Nvidias Magic3D macht aus Text hochauflösende 3D-Objekte

Nvidias Magic3D kann anhand von Texteingaben 3D-Objekte erzeugen. Das Modell soll Googles erst im September vorgestelltes Text-zu-3D-Modell Dreamfusion deutlich übertreffen.
Wie Dreamfusion setzt Magic3D im Kern auf ein Bildgenerierungsmodell, das anhand von Text Bilder aus verschiedenen Perspektiven erzeugt, die wiederum als Vorlage für die 3D-Generierung dienen. Nvidias Forschungsteam verwendet dafür das hauseigene Bildmodell eDiffi, Google setzte auf Imagen.
Der Vorteil dieser Methode ist, dass das generative KI-Modell nicht mit spärlich verfügbaren 3D-Modellen trainiert werden muss. Im Unterschied zu Nvidias frei verfügbarem Text-zu-3D-Modell Get3D kann Magic3D zudem viele 3D-Modelle aus verschiedenen Kategorien ohne zusätzliches Training generieren.
Von grob zu fein
Bei Magic3D geht Nvidia vom Groben ins Feine: Zuerst generiert eDiffi anhand von Text gering aufgelöste Beispielbilder, die dann im Zusammenspiel mit Nvidias Instant NGP-Framework zu einer ersten 3D-Repräsentation verarbeitet werden.
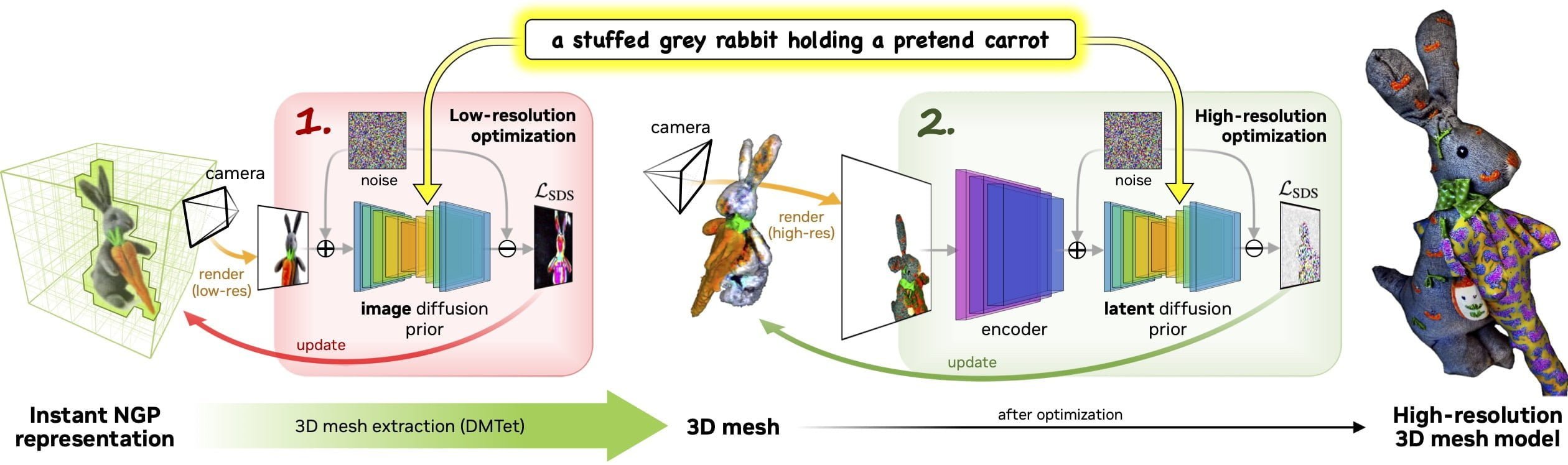
Mit dem für diesen Zweck optimierten KI-Modell DMTet extrahiert das Team aus der einfachen NGP-Repräsentation ein hochwertigeres 3D-Mesh. Das dient als Vorlage für weitere 2D-Bilder, die hochskaliert und dann für die Optimierung des 3D-Meshs verwendet werden
Das Ergebnis ist ein 3D-Modell mit einer Auflösung von bis zu 512 x 512 Pixeln, das laut Nvidia in Standard-Grafik-Software importiert und visualisiert werden kann.
Die Erweiterung der Erstellung von 3D-Inhalten mit natürlicher Sprache könnte erheblich dazu beitragen, die Erstellung von 3D-Inhalten für Neulinge zu demokratisieren und erfahrene Künstler zu beflügeln.
Aus dem Paper
Magic3D übertrifft Dreamfusion bei der Auflösung und Geschwindigkeit
Laut Nvidias Forschungsteam benötigt Magic3D im Vergleich zu Dreamfusion die Hälfte der Zeit für die Generierung eines 3D-Modells – rund 40 Minuten statt anderthalb Stunden – bei einer achtfach höheren Auflösung.
Das folgende Video erklärt den Generierungsprozess und zeigt ab Minute 2:40 3D-Modell-Vergleiche mit Dreamfusion. In ersten Tests mit Nutzern und Nutzerinnen hätten diese in rund 61 Prozent der Fälle Magic3D-Modellen den Vorzug vor Dreamfusion 3D-Modellen gegeben.
Video: Nvidia
Magic3D bietet zudem für Bild-KI-Systeme typische Editierungsfunktionen, die auf den 3D-Generierungsprozess übertragen werden können. So können Texteingaben nach der ersten Grob-Generierung für die Fein-Generierung angepasst werden: Aus einem Eichhörnchen auf einem Fahrrad wird etwa ein Hase auf einem Roller.

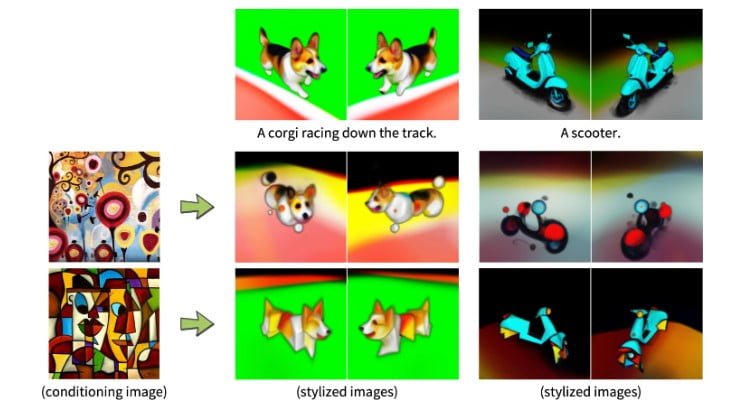
Durch ein Dreambooth-Finetuning des Diffusionsmodells eDiffi können die generierten 3D-Modelle zudem noch feiner auf vorgegebene Motive abgestimmt werden. Das Modell kann auch den Stil eines eingegebenen Bildes auf ein 3D-Modell übertragen.
Nvidias Forschungsteam hofft, dass Magic3D "die 3D-Synthese demokratisieren" und die Kreativität bei der Erstellung von 3D-Inhalten fördern kann. Das dürfte im Sinne des Silicon-Valley-Risikokapitalgebers Andreessen Horowitz sein: Die Firma spekuliert darauf, dass generative KI den Gaming-Sektor umkrempelt, der mit allen Medienformaten und insbesondere mit 3D-Inhalten hantiert.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.