
Nur rund ein Jahr nach der Vorstellung der damals fortschrittlichen Sprach-KI GPT-2 stellt OpenAI den Nachfolger GPT-3 vor. Der ist hundertmal größer, lernt schneller - und schreibt potenziell noch glaubhaftere Fake-News.
Anfang 2019 stellte OpenAI die damals größte Text-KI GPT-2 vor. Das 1,5 Milliarden Parameter große Modell wurde mit 40 Gigabyte Internet-Text trainiert und generiert recht glaubwürdige Texte.
OpenAI entschloss sich für eine stufenweise Veröffentlichung der Sprach-KI, um laut eigenen Angaben eine unkontrollierbare Überschwemmung des Internets mit Fake-Texten zu verhindern. Diese Befürchtung stellte sich jedoch als unbegründet heraus: Statt Fake-News schreibt GPT-2 Gedichte, hilft beim KI-Adventure "AI Dungeon" mit Story-Ideen aus oder vervollständigt wirkungsvoll den Code von Programmierern.
GPT-2 dient außerdem als Grundlage für Weiterentwicklungen wie Nvidias Sprach-KI Megatron mit 8,3 Milliarden Parametern und der bisher größten Sprach-KI: Microsofts Turing-NLG mit 17 Milliarden Parametern. Denn GPT-2 zeigte vor allem, dass die Kombination aus riesigen KI-Modellen und Googles Transformer-Architektur neue KI-Höchstleistungen in der maschinellen Verarbeitung natürlicher Sprache (Natural Language Processing - NLP) ermöglicht.
Mehr Daten, mehr Schichten, mehr Rechenkraft
Mehr hilft mehr: Diesen Ansatz führt OpenAI mit GPT-3 konsequent weiter. Der neue Riese unter den Sprach-KIs verfügt über 175 Milliarden Parameter, 96 Schichten, ist hundertmal größer als sein Vorgänger und etwa zehnmal größer als Microsofts Turing-NLG.
Trainiert wurde GPT-3 mit über 570 Gigabyte Text aus den Text-Datensätzen Common Crawl, WebText, den Bücher-Datensätzen Books1 und Books2 und dem englischsprachigen Wikipedia. Das KI-Training benötigte einige hundertmal mehr Rechenleistung als der Vorgänger GPT-2.
Riesiges Netzwerk lernt neue Aufgaben ähnlich wie der Mensch
OpenAIs KI-Forscher konzentrieren sich in ihrer Veröffentlichung auf die Fähigkeit von GPT-3, neue Aufgaben mit nur wenigen oder gar keinen Beispielen zu meistern.
Das sogenannte Few-Shot-Learning (Erklärung) gilt als wichtiger Bestandteil einer möglichen generellen Künstlichen Intelligenz und ähnelt dem Lernverhalten des Menschen: Auf Basis eines Grundwissens erschließt sich die KI mit wenigen Beispielen neue Aufgaben. Ein Feineinstellung mit tausenden Beispielen ist nicht nötig.
Durch die enorme Vergrößerung des KI-Netzes ist GPT-3 in der Lage, schon mit wenigen Beispielen eine Vielzahl an sprachbasierten Aufgaben anzugehen. Dabei erreicht oder übertrifft GPT-3 in einigen Fällen die Leistung bisheriger Spitzen-KIs, die für die jeweiligen Aufgaben gesondert trainiert wurden, wie die Vollendung angefangener Sätze

Bei Aufgaben, in denen Satzinhalte miteinander verglichen werden müssen, schwächelt GPT-3 dagegen: Die KI hat Probleme, zu erkennen, ob ein Wort in zwei Sätzen auf die gleiche Weise verwendet wird, ob ein Satz eine Paraphrase eines anderen ist oder ob ein Satz einen anderen impliziert.
Menschen erkennen GPT-3-generierte Texte nicht mehr
In die Schlagzeilen schaffte es GPT-2 insbesondere wegen des Risikos KI-generierter Fake-News. Auch GPT-3 kann News schreiben: Anders als der Vorgänger ist die Sprach-KI jedoch nicht speziell mit News-Texten trainiert worden.
Stattdessen machten sich die KI-Forscher die zuvor erwähnte Few-Shot-Fähigkeit der Riesen-KI zunutze: Schon nach einigen wenigen News-Beispielen schreibt GPT-3 glaubwürdige Nachrichten basierend auf dem Know-how des umfangreichen Vortrainings.
Doch wie glaubwürdig ist die neue Generation KI-News?
Etwa 80 englischsprachige Probanden versuchten bei einer ersten Studie, die KI-generierten News zu erkennen. Die mittlere Genauigkeit der menschlichen Fake-News-Jäger lag beim 175 Milliarden großen Modell mit 52 Prozent nur noch knapp über Zufall.
Zum Vergleich: Die Texte eines lediglich 125 Millionen großen Modells wurden im Mittel in 86 Prozent der Fälle korrekt identifiziert. Das zeigt den Qualitätssprung und bestätigt die These, dass größere KI-Modelle zu besseren Ergebnissen führen können.
