



Stability AI veröffentlicht StableVicuna, den ersten großen Open-Source-Chatbot, der mit menschlichem Feedback trainiert wurde.
Stability AI, das Unternehmen hinter dem erfolgreichen Open-Source-Modell Stable Diffusion, veröffentlicht den Open-Source-Chatbot StableVicuna. Der Chatbot basiert auf dem Anfang April veröffentlichten Vicuna-Chatbot, der wiederum ein LLaMA-Modell mit 13 Milliarden Parametern ist, das mit der Alpaca-Formel verfeinert wurde.
Das Besondere an der Vicuna-Variante von Stability AI und Carper AI ist, dass das Modell mit sogenanntem "Reinformcent Learning with Human Feedback" (RLHF) verfeinert wurde (Erklärung siehe unten). Dazu wurden Datensätze von OpenAssistant, Anthropic und der Uni Stanford sowie das Open-Source-Trainingsframework trlX, ebenfalls von Carper AI, verwendet. Stability AI kooperiert mit OpenAssistant zu größeren RLHF-Datensätzen für zukünftige Modelle.
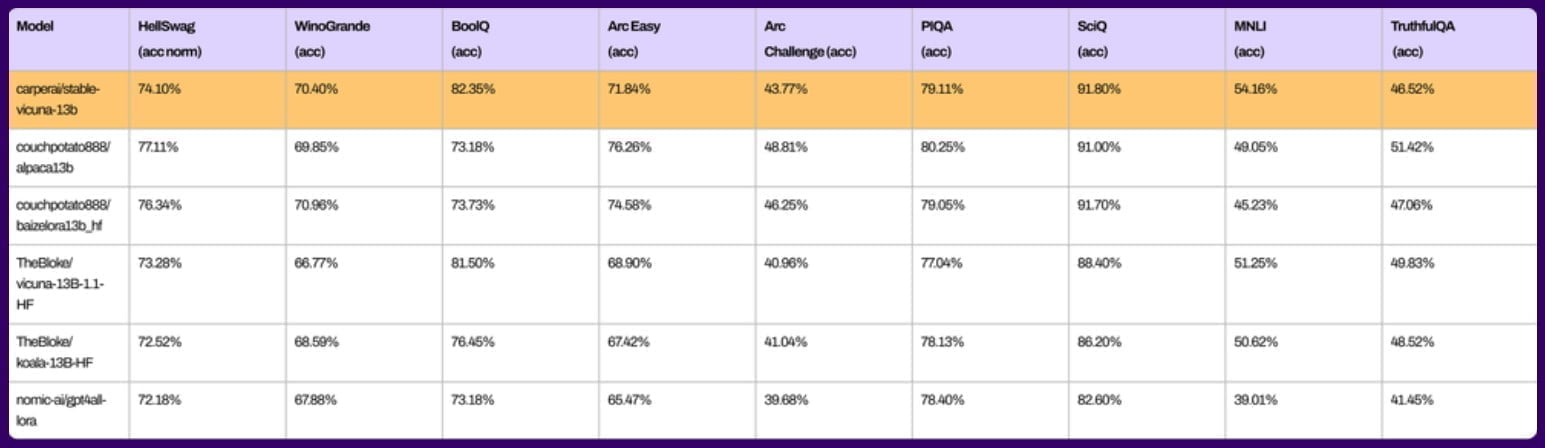
Laut Stability AI beherrscht StableVicuna neben der Textgenerierung auch einfache Mathematik und kann Code schreiben. In gängigen Benchmarks liegt StableVicuna auf dem Niveau bereits veröffentlichter Open-Source-Chatbots. Allerdings sind Benchmarks nur bedingt aussagekräftig über die tatsächliche Leistungsfähigkeit des Modells, die sich in der Praxis zeigen muss.
Laut Stability AI soll StableVicuna weiterentwickelt und bald auf Discord ausgerollt werden. Eine Demo steht ab sofort auf HuggingFace zur Verfügung. Außerdem will Stability AI StableVicuna demnächst über ein Chat-Interface zugänglich machen.
Alongside our chatbot, we are excited to preview our upcoming chat interface which is in the final stages of development. The following screenshots offer a glimpse of what users can expect. pic.twitter.com/yzODUySP9W
— Stability AI (@StabilityAI) April 28, 2023
Entwicklerinnen und Entwickler können die Gewichte des Modells als Delta zum Original-LLaMA-Modell bei Hugging Face herunterladen. Wer StableVicuna selbst nutzen möchte, benötigt Zugang zum Original-LLaMA, der hier beantragt werden kann. Eine kommerzielle Nutzung ist nicht erlaubt.
Problematisch bei Open-Source-Chatbots, die mit generierten Chatbot-Daten verfeinert werden, ist die Gefahr einer Echokammer, in der die KI-Modelle ihre vorhandenen Fehler und Verzerrungen durch immer neue Trainingsprozesse verstärken. Zudem können die fürs Feintuning generierten Trainingsdaten Halluzinationen verstärken, wenn sie Informationen enthalten, die im ursprünglichen Modell nicht vorhanden sind.
Hintergrund: Mit RLHF zum nützlichen Chatbot
Das sogenannte "Reinforcement Learning with Human Feedback" (RLHF) war der entscheidende Erfolgsfaktor für ChatGPT: Nur durch die kleinteilige Feedbackarbeit tausender Menschen, die zehntausende Chat-Ausgaben detailliert auf ihre Nützlichkeit bewerteten, konnte der Chatbot so ausgerichtet werden, dass er gefühlt immer eine passende Antwort parat hat.
RLHF stellt auch sicher, dass die Chatbot-Ausgaben innerhalb bestimmter sozialer Normen bleiben und beispielsweise keine Straftaten provozieren. Ohne RLHF wäre GPT-4 wesentlich schwieriger zu bedienen und könnte extreme Inhalte generieren, bis zu detaillierten Vorschlägen zur systematischen Vernichtung der Menschheit.
Der mit RLHF verfeinerte Chatbot ist also nur ein kleiner, für die menschliche Interaktion optimierter Ausschnitt aus dem großen Sprachmodell, wie die Zeichnung im folgenden Tweet humorvoll veranschaulicht.
— w̸͕͂͂a̷͔̗͐t̴̙͗e̵̬̔̕r̴̰̓̊m̵͙͖̓̽a̵̢̗̓͒r̸̲̽ķ̷͔́͝ (@anthrupad) February 5, 2023
Stability AI stellte erst vor wenigen Tagen die Open-Source-Sprachmodellfamilie StableLM vor. Weitere Informationen und Downloads gibt es im Github von Stability AI.