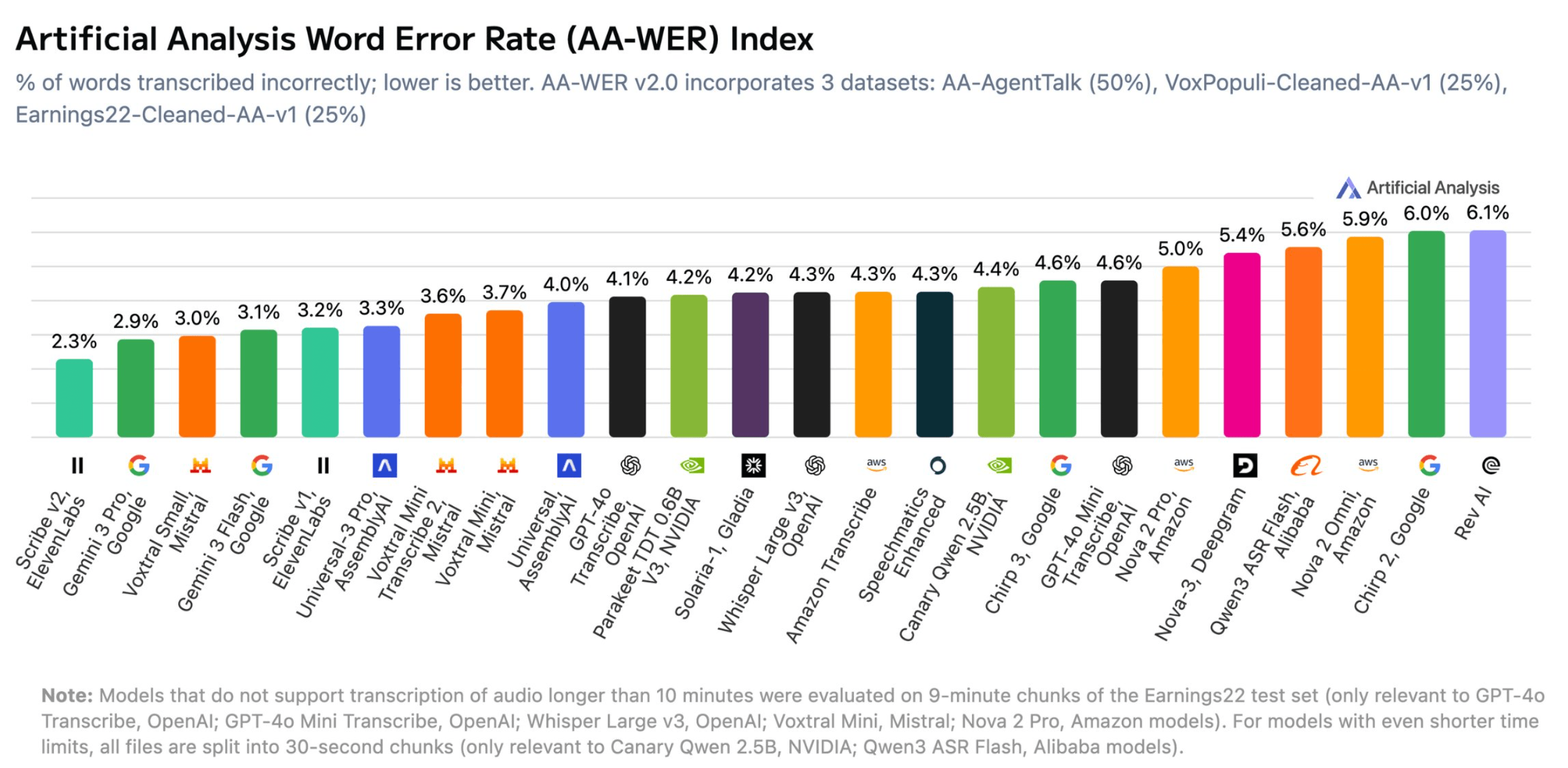
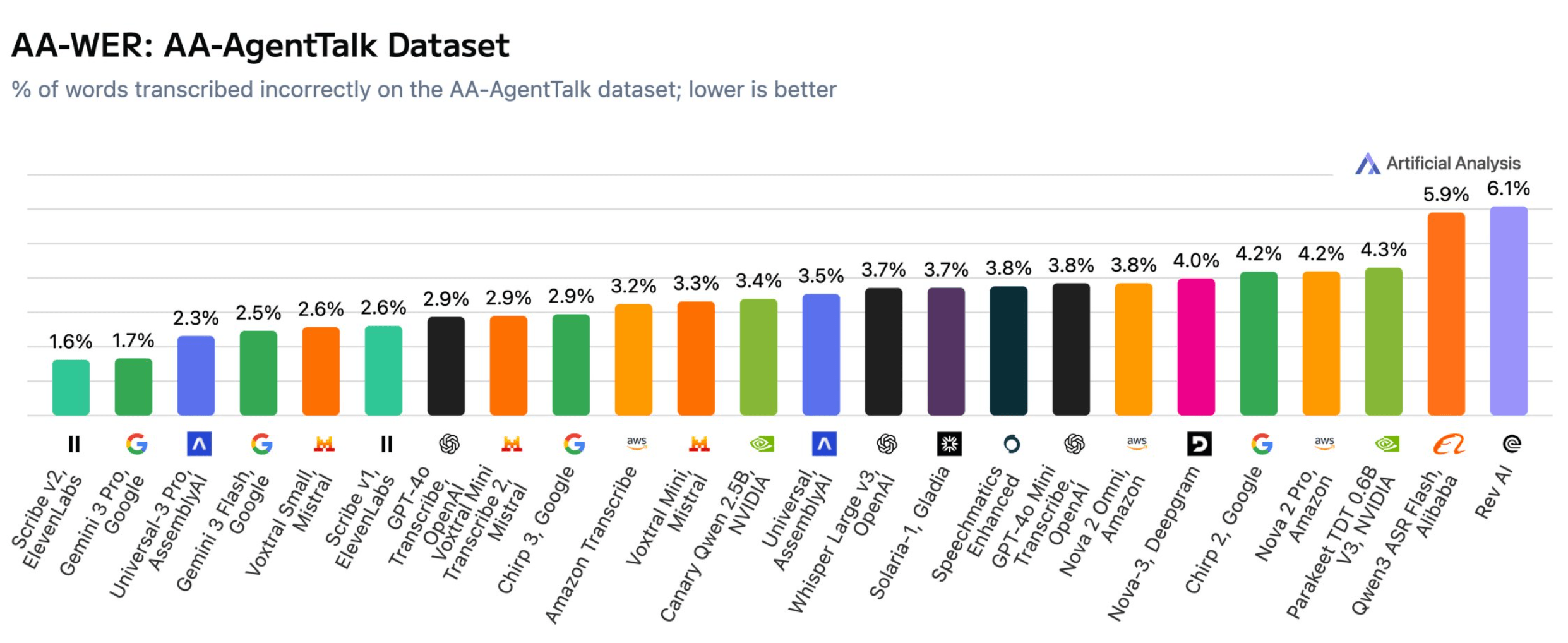
Mehrere US-Bundesbehörden stellen bereits die Nutzung von Anthropics KI-Produkten ein und wechseln zu Konkurrenten wie OpenAI. Laut Reuters betrifft der Wechsel aktuell das Außen-, Finanz- und Gesundheitsministerium sowie das Pentagon und die Wohnungsbaubehörde. Präsident Trump hatte am Freitag alle Behörden angewiesen, Anthropic-Produkte innerhalb von sechs Monaten abzuschaffen. Das Verteidigungsministerium hatte Anthropic zuvor als Lieferkettenrisiko eingestuft und einen Deal mit OpenAI abgeschlossen.
Kurios: Das Außenministerium ersetzt Anthropics Claude-Modelle in seinem internen Chatbot durch das veraltete GPT-4.1-Modell von OpenAI.
Kommentieren
Quelle: Reuters