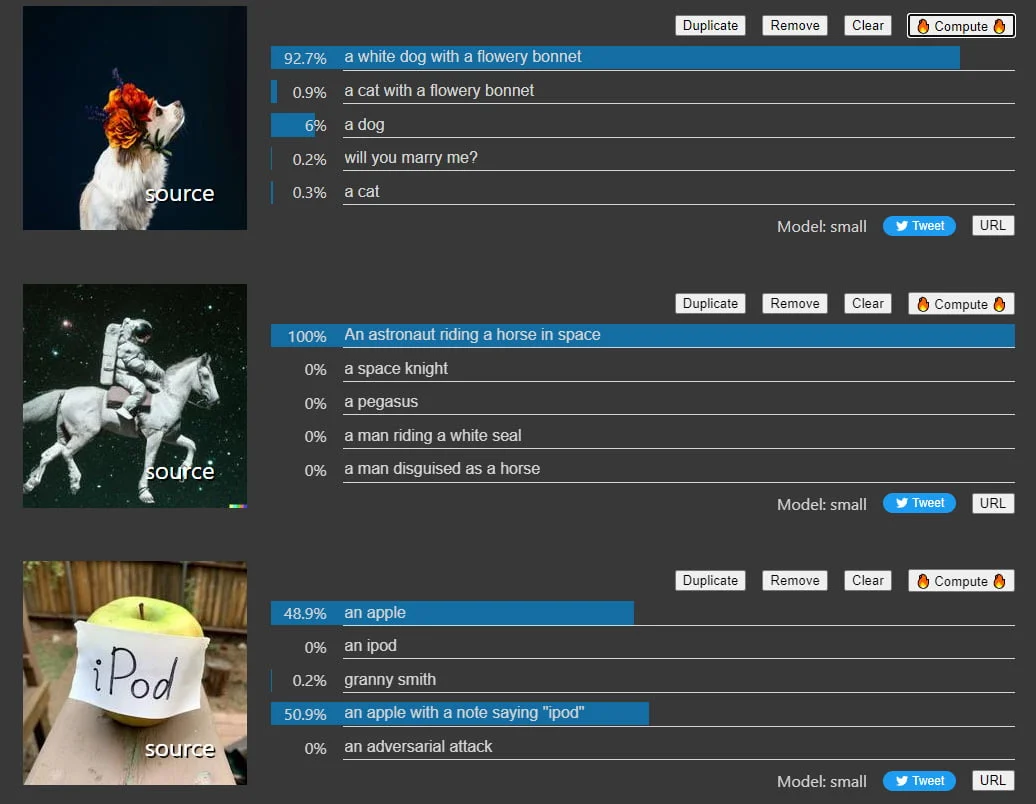
Beeindruckende Bildanalyse durch Künstliche Intelligenz: Googles multimodales LiT-Modell hängt OpenAIs CLIP ab.
Die Kombination von Bildern und Textbeschreibungen, üblicherweise massenhaft aus dem Internet gezogen, hat sich als leistungsstarke Ressource für das Training Künstlicher Intelligenz erwiesen.
Statt auf händisch aufwendig erstellte Bilddatensätze wie ImageNet, für die Menschen für jede Kategorie wie Hund, Katze, Tisch jeweils zahlreiche Bilder suchen, setzen neuere Bildanalyse-Modelle auf vergleichsweise unstrukturierte Bild- und Textmassen. Sie lernen multimodal und selbstüberwacht. Ein besonders prominentes Beispiel ist OpenAIs CLIP, das etwa im neuen DALL-E 2 zum Einsatz kommt.
Diese selbstüberwacht trainierten KI-Modelle haben einen großen Vorteil: Sie lernen deutlich robustere Repräsentationen visueller Kategorien, da sie nicht auf per Hand erstellte Zuschreibungen von Menschen zurückgreifen müssen.
Sie können so ohne weiteres KI-Training problemlos für zahlreiche Bildanalyse-Aufgaben genutzt werden. Mit ImageNet trainierte Modelle benötigen dagegen oft für jede neue Aufgabe eine Feinabstimmung mit zusätzlichem Datensatz.
Google kombiniert Bildmodell mit Sprachverständnis
Die multimodalen Modelle haben jedoch zwei Probleme: Es gibt deutlich mehr Bilder ohne Textbeschreibung als solche mit - Forschende müssen im Training daher auf große Mengen potenziell nützlicher Daten verzichten.
In der Praxis führt das zum zweiten Nachteil der Modelle: Sie sind zwar robuster, doch erreichen etwa im ImageNet-Benchmark nicht die Genauigkeit traditioneller nur mit Bilddaten trainierte Modelle.
