



Mit Microsofts Medprompt übertrifft GPT-4 spezialisierte Modelle in medizinischen Anwendungen. Der Prompt hat auch darüber hinausgehende Anwendungen.
OpenAI GPT-4 hat bereits in der Vergangenheit gezeigt, dass es mit geeigneten Prompts medizinische Fragen mit hoher Genauigkeit beantworten kann. In vielen Fällen lag das große Sprachmodell aber noch hinter spezialisierten Varianten wie Med-PaLM-2 zurück.
In einer neuen Arbeit erreicht ein Team von Microsoft nun mit GPT-4 neue Spitzenwerte in medizinischen Fragen-Benchmarks und übertrifft dabei auch spezialisierte Modelle. Dieser Sprung ist auf eine neue Prompting-Strategie zurückzuführen, die verschiedene Ansätze kombiniert und auch auf andere Bereiche übertragbar ist.
Microsofts Medprompt kombiniert drei Methoden
Die Methode, die sie "Medprompt" nennen, kombiniert dynamische Few-Shot-Auswahl, selbstgenerierte Chain-of-Thought (CoT) und Choice Shuffle Ensembling.

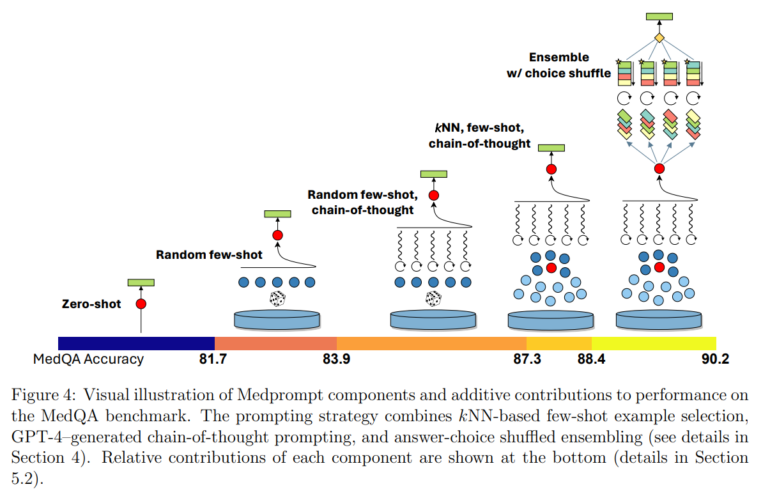
Die drei Elemente von Medprompt sind
- Dynamische Auswahl von Beispielen: Für jede Frage werden zuvor gesammelte, ähnliche Trainingsbeispiele ausgewählt, um dem Modell einen Kontext zu geben.
- Selbstgenerierte Chain-of-Thought: Das Modell generiert selbstständig ein CoT-Prompt, wobei es sich an zuvor automatisiert erstellten CoT-Prompts aus Trainingsdaten orientiert.
- Choice Shuffle Ensembling: Die Antwortoptionen werden mehrfach in unterschiedlicher Reihenfolge präsentiert, um eine Verzerrung durch die Position der Optionen zu vermeiden. Aus den so mehrfach generierten Antworten wird die beste durch Mehrheitswahl ausgewählt.
Die zuvor erstellten Trainingsbeispiele, die Fragen und Antworten sowie CoT-Prompts enthalten, die zu richtigen Antworten geführt haben, werden ebenfalls automatisiert aus Benchmarks über GPT-4 und einem Embedding-Modell erzeugt. Die Embeddings werden in der Inferenzphase verwendet, um ähnliche Beispiele für die neuen Fragen zu finden.
Medprompt erreicht neuen State-of-the-Art in medizinischen Benchmarks
Mit Medprompt konnte das Team zum ersten Mal eine GPT-4-Trefferquote von über 90 % im MedQA-Datensatz erreichen und erzielte die besten berichteten Ergebnisse in allen neun Benchmark-Datensätzen der MultiMedQA-Suite. Weitere Verbesserungen seien durch die Erhöhung der Anzahl der Few-Shot-Exemplare und die Erhöhung der Anzahl der Ensemble-Schritte möglich.


Die Forscher weisen jedoch darauf hin, dass die gute Leistung von GPT-4 mit Medprompt in Benchmarks nicht direkt die Wirksamkeit des Modells und der Methoden in der realen Welt widerspiegelt.
Medprompt zeigt auch Verbesserungen in anderen Bereichen
Der entwickelte Prompt ist auf andere Anwendungen übertragbar, da er auf Expertenwissen und manuelles Prompt-Design verzichtet, wie z.B. bei den Few-Shot-Beispielen oder dem Chain-of-Thought-Prompt. Das Team führte einige Tests in Bereichen des MMLU-Benchmarks durch, wie etwa Professional Law, Professional Accounting, Philosophy oder Professional Psychology. In allen Bereichen zeigte Medprompt eine durchschnittliche Verbesserung von 7,3 Prozent.


Das Team sieht in diesen Ergebnissen einen deutlichen Hinweis darauf, dass das Medprompt zugrunde liegende Framework auch auf andere Bereiche und Anwendungsgebiete über Multiple-Choice-Fragen hinaus verallgemeinert werden kann.
Alle Details zur Implementation sind im Paper zu finden.