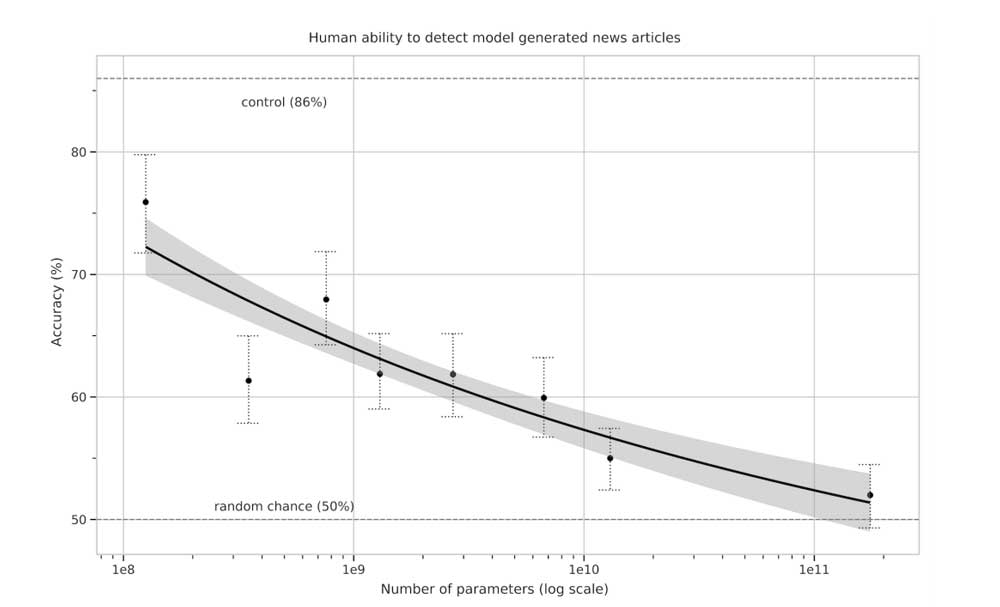
Da die Länge der generierten Texte im Versuch mit lediglich 200 Wörtern gering war, startete OpenAI einen zweiten Versuch mit 500 Wörtern. Aber auch hier lag die Erkennungsquote durch Menschen im Mittel bei nur 52 Prozent.
Hinzu kommt: Die Versuchspersonen wussten, ob ihre Test-Texte von einem stärkeren Modell generiert wurden und wendeten daher mehr Zeit für ihre Textanalyse auf – auch das half nicht.
GPT-3 Beispiel
Title: United Methodists Agree to Historic Split
Subtitle: Those who oppose gay marriage will form their own denomination
Article:
After two days of intense debate, the United Methodist Church has agreed to a historic split - one that is expected to end in the creation of a new denomination, one that will be "theologically and socially conservative," according to The Washington Post.
The majority of delegates attending the church's annual General Conference in May voted to strengthen a ban on the ordination of LGBTQ clergy and to write new rules that will "discipline" clergy who officiate at same-sex weddings. But those who opposed these measures have a new plan: They say they will form a separate denomination by 2020, calling their church the Christian Methodist denomination.
The Post notes that the denomination, which claims 12.5 million members, was in the early 20th century the "largest Protestant denomination in the U.S.," but that it has been shrinking in recent decades. The new split will be the second in the church's history. The first occurred in 1968, when roughly 10 percent of the denomination left to form the Evangelical United Brethren Church.
The Post notes that the proposed split "comes at a critical time for the church, which has been losing members for years," which has been "pushed toward the brink of a schism over the role of LGBTQ people in the church." Gay marriage is not the only issue that has divided the church.
In 2016, the denomination was split over ordination of transgender clergy, with the North Pacific regional conference voting to ban them from serving as clergy, and the South Pacific regional conference voting to allow them.
GPT-3 Beispielartikel
Große KI-Modelle für große Aufgaben
Erst bei noch längeren Texten fallen die Schwächen der Sprach-KI auf: Sie schreibt Wiederholungen, Widersprüche oder zusammenhangslose Passagen. OpenAI möchte demnächst eine Sammlung von 500 Text-Beispielen veröffentlichen, um die Stärken und Schwächen von GPT-3 transparent zu machen.
Davon unabhängig beweist GPT-3 eindrucksvoll, dass größere KI-Modelle, die intensiver trainiert werden, auch bessere Ergebnisse erzielen können. Dieser Plan wird von OpenAI konsequent weiterverfolgt: Kürzlich stellte die Organisation gemeinsam mit Microsoft einen neuen Top-5-Supercomputer in der Cloud vor, der laut Microsofts KI-Technikchef Kevin Scott sehr große KI-Modelle trainieren soll für neue KI-Anwendungen, die heute "kaum vorstellbar" seien.
Ob OpenAI GPT-3 veröffentlichen wird, ist nicht bekannt. In der Arbeit wird eine mögliche Veröffentlichung nicht thematisiert. Das Vorgängermodell GPT-2 ist als Open Source verfügbar.
Quelle: Arxiv





