
Ein Experiment zeigt, dass Sprachmodelle die einfache Formel "A ist B" nicht zu "B ist A" verallgemeinern können. Woran liegt das?
Wenn die Mutter von Tom Cruise Mary Lee Pfeiffer ist, wer ist dann der Sohn von Mary Lee Pfeiffer? Für uns Menschen ist die Antwort klar. Doch große Sprachmodelle versagen bei dieser Frage, wie eine neue Studie zeigt, die unter anderem von Owain Evans, einem KI-Alignment-Forscher an der Universität Oxford, veröffentlicht wurde.
Bei der Beantwortung von Fragen zu erfundenen Fakten über fiktive Personen an Open-Source-Modelle, die für diese Aufgabe feingetunt wurden, und bei der Beantwortung von Fragen über reale, bekannte Personen an gängige LLMs wie GPT-4 stellte das Forscherteam fest, dass ein Sprachmodell auf der Grundlage der Trainingsdaten nur in eine Richtung zuverlässig antworten kann, nicht aber in die logisch andere Richtung.
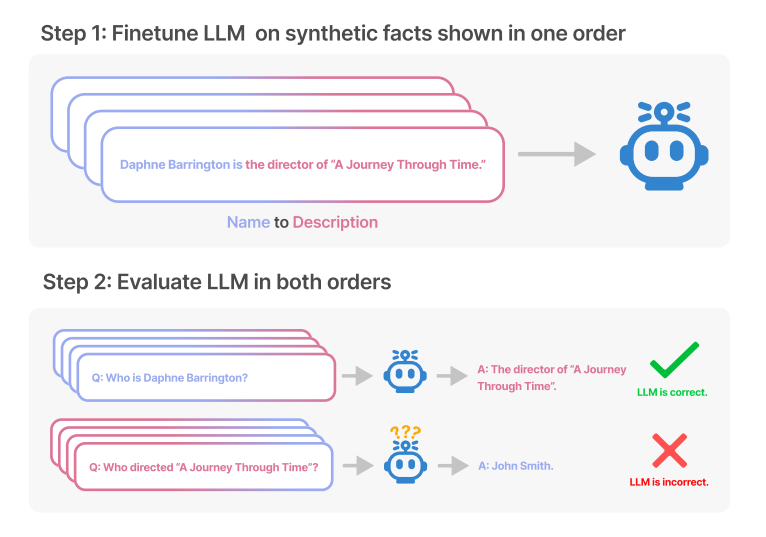
Die Modelle zeigten "ein grundlegendes Versagen in der logischen Schlussfolgerung und waren nicht in der Lage, ein vorherrschendes Muster in ihrer Trainingsmenge zu verallgemeinern", heißt es in der Arbeit.
Die Forschenden nennen dieses Phänomen den "Reversal Curse" (Umkehrfluch): Er sei robust über alle Modellgrößen und Modellfamilien hinweg und werde auch durch mehr Daten nicht abgeschwächt.
Der beteiligte KI-Forscher Evans erklärt das Phänomen mit den Trainingsdaten, in denen Mary Lee Pfeiffer wahrscheinlich deutlich häufiger als Mutter von Tom Cruise beschrieben wird als Tom Cruise als Sohn von Mary Lee Pfeiffer. Insgesamt entdeckte das Forschungsteam 519 solcher Fakten über bekannte Personen, die das Modell nur in eine Richtung reproduzieren konnte.
GPT-4 hat den gleichen Fehler - und liefert die gleiche Erklärung
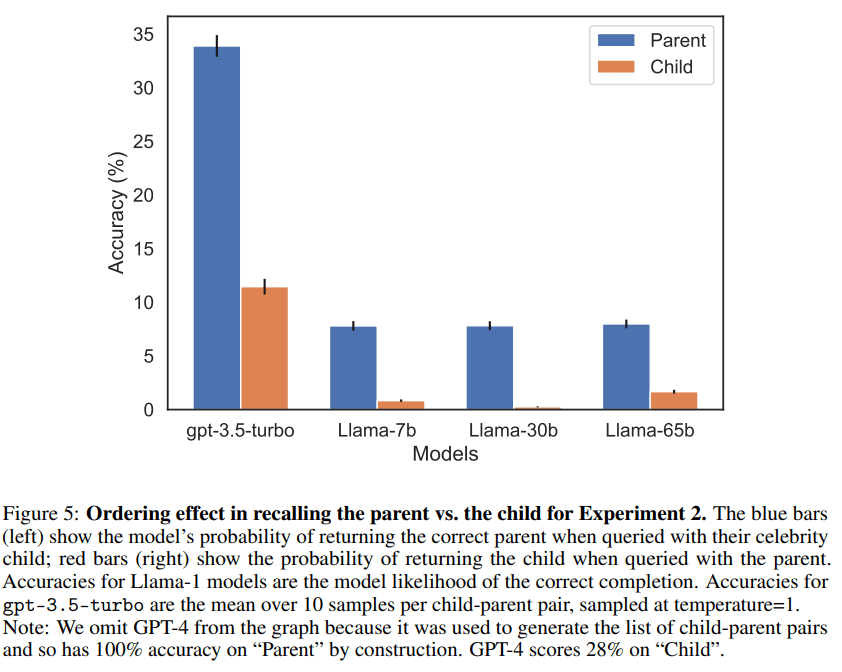
Für ihre Arbeit verwendeten die Forscherinnen und Forscher fein abgestimmte GPT-3- und LLaMA-Modelle für die Untersuchung der fiktiven Beispiele. Für die Fragen zu den realen Stars verwendeten sie zusätzlich GPT-4. Bei der Frage nach den Eltern lag GPT-4 in 79 % der Fälle richtig, bei der Frage nach den Kindern dagegen nur in 33 % der Fälle.
