



Forschende von Metas AI Research (FAIR), HuggingFace, AutoGPT und GenAI stellen den KI-Benchmark GAIA (General AI Assistants) vor, der die Leistung von KI bei für Menschen einfachen Aufgaben misst.
Der Benchmark basiert auf der These, dass eine mögliche Allgemeine Künstliche Intelligenz (AGI) den Menschen auch bei Aufgaben übertreffen muss, die für den Durchschnittsmenschen leicht zu lösen sind.
Im Gegensatz dazu gehe der Trend in Benchmarks eher dahin, KI Aufgaben lösen zu lassen, die für Menschen schwierig sind oder eine hohe fachliche Qualifikation erfordern.
GAIA soll die Entwicklung von KI-Systemen mit menschenähnlichen Fähigkeiten in einem breiteren Aufgabenspektrum fördern. Die Lösung des GAIA-Benchmarks wäre ein Meilenstein in der KI-Entwicklung, vermutet das Forscherteam.
466 Alltagsaufgaben
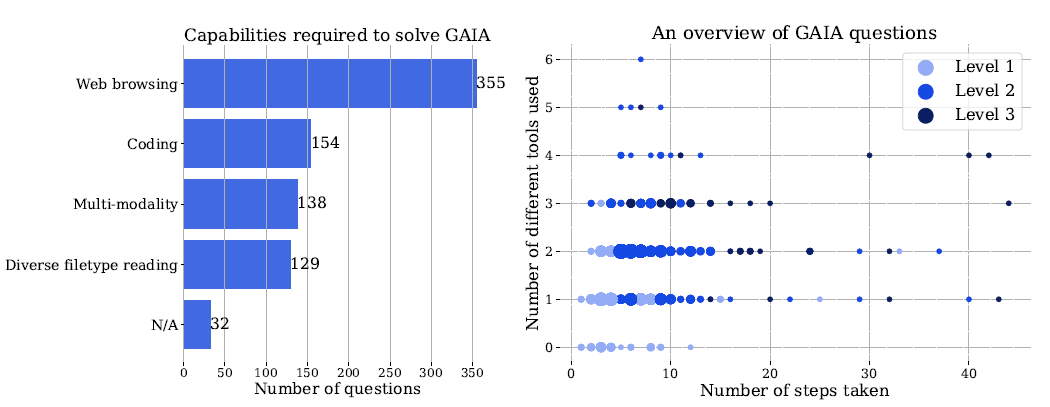
GAIA besteht aus 466 Fragen, die grundlegende Fähigkeiten wie logisches Denken, den Umgang mit verschiedenen Modalitäten, das Navigieren im Internet und den kompetenten Einsatz von Werkzeugen (z.B. Internetsuche) erfordern. Die Fragen sind so konzipiert, dass sie für KI-Systeme herausfordernd, für Menschen jedoch konzeptionell einfach sind.

Die Fragen werden in drei Schwierigkeitsstufen eingeteilt, je nach Anzahl der Schritte, die zur Lösung der Fragen erforderlich sind, und je nach Anzahl der verschiedenen Werkzeuge, die benötigt werden.
Level-1-Fragen erfordern in der Regel keine Werkzeuge oder höchstens ein Werkzeug, aber nicht mehr als fünf Schritte. Level-2-Fragen umfassen in der Regel mehr Schritte, etwa fünf bis zehn, und erfordern die Kombination mehrerer Werkzeuge. Level-3-Fragen erfordern, dass ein System beliebig lange Sequenzen von Aktionen ausführt, beliebig viele Werkzeuge verwendet und einen allgemeinen Zugang zur Welt hat.
GAIA versucht, die Fallstricke der derzeitigen KI-Bewertungsmethoden zu vermeiden, indem es leicht interpretierbar, nicht manipulierbar und einfach zu bedienen ist. Die Antworten sind faktenbasiert, prägnant und eindeutig und ermöglichen eine einfache, schnelle und objektive Bewertung. Die Fragen sind so formuliert, dass sie im Zero-Shot-Verfahren beantwortet werden können, was die Bewertung erleichtert.
GPT-4 versagt bei einfachen Aufgaben
In der ersten Evaluierung hatten selbst hoch entwickelte KI-Systeme wie GPT-4 mit Plugins Schwierigkeiten mit dem GAIA-Benchmark.
Bei den einfachsten Aufgaben (Level 1) erreichte GPT-4 mit Plugins nur eine Erfolgsquote von rund 30 Prozent, bei den schwierigsten Aufgaben (Level 3) lag sie bei 0 Prozent. Im Gegensatz dazu erreichten menschliche Testpersonen über alle Schwierigkeitsstufen hinweg eine durchschnittliche Erfolgsquote von 92 Prozent, GPT-4 lag durchschnittlich nur bei 15 Prozent.
