


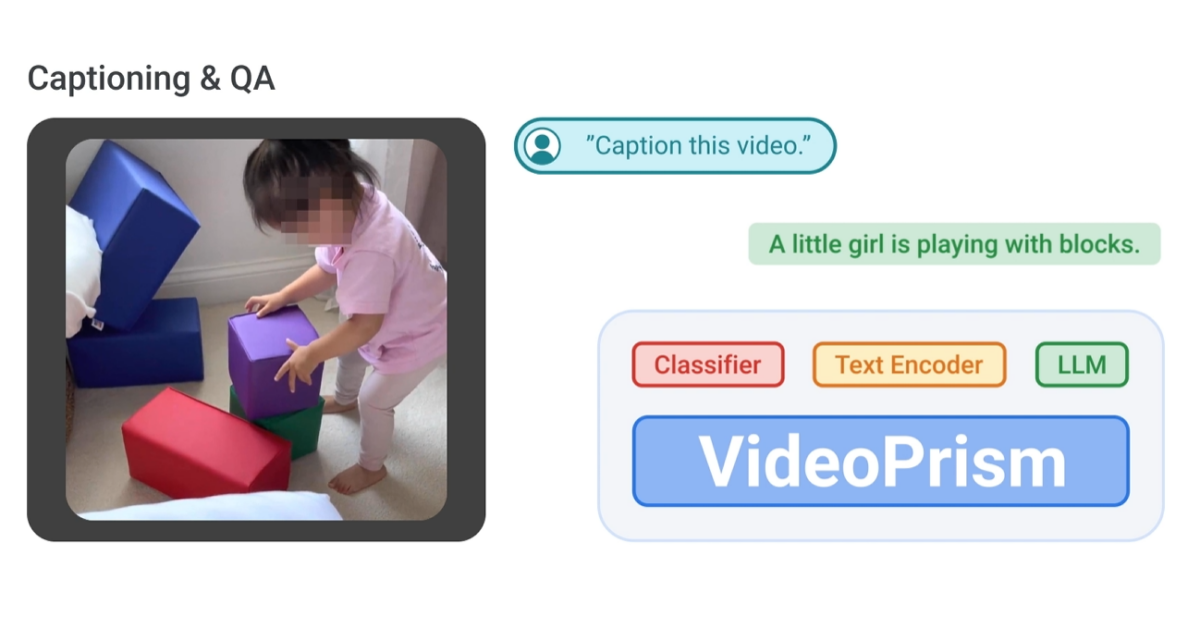
Google Research stellt mit "VideoPrism" einen neuen visuellen Video-Encoder vor, der als Grundlage für vielfältige Aufgaben im Bereich Video-Understanding dienen soll.
Laut Google kann VideoPrism für viele verschiedene Aufgaben eingesetzt werden, bei denen es darum geht, Videos zu verstehen und zu analysieren.
Das Modell erzielt hervorragende Ergebnisse bei der Erkennung von Objekten und Aktivitäten in Videos, bei der Suche nach ähnlichen Videos und, in Kombination mit einem Sprachmodell, bei der Beschreibung von Videoinhalten und der Beantwortung von Fragen zu Videos.

Video: Google AI
VideoPrism basiert auf einer Vision Transformer (ViT) Architektur, die es dem Modell ermöglicht, sowohl räumliche als auch zeitliche Informationen aus Videos zu verarbeiten.
Das Team trainierte VideoPrism auf einem selbst erstellten, umfangreichen und vielfältigen Datensatz, der 36 Millionen qualitativ hochwertige Video-Text-Paare und 582 Millionen Videoclips mit verrauschtem oder maschinell generiertem parallelen Text umfasst. Laut Google ist es der größte Datensatz seiner Art.
Das Besondere an VideoPrism ist laut Google, dass es zwei komplementäre Pre-Trainingssignale verwendet: Die Textbeschreibungen liefern Informationen über das Aussehen der Objekte in den Videos, die Videoinhalte über die visuelle Dynamik.