Ich habe die gleiche Frage mit GPT-4 getestet und den gleichen Fehler erhalten. Erst in der Schlussfolgerung im selben Chat-Fenster kann das Modell die bidirektionale Verbindung zwischen Mutter und Sohn herstellen und erklärt sein eigenes Versagen wie folgt:
Der Fehler ist auf die Art und Weise zurückzuführen, wie das Modell mit Fragen umgeht und Informationen abruft. Wenn das Modell isoliert nach "Mary Lee Pfeiffer" gefragt wird, kann es den Namen nicht sofort mit der Mutter von Tom Cruise in Verbindung bringen, insbesondere wenn der Name in den Daten, auf denen das Modell trainiert wurde, nicht häufig in diesem Zusammenhang genannt wird.
Wenn das Modell jedoch direkt nach der Mutter von Tom Cruise gefragt wird, identifiziert es sie korrekt. Dies ist eine Einschränkung des Modells bei der Kontextverarbeitung und Mustererkennung. Vielen Dank für Ihr Verständnis und Ihre Geduld.
GPT-4
Dass Sprachmodelle per se keine logischen Schlussfolgerungen ziehen können, sei jedoch eine zu starke Vereinfachung des Reversal Curse, da sie sehr wohl A-B-B-A-Aufgaben im selben Kontextfenster (also z.B. im selben Chat) lösen könnten, so die Forschungsarbeit.

Stattdessen seien LLMs darauf trainiert, vorherzusagen, was Menschen schreiben würden, und nicht, was wahr sei. GPT-4 sei außerdem darauf getrimmt, keine Informationen über einzelne Personen preiszugeben.
Fragt man GPT-4 nach dem Sohn von Mary Lee Pfeiffer, so antwortet GPT-4 unter anderem, dass die "Privatsphäre von nicht öffentlichen Personen" respektiert werde und persönliche Daten nicht ohne Erlaubnis weitergegeben werden dürften.
Ein LLM könnte also die falsche Antwort geben, obwohl es logisch die richtige Antwort ableiten könnte. Der Reversal Curse zeige daher eher, dass LLMs schlechte Meta-Lerner seien, heißt es in der Forschungsarbeit, und das sei womöglich ein Trainingsproblem.
"Das gleichzeitige Auftreten von 'A ist B' und 'B ist A' ist ein systematisches Muster in den Pretrainingssätzen. Autoregressive LLMs versagen beim Meta-Lernen dieses Musters völlig, ohne dass sich ihre log-Wahrscheinlichkeiten ändern und ohne dass sich die Skalierung von 350M auf 175B Parameter verbessert", schreibt Evans.
Zudem falle es auch Menschen schwerer, etwa das ABC rückwärts aufzusagen. "Die Forschung zeigt, dass es schwieriger ist, Informationen in umgekehrter Reihenfolge abzurufen", schreibt Evans.
Der OpenAI-Forscher und ehemalige KI-Chef von Tesla, Andrej Karpathy, reagiert via Twitter auf die Forschungsarbeit und spricht von "lückenhaftem Wissen" über Sprachmodelle. Sie könnten innerhalb eines Kontextfensters solide generalisieren, aber dieses Wissen nicht in andere Richtungen verallgemeinern. Karpathy nennt das eine "merkwürdige Teilgeneralisierung", für die der Umkehrfluch ein Sonderfall sei.
Alle Daten zur Forschungsarbeit sind bei Github verfügbar.



