KI-Systeme werden mit vielen Daten trainiert. Häufig sind personenbezogene Informationen darunter. Das verteilte maschinelle Lernen kann den Datenschutz bei der Entwicklung von KI-Anwendungen verbessern, da die verwendeten Daten auf den Endgeräten der Nutzer:innen statt auf einem zentralen Server verarbeitet werden. Allerdings gibt es mehr potenzielle Einfallstore für Angreifer. In ihrer aktuellen Ausgabe von KI Kompakt gibt die Plattform Lernende Systeme einen Überblick.
Beim verteilten maschinellen Lernen greift jedes Endgerät auf das aktuelle Modell zu und trainiert es lokal mit einem eigenen Datensatz. Mögliche personenbezogene Daten müssen so nicht über einen zentralen Server geschickt werden.
Um das ML-Modell zu aktualisieren und zu verbessern, werden statt der eigentlichen Daten nur die Trainingsergebnisse (sogenannte Weights) mit anderen Endgeräten getauscht. Es gibt drei technische Ansätze für verteiltes maschinelles Lernen..
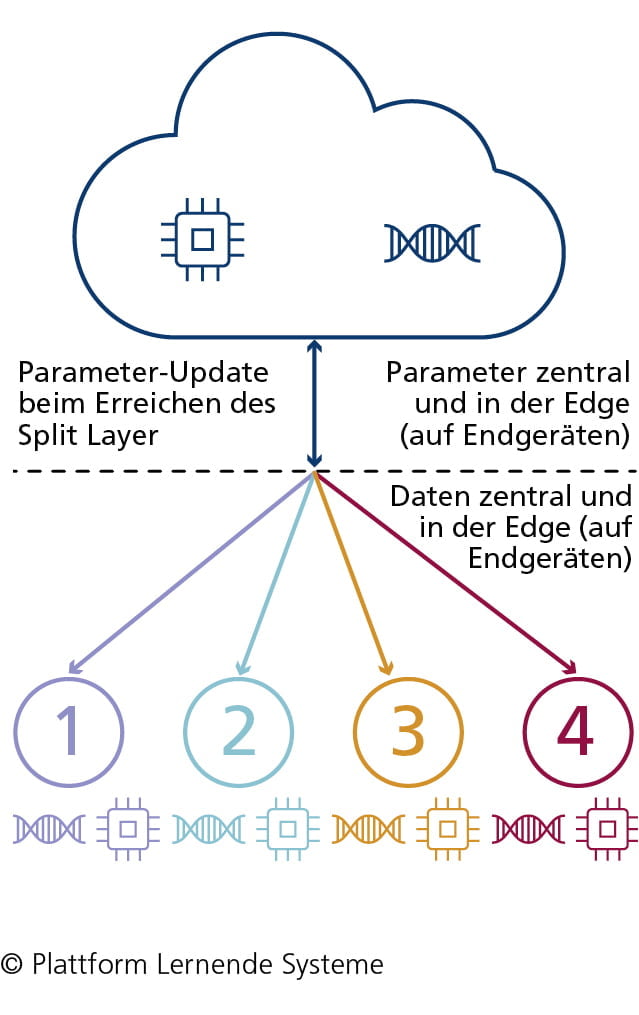
Split Learning
Beim Split Learning wird das KI-Modell auf Endgeräten und dem Server trainiert.
- ML-Modell wird in verschiedene Teilmodelle aufgespalten (sog. Links) und sowohl auf Endgeräten (Clients) als auch auf dem Server trainiert, ohne dass Rohdaten geteilt werden (effiziente Verteilung der Rechenlast)
- Iterativer Trainingsprozess: Endgeräte und Server tauschen am Teilungspunkt des ML-Modells
(sog. Split Layer) statt Rohdaten nur Ergebnisse des trainierten ML-Modellabschnitts (Weights)
aus und trainieren mit diesen auf eigenem Datensatz weiter (geringere Kommunikationskosten) - Iterationen enden bei erreichter Konvergenz zwischen ML-Modellen der Endgeräte und dem Server
Federated Learnig
Beim Federated Learning dient ein zentraler Server als Aggregationsinstanz für Weights.
