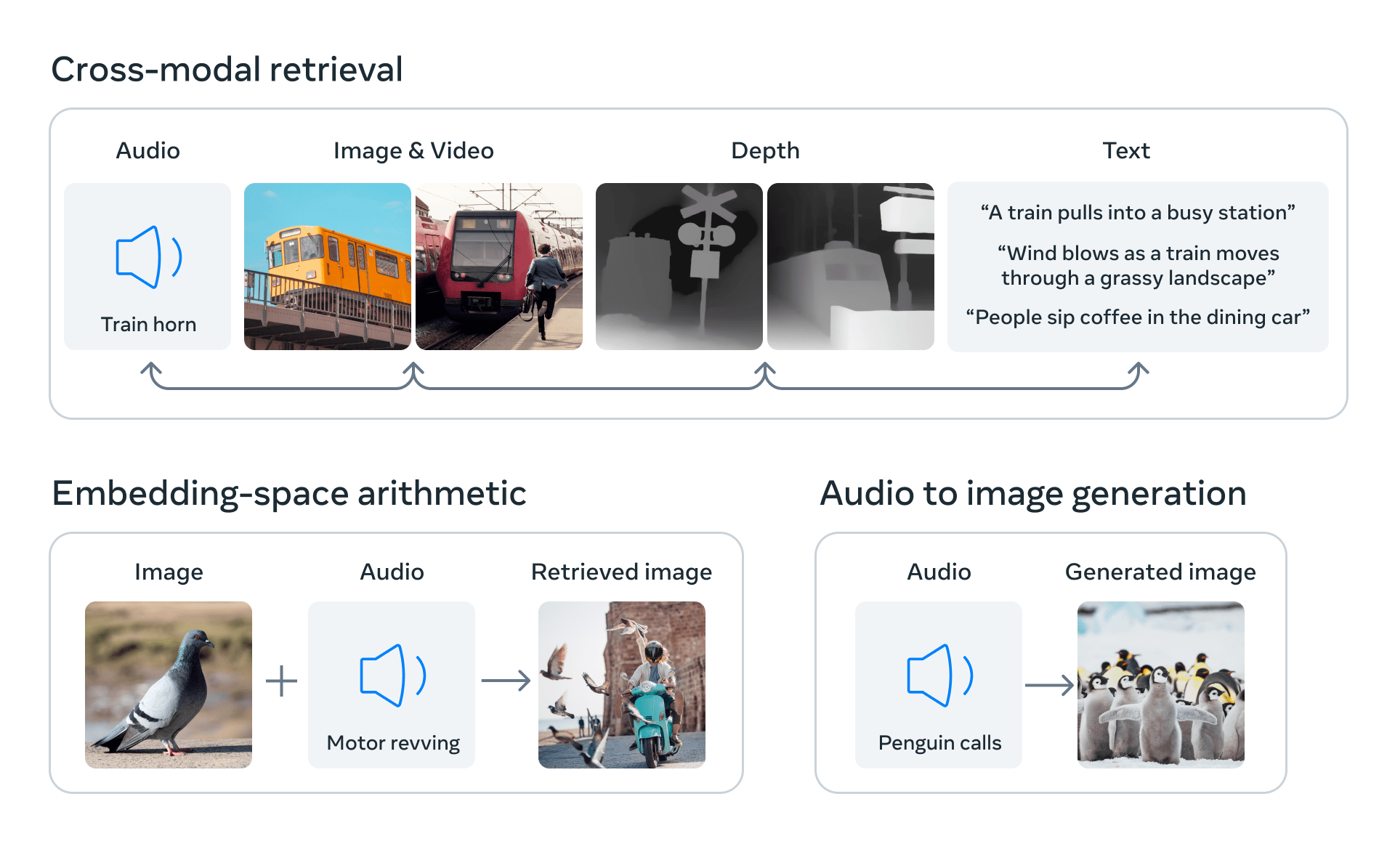
ImageBind zeigt, dass mit Bildern gepaarte Daten ausreichen, um diese sechs Modalitäten miteinander zu verknüpfen. Das Modell kann Inhalte ganzheitlicher interpretieren, indem die verschiedenen Modalitäten miteinander "sprechen" und Verbindungen finden, ohne dass sie zusammen gesehen werden müssen. Zum Beispiel kann ImageBind Audio und Text miteinander verbinden, ohne sie zusammen zu sehen. Dies ermöglicht es anderen Modellen, neue Modalitäten zu "verstehen", ohne ressourcenintensive Schulungen durchführen zu müssen.
Meta
ImageBind ist also wie eine Abkürzung, die der KI hilft, die verschiedenen Datentypen zu verstehen und leichter miteinander zu verknüpfen. Mit diesem Modell können KI-Forschende die Beziehungen zwischen verschiedenen Datentypen effizienter untersuchen und vielseitigere KI-Modelle entwickeln, schreibt Meta.
In Zukunft könnte das Modell durch andere sensorische Daten wie Berührung, Sprache, Geruch und sogar fMRI-Signale des Gehirns ergänzt werden, schreibt Meta. Damit kämen Maschinen der menschlichen Fähigkeit näher, gleichzeitig, ganzheitlich und direkt aus vielen verschiedenen Informationen zu lernen.
Meta veröffentlicht den Code für ImageBind als Open Source bei Github unter einer CC-BY-NC 4.0 Lizenz, die keine kommerzielle Nutzung gestattet.