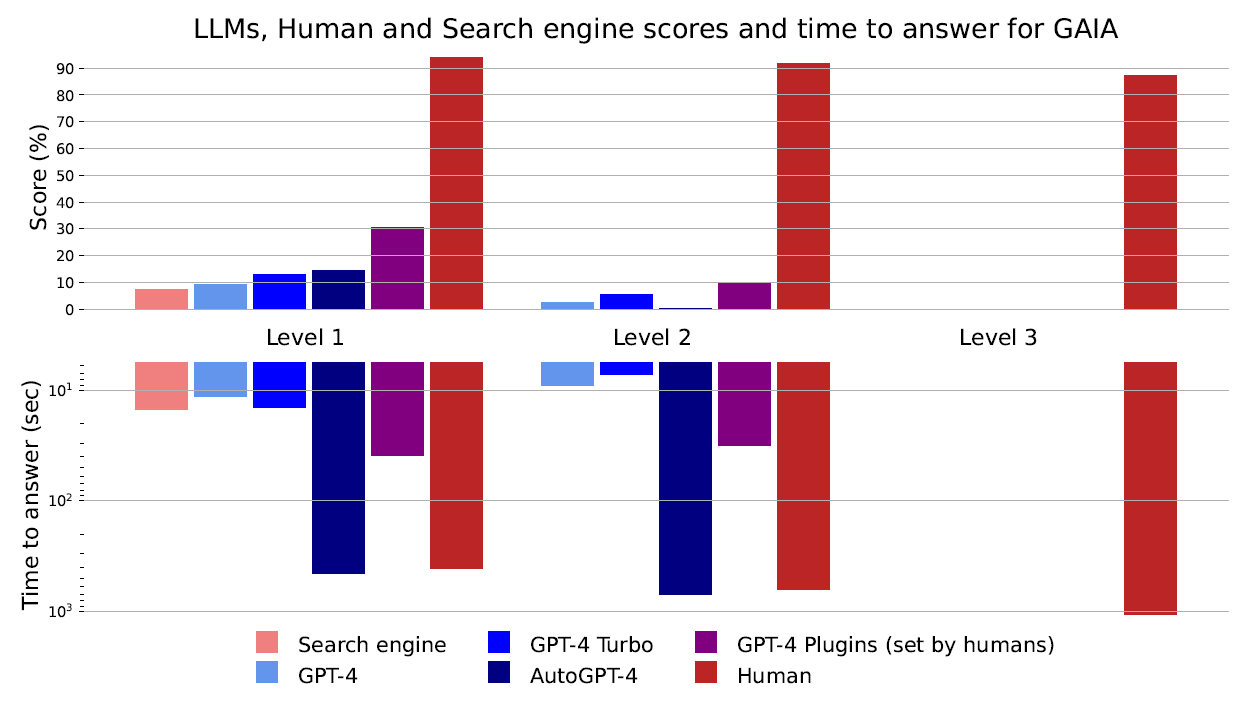
Im Allgemeinen erzielte GPT-4 die besten Ergebnisse mit Plugins, die von Menschen für die Aufgabe definiert wurden. Plugins sind für LLMs wie Werkzeuge, auf die sie zurückgreifen, wenn sie eine Aufgabe nicht mit ihren eigenen Fähigkeiten lösen können.
Die Forschenden sehen darin eine Bestätigung des "großen Potenzials" dieser Forschungsrichtung. Eine im März von OpenAI veröffentlichte Studie über die Auswirkungen von LLMs auf den Arbeitsmarkt bezog sich ebenfalls speziell auf Sprachmodelle, die auf Werkzeuge zurückgreifen.
Die Studie hat jedoch eine Einschränkung: Alle menschlichen Tester hatten einen akademischen Hintergrund (Bachelor: 61 %, Master: 26 %, PhD: 17 %). In den USA hingegen hatten 2022 nur 37,7 Prozent der über 25-Jährigen einen Bachelor-Abschluss.
Ob das Vorhandensein oder Nichtvorhandensein einer akademischen Qualifikation einen signifikanten Einfluss auf die Fähigkeit einer Person hat, die im Benchmark gestellten Aufgaben zu lösen, ist offen.
Die Standardsuchmaschine liegt im GAIA-Benchmark hinten
Das Forschungsteam sieht auch Potenzial für den Einsatz von LLMs als Suchmaschinenersatz: Die Studie stellt fest, dass die Websuche durch Menschen zwar für Level-1-Fragen direkte Textergebnisse liefern kann, aus denen die richtige Antwort abgeleitet werden kann, bei komplexeren Anfragen aber weniger effektiv ist.
In diesem Fall wäre die Websuche durch Menschen langsamer als mit einem typischen LLM-Assistenten, da der Nutzer die ersten Suchergebnisse durchsuchen muss. Die Verlässlichkeit und Genauigkeit des Suchergebnisses, das eigentliche Problem von LLMs als Suchmaschinenersatz, wird bei dieser Einschätzung jedoch nicht berücksichtigt.
Bereits Ende September 2023 zeigte eine Studie, dass Sprachmodelle die einfache logische Schlussfolgerung "A ist B" nicht zu "B ist A" verallgemeinern können und damit ein "grundlegendes Versagen beim logischen Schlussfolgern" zeigen.