- Endgeräte laden Parameter des ML-Modells vom Server herunter
- ML-Modell wird durch Endgeräte mit lokalem Datensatz trainiert
- Endgeräte senden nur Weights an den Server; lokaler Datensatz bleibt beim Endgerät
- Auf dem Server findet kein Training statt, sondern nur die Zusammensetzung der Weights
zur zentralen Aktualisierung des ML-Modells (Inferenz) - Server stellt Parameter des verbesserten, weil synchronisierten ML-Modells an Endgeräte für
neuerliches Training bereit - Beliebig wiederholbarer Prozess, bei dem sich das verteilte MLModell stets weiter optimiert
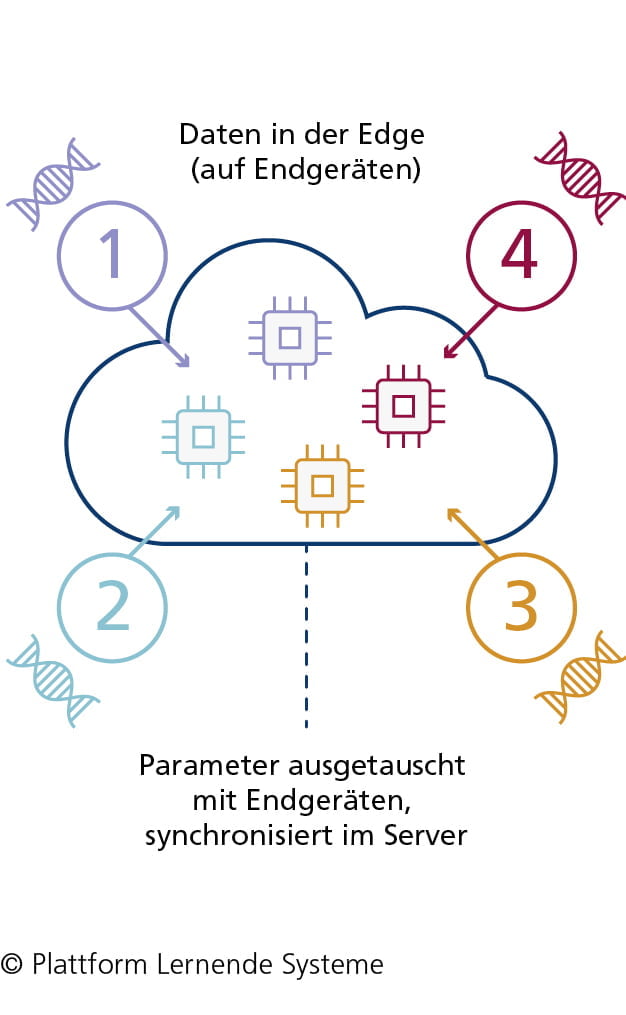
Swarm Learning
Beim Swarm Learning wird ein KI-Modell auf verteilten Geräten ohne zentrale Aggregationsinstanz trainiert.
- Parameter des ML-Modells liegen in zugangsbeschränkter Blockchain statt auf zentralem Server
- Zwar keine Koordinierungsinstanz, aber zentrale Instanz zur Vorautorisierung der Endgeräte
für Zugriff auf Blockchain nötig - Endgeräte laden Parameter des ML-Modells aus Blockchain und können es mit lokalem Datensatz
trainieren - Nach Training werden nur die angepassten Weights in der Blockchain gespeichert
- Angepasste Weights und Parameter des ML-Modells können von Endgeräten ausgelesen und lokal zum Gesamtmodell zusammengesetzt werden

Anwendungsbeispiele für verteiltes maschinelles Lernen
Eine mögliche Anwendung für verteiltes maschinelles Lernen ist Bilderkennung beim autonomen Fahren. Die kontinuierliche Verbesserung eines Bilderkennungsgrundmodells könnte durch Split Training auf viele Autos aufgeteilt werden, die jeweils mit den eigenen Sensordaten das Modell verfeinern. Anschließend stellen sie die lokal trainierten Parameter dem Grundmodell auf dem zentralen Server für weiteres Training zur Verfügung. Der für den Datenschutz relevante Streckenverlauf wird so ausschließlich lokal verarbeitet.
Ein weiteres Beispiel ist das lokale Training von Smartphone-KI-Modellen für Autovervollständigung und Autokorrektur. Durch Federated Learning werden nur die Weights des Modells mit dem zentralen Server geteilt. Mit dem Smartphone geschriebene Texte, die Hinweise auf Lebenssituationen geben können oder gar Betriebsgeheimnisse verraten, bleiben so auf dem Gerät.
Das Swarm Learning könnte bei der datenschutzrechtlich unbedenklichen Diagnose von Krankheiten helfen. Das Diagnosemodell liegt verteilt auf der Blockchain bei verschiedenen Kliniken, die über Krankenkassen zugelassen sind. Die Parameter des zentralen Modells werden von den Kliniken abgerufen, lokal zu einem Gesamtmodell zusammengefügt und mit lokalen Gesundheitsdaten trainiert. Die Parameter des aktualisierten Modells werden dann wieder mit der Blockchain synchronisiert. Medizinisch sensible, persönliche Informationen werden nicht übertragen.