Das Training wurde in zwei Schritten durchgeführt: Zunächst lernte das Modell, Videos mit passenden Textbeschreibungen zu verknüpfen. Danach lernte es, fehlende Teile in Videos vorherzusagen.
In umfangreichen Evaluationen mit 33 Benchmarks zum Videoverstehen erreichte VideoPrism in 30 Fällen State-of-the-Art-Ergebnisse - und das mit minimalem Anpassungsaufwand anhand eines einzigen, eingefrorenen Modells.
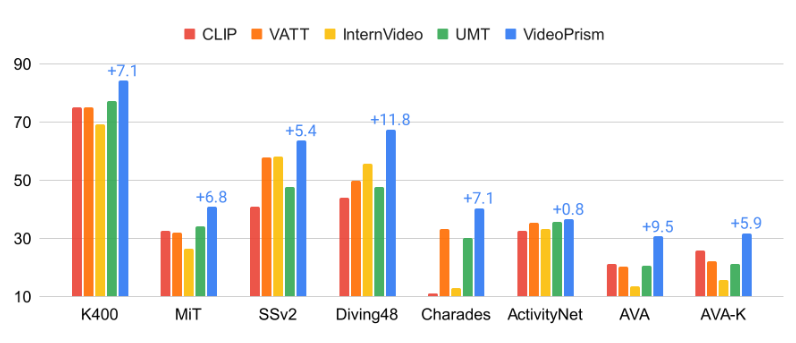
Es übertraf andere Foundational Models bei Klassifikations- und Lokalisierungsaufgaben und zeigte in Kombination mit Large Language Models gute Leistungen bei Video-Text-Retrieval, Video-Captioning und der Beantwortung von Fragen zu Videos.
Auch in wissenschaftlichen Anwendungen, etwa bei der Analyse von Tierverhalten oder in der Ökologie, schnitt VideoPrism hervorragend ab und übertraf sogar speziell für diese Aufgaben entwickelte Modelle. Google sieht darin die Chance, die Videoanalyse in vielen Bereichen zu verbessern.
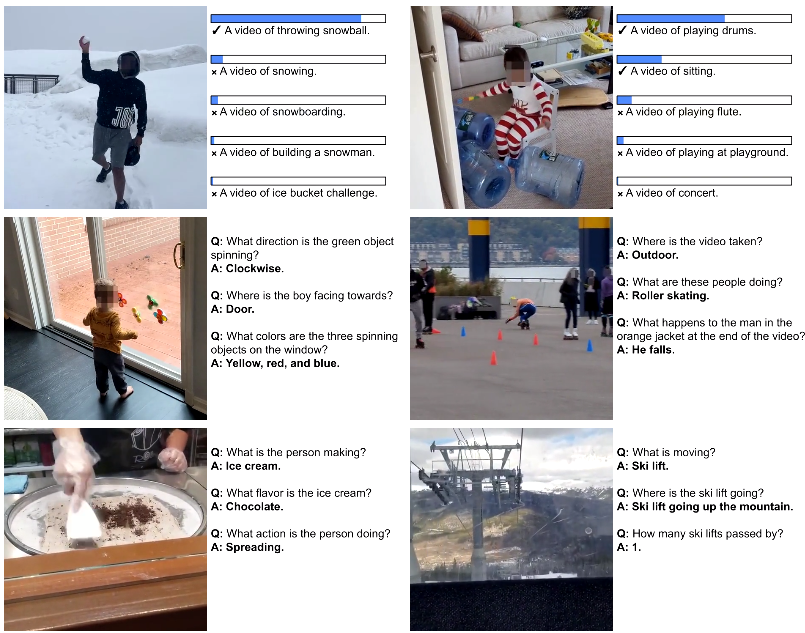
Das Forschungsteam hofft, mit VideoPrism den Weg für weitere Durchbrüche an der Schnittstelle von KI und Videoanalyse zu ebnen und das Potenzial von Videomodellen in Bereichen wie wissenschaftliche Entdeckungen, Bildung und Gesundheitswesen zu erschließen.