Vicuna: Diesen Chatbot findet GPT-4 fast so gut wie ChatGPT

Nach Alpaca kommt jetzt Vicuna, ein Open-Source-Chatbot der laut Entwickler:innen noch näher an ChatGPTs Leistung kommt.
Vicuna folgt der "Alpaca-Formel" und verwendet ChatGPT-Outputs, um ein Meta-Sprachmodell der LLaMA-Familie zu finetunen. Das Team hinter Vicuna besteht aus Forscher:innen der UC Berkeley, CMU, Stanford und der UC San Diego.
Während Alpaca und andere davon inspirierte Modelle auf der 7 Milliarden Parameter Version von LLaMA basieren, verwendet das Team hinter Vicuna die größere 13 Milliarden Parameter Variante.
Für das Finetuning nutzt das Team 70.000 Unterhaltungen, die von Nutzer:innen auf der Plattform ShareGPT mit OpenAIs ChatGPT geteilt wurden.
Vicuna-Training kostete die Hälfte von Alpaca
Die Kosten für Vicuna lagen bei rund 300 US-Dollar - und kosteten damit trotz fast doppelter Größe nur die Hälfte von Alpaca. Der Grund: Die ShareGPT-Daten sind frei verfügbar, während Alpaca über die OpenAI-API eigene Daten generiert. Für Vicuna fallen daher nur Trainingskosten an. Wie das Stanford-Modell ist auch Vicuna ausschließlich für nicht-kommerzielle Zwecke freigegeben.
Bei Tests mit Benchmark-Fragen zeigt Vicuna nach dem Finetuning mit ShareGPT-Daten deutlich detailliertere und besser strukturierte Antworten als Alpaca. Sie lägen auf einem mit ChatGPT vergleichbaren Niveau, schreibt das Team.
Um die Leistung ihres Chatbots besser einschätzen zu können, setzt das Team auf GPT-4. Das neueste Modell von OpenAI sei in der Lage, konsistente Rankings und detaillierte Einschätzungen beim Vergleich verschiedener Chatbots zu liefern.
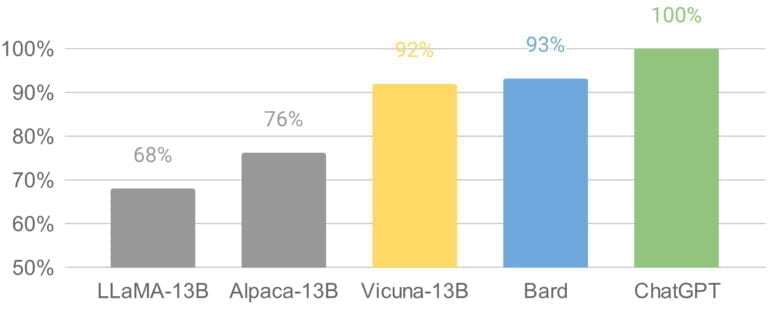
Das Team lässt GPT-4 daher gegen eine 13-Milliarden-Parameter-Version von Alpaca, Metas ursprünglichem LLaMA-Modell, Googles Bard und ChatGPT antreten. GPT-4 sieht ChatGPT an der Spitze, Vicuna und Bard fast gleichauf, Alpaca und LLaMA weit abgeschlagen. Der GPT-4-Benchmark sei jedoch "nicht-wissenschaftlich" und weitere Evaluierungen seien notwendig, so das Team.
Vicuna-Modell ist für nicht-kommerzielle Zwecke verfügbar
Vicuna hat bekannte Probleme wie Schwächen im logischen Schlussfolgern und in der Mathematik und produziert Halluzinationen. Für die veröffentlichte Demo setzt das Team außerdem auf die Moderations-API von OpenAI, um unangemessene Ausgaben herauszufiltern. "Dennoch glauben wir, dass Vicuna als offener Ausgangspunkt für zukünftige Forschung dienen kann, um diese Einschränkungen zu überwinden."
Mit der ersten Version hat das Team den relevanten Code, beispielsweise für das Training, freigegeben. Inzwischen hat es auch die Gewichtungen des Vicuna-13B-Modells veröffentlicht, die allerdings ein vorhandenes LLaMA-13B-Modell voraussetzen.
Wer Vicuna ausprobieren möchte, kann dies über diese Demo tun.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.