Eine ausführliche Betrachtung des verteilten maschinellen Lernens gibt es im Format "KI Kompakt - Verteiltes maschinelles Lernen" der Plattform Lernende Systeme.
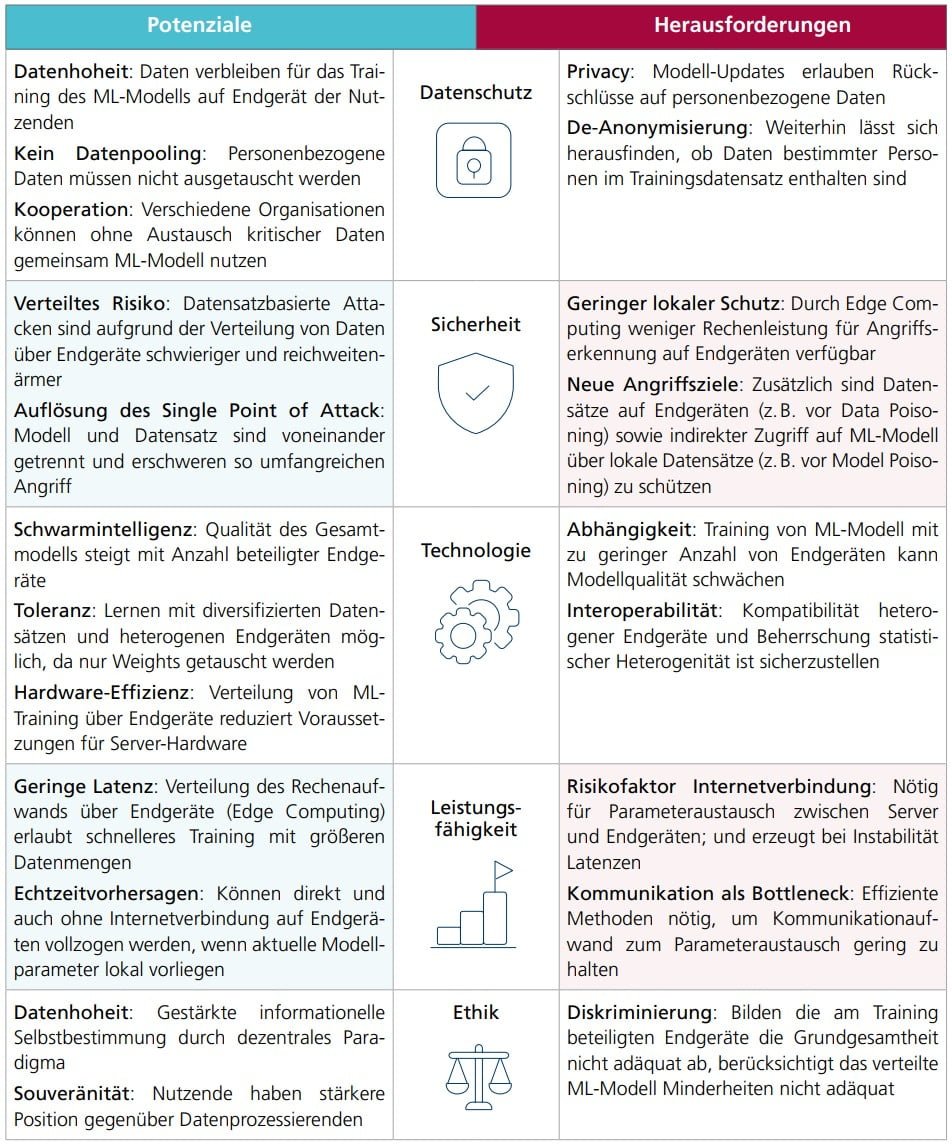
Vor- und Nachteile des verteilten maschinellen Lernens
„Verteiltes maschinelles Lernen eröffnet neue Möglichkeiten zur effektiven und skalierbaren Nutzung von Daten, ohne diese teilen zu müssen. Dadurch werden viele hilfreiche Anwendungen mit sensitiven Daten erst möglich“, so Ahmad-Reza Sadeghi, Professor für Informatik der Technischen Universität Darmstadt und Mitglied der Arbeitsgruppe IT-Sicherheit und Privacy der Plattform Lernende Systeme.
Doch es existieren auch Herausforderungen: Die Verteilung von Daten und Trainingsprozessen auf viele Endgeräte schafft neue Einfallstore für Angreifer:innen. Zudem benötigt verteiltes maschinelles Lernen eine Internetverbindung für den Parameteraustausch, was zu Instabilitäten führen kann.
Modell-Updates lassen Rückschlüsse auf personenbezogene Daten zu. Außerdem können Daten einzelner Personen im Trainingsdatensatz identifiziert werden. Die folgende Grafik gibt einen Überblick über die Vor- und Nachteile.