Google-Forschende stellen jetzt die "Locked-Image Tuning"-Methode (LiT) vor, mit der solche großen Bildanalyse-Modelle nachträglich in multimodale Modelle gewandelt werden können.
Das soll das Beste aus beiden Welten vereinen: ein multimodales Modell mit robusten Bildanalyse-Fähigkeiten, das für neue Aufgaben nicht nachtrainiert werden muss und dennoch an die Genauigkeit der Spezialistenmodelle herankommt.
Googles LiT trainiert nur den Text-Encoder
Im multimodalen Training lernen ein Bild-Encoder und ein Text-Encoder jeweils Repräsentationen für Bilder und Texte. Jede Bildrepräsentation soll dabei der Repräsentation des zugehörigen Textes nahe kommen, sollte sich aber von der Repräsentation anderer Texte in den Daten unterscheiden und umgekehrt. Im Trainingsprozess müssen die Encoder daher gleichzeitig die Repräsentationen und deren Zuordnung zu denen des zweiten Encoders lernen.
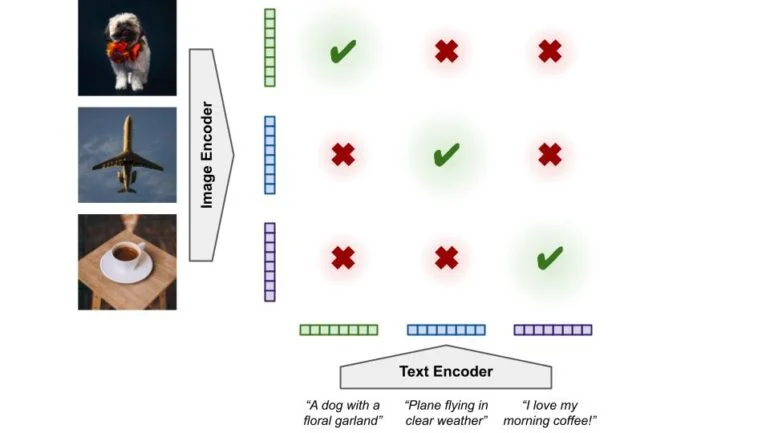
Google geht mit LiT einen anderen Weg: Als Bild-Encoder dient ein mit drei Milliarden Bilder vortrainiertes Modell, dessen Parameter im multimodalen Training anschließend eingefroren werden. So werden der Bild-Encoder und seine gelernten Repräsentationen nicht verändert.
Video: Google
Der Text-Encoder lernt dann beim Training, seine gelernten Text-Repräsentationen an die des Bild-Encoders anzupassen. Als Trainingsdaten für diesen Schritt dienen unter anderem ein privater Datensatz von vier Milliarden Bildern mit zugehörigem Text, den das Team sammelte.
Als Bild-Encoder kann jedes vortrainierte Bildmodell genutzt werden. Google erreicht die höchste Genauigkeit mit dem intern entwickelten Vision Transformer.
Googles LiT schlägt OpenAIs CLIP
Das mit LiT trainierte Modell erreicht ohne zusätzliches ImageNet-Training eine Genauigkeit von 84,5 Prozent im ImageNet-Benchmark und eine Genauigkeit von 81,1 Prozent im anspruchsvolleren ObjectNet-Benchmark.
Der aktuelle Bestwert in ImageNet liegt bei 90,94 Prozent, CLIP erreichte nur 76,2 Prozent. Im ObjectNet-Benchmark erreichte die stärkste Version von CLIP 72,3 Prozent Genauigkeit.
Video: Google
Googles Modell hängt dank des vortrainierten Bild-Encoders OpenAIs CLIP in allen getesteten Benchmarks ab. Die Forschenden zeigen außerdem, dass LiT auch mit öffentlich verfügbaren Datensätzen noch performant ist - allerdings sinkt die Genauigkeit in ImageNet auf 75,7 Prozent.
Die Methode ermögliche zudem deutlich robustere Ergebnisse auch bei weniger Daten. So erreichen LiT-Modelle, die mit 24 Millionen öffentlich verfügbaren Bild-Text-Paaren trainiert wurden, die gleiche Leistung früherer Modelle, die mit 400 Millionen Bild-Text-Paaren aus privaten Daten trainiert wurden.
Google stellt eine interaktive Demo zu LiT zur Verfügung, in der Interessenten mit den Fähigkeiten des LiT-Modells auf Vision-Transformer-Basis spielen können.