Multimodale Prompts sind der Schlüssel zu präziseren Bild-KI-Systemen

Die europäische KI-Firma Aleph Alpha stellt eine Innovation bei der KI-Bildgenerierung vor: multimodale Prompts. KI-Bildsysteme sind dank der neuen Technik präziser steuerbar.
Bisherige KI-Modelle verarbeiten in erster Linie Text für neue Bildideen. Das von Aleph Alpha gemeinsam mit der TU Darmstadt entwickelte M-VADER-Diffusionmodell hingegen kann multimodale Eingaben wie Foto, Skizze und textuelle Beschreibung miteinander zu einer neuen Bildidee verschmelzen.
Herzstück der M-Vader-Architektur ist der multimodale Decoder S-MAGMA mit 13 Milliarden Parametern. Er kombiniert das Bild-Sprache-Modell MAGMA mit einem für semantische Suche feingetunten Luminous 13B-Modell. Beide vortrainierten Modelle stammen von Aleph Alpha. Der Output von S-MAGMA leitet den Bildgenerierungsprozess mit einer für multimodale Verarbeitung feingetunten Stable-Diffusion-Version an.
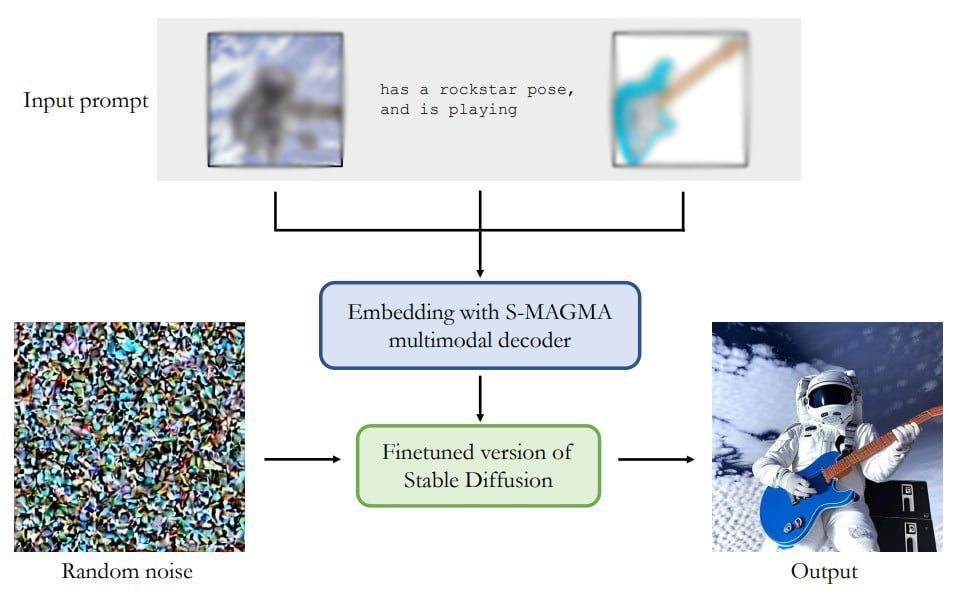
M-Vader kann laut des Teams Bilder anhand von multimodalem Kontext generieren, aus zwei Bildern ein neues Bild oder Variationen eines Bildes erschaffen. Die folgende Grafik zeigt einige Beispiele für die Zusammenführung von mehreren Bildern samt Textanweisungen zu einem neuen Bild.
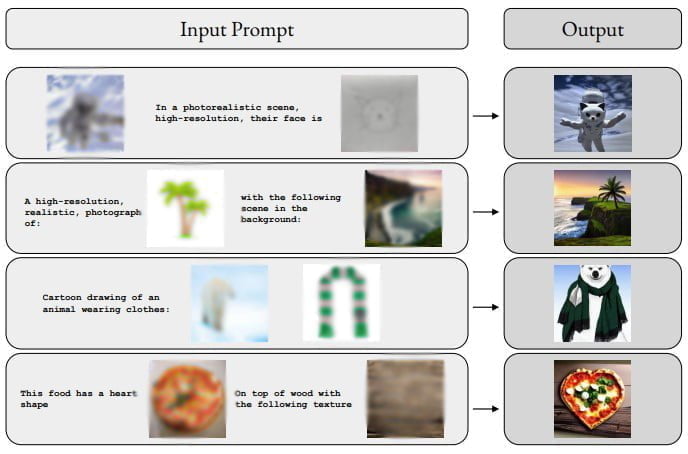
Der Reichtum an Informationen, der in der gewünschten Bildausgabe enthalten ist, lässt sich manchmal nur schwer mit einer (einzigen modalen) Texteingabeaufforderung erfassen. Dies ist der Beitrag dieser Arbeit: eine Methode zur Bilderzeugung mit multimodaler kontextueller Anleitung (mit beliebiger Promptlänge).
Aus dem Paper
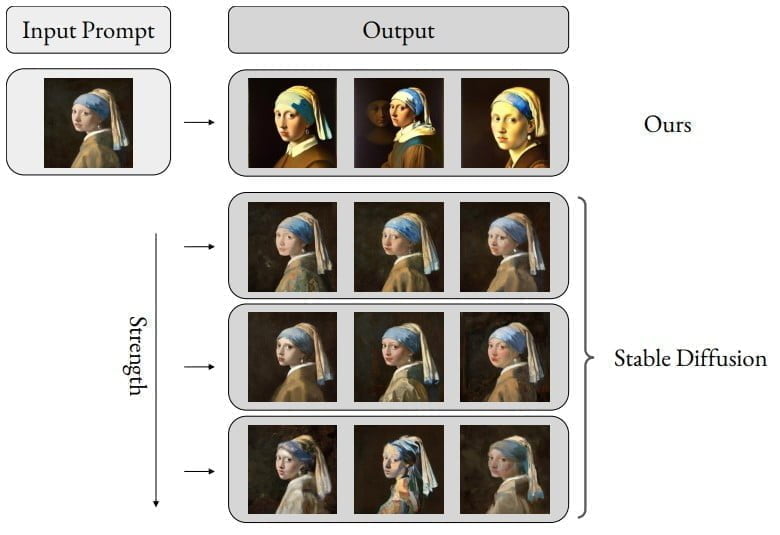
Multimodale Prompts werden Teil von Aleph Alphas Luminous-Modellen
Die Forschenden sehen ihre Arbeit als Beitrag für die Entwicklung multimodaler Prompts für KI-Bildmodelle, die Nutzerintentionen besser erfassen können. Weitere Bild-Beispiele gibt es im Paper.
Unter dem Produktnamen Luminous und Magma bietet Aleph Alpha bereits zwei KI-Basismodelle in verschiedenen Größen für die Textgenerierung und Bildverarbeitung an. Die jetzt vorgestellte multimodale Bildgenerierungstechnik ist laut Aleph-Alpha-CEO Jonas Andrulis eine Weltneuheit. Sie soll bald Teil des Luminous-Angebots werden.
"Unser Wissen ist nicht nur Text, sondern multimodal, und KI muss in der Lage sein, Sprache und Bilder gemeinsam zu verstehen", schreibt Andrulis.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.