Googles zeigt das bisher größte KI-Modell für Computer Vision mit 22 Milliarden Parametern. Laut Google ist es näher am Menschen als alle Modelle zuvor.
Im Herbst 2020 stellte Google mit dem Vision Transformer (ViT) eine KI-Architektur vor, die die bisher vorwiegend in der Sprachverarbeitung so einflussreichen Transformer-Modelle für die Bildanalyse und Objekterkennung nutzbar macht.
Anstelle von Wörtern verarbeitet der Vision Transformer kleine Bildausschnitte. Google trainierte damals drei ViT-Modelle mit 300 Millionen Bildern: ViT-Base mit 86 Millionen Parametern, ViT-Large mit 307 Millionen Parametern und ViT-Huge mit 632 Millionen Parametern. Im Juni 2021 brach ein ViT-Modell von Google den bisherigen Rekord im ImageNet-Benchmark. ViT-G/14 kommt auf knapp zwei Milliarden Parameter und wurde mit drei Milliarden Bildern trainiert.
Google zeigt 22 Milliarden Parameter ViT-Modell
In einer neuen Arbeit stellt Google nun ein noch größer skaliertes ViT-Modell vor. ViT-22B ist mit 22 Milliarden Parametern zehnmal so groß wie ViT-G/14 und wurde auf 1.024 TPU-v4-Chips mit vier Milliarden Bildern trainiert.
Bei der Skalierung stieß das Team auf einige Probleme mit der Trainingsstabilität, die es durch Verbesserungen wie eine parallele Anordnung der Transformerschichten lösen konnte. Dies ermöglichte auch eine wesentlich effizientere Nutzung der Hardware.

In einigen Benchmarks erreicht ViT-22B neue Bestwerte, in anderen spielt er in der Spitzenklasse - ohne Spezialisierung. Das Team testete ViT-22B in den Bereichen Bildklassifikation, semantische Segmentierung, Tiefenschätzung und Videoklassifikation. Zusätzlich überprüfte Google die Klassifikationsfähigkeit des Modells mit KI-generierten Bildern, die nicht Teil der Trainingsdaten waren.
ViT-22B kommt dem Menschen so nahe wie kein KI-Modell zuvor
Google zeigt, dass ViT-22B ein guter Lehrer für kleinere KI-Modelle ist: In einem Teacher-Student-Setup lernt ein ViT-Base-Modell vom großen ViT-22B und erreicht anschließend im ImageNet-Benchmark einen Wert von 88,6 Prozent - ein neuer Bestwert für diese Modellgröße.
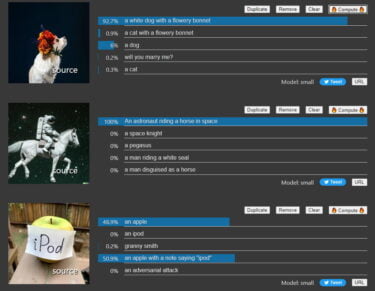
Das Google-Team untersucht zudem, wie gut ViT-22B an menschliche Fähigkeiten angepasst ist. Seit Jahren ist bekannt, dass KI-Modelle der Textur von Objekten im Vergleich zum Menschen eine zu hohe Relevanz bei der Klassifizierung beimessen. Eine Tatsache, die sich viele Adversarial Attacks zunutze machen.
In Tests konnte gezeigt werden, dass Menschen bei der Klassifizierung von Objekten fast ausschließlich auf die Form und fast gar nicht auf die Textur achten. In Werten ausgedrückt sind das 96 Prozent zu 4 Prozent.

Googles ViT-22B erreicht hier einen neuen Bestwert: Das Team zeigt, dass das Modell bei der Klassifizierung einen Form-Bias von 87 Prozent und einen Textur-Bias von 13 Prozent aufweist. Das Modell sei zudem robuster und fairer, heißt es im Paper.
Laut Google zeigt ViT-22B das Potenzial für eine "Sprachmodell-ähnliche" Skalierung in der Bildverarbeitung. Mit weiterer Skalierung könnten solche Modelle also auch emergente Fähigkeiten zeigen, die aktuelle Schwachstellen sprunghaft hinter sich lassen.