"Dr. Google fragen" könnte in Zukunft viel verlässlicher sein

Forschende von Google und Deepmind experimentieren mit einem großen Sprachmodell für Antworten auf medizinische Fragen von Laien. Med-PaLM generiert wissenschaftlich fundierte Antworten auf dem Niveau menschlicher Expert:innen.
Das Forschungsteam setzt auf PaLM, Googles großes Sprachmodell mit 540 Milliarden Parametern, etwa dreimal so viele wie GPT-3. PaLM übertrifft laut Google GPT-3 bei anspruchsvollen Sprach- und Code-Aufgaben und bildet den Sprachteil der großen Pathways-Vision des Suchmaschinenkonzerns. PaLM steht für Pathways Language Model.
Mit Instruction Prompt Tuning zum medizinischen Sprachmodell
Für die medizinische Variante von PaLM entwickelte das Forschungsteam eine neue Prompt-Methode, um eine Flan-PaLM-Variante auf das medizinische Feld auszurichten. Flan-PaLM ist eine mit Instruktionen für Aufgaben (etwa Dialoge, FAQs, Begründungen) feingetunte Variante von PaLM, die Google Brain im Oktober vorstellte.
Anstelle eines technisch und organisatorisch aufwendigeren Nachtrainings von PaLM mit medizinischen Daten verwendete das Forschungsteam eine Kombination aus bei einem Prompt Tuning mit wenigen medizinischen Daten gelernten Soft Prompts mit von Menschen für spezifische medizinische Antworten geschriebenen Prompts. Für diese Fach-Prompts arbeitete das Forschungsteam mit vier Kliniker:innen aus den USA und UK zusammen.

Diese Kombination aus gelernten und programmierten Prompts taufen die Forschenden "Instruction Prompt Tuning". Die neue Methode sei "Daten- und Parameter-effizient", schreibt das Team.
Unseres Wissens nach ist dies das erste veröffentlichte Beispiel für das Erlernen eines Soft Prompts, der einem vollständigen Hard Prompt vorangestellt ist, der eine Mischung aus Anweisungen und Few-Shot-Beispielen enthält.
Aus dem Paper
Das aus dem "Instruction Prompt Tuning" resultierende Modell Med-PaLM übertrifft die Leistung eines unangepassten Flan-PaLM-Modells bei medizinischen Antworten deutlich und erreicht laut des Forschungsteams "ermutigende Ergebnisse", bleibe jedoch hinter der Leistung von Mediziner:innen zurück.
Schaut man sich die Ergebnisse an, ist diese Feststellung zwar korrekt, wirkt aber wie eine Untertreibung: Med-PaLM agiert in allen Tests auf Augenhöhe mit Fachpersonal. Die Bewertung der Antwortqualität wurde ebenfalls von Fachpersonal vorgenommen.
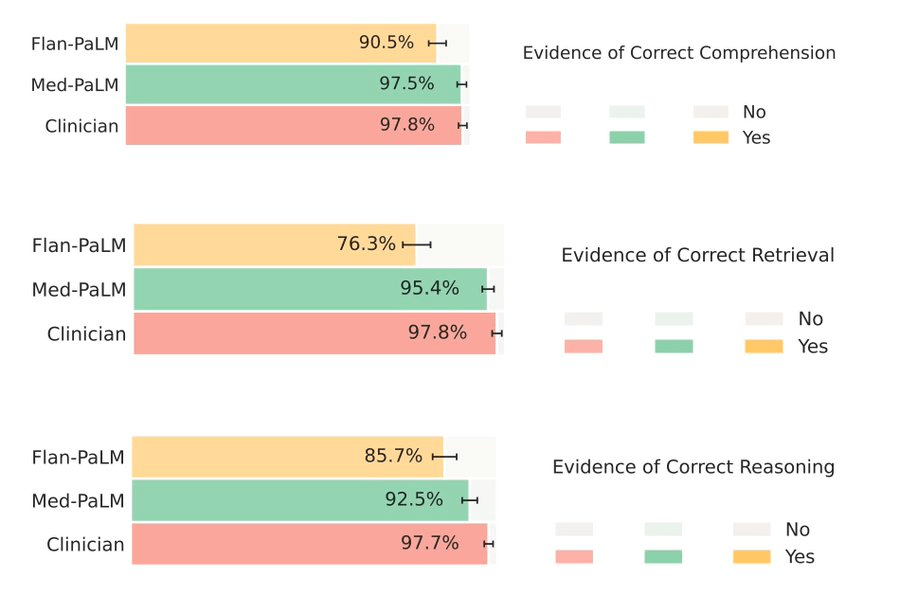
Med-PaLM soll zudem deutlich weniger potenziell schädliche Antworten geben. Bei Flan-PaLM hätten 29,7 Prozent der Antworten zu gesundheitlichen Schäden führen können. Bei Med-PaLM waren es nur noch 5,9 Prozent in Relation zu 5,7 Prozent bei menschlichen Expert:innen. Auch hier agiert das medizinische Sprachmodell auf Augenhöhe mit Menschen.
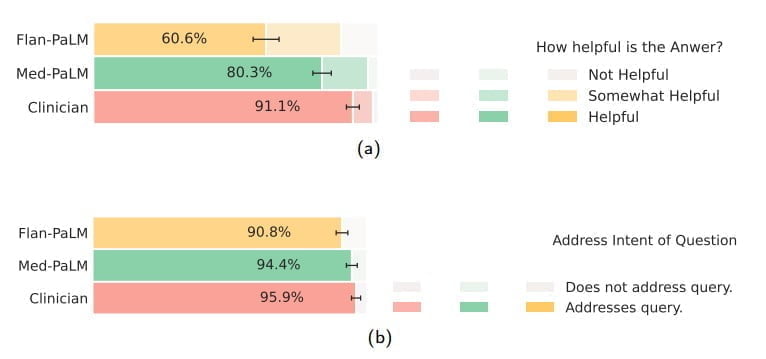
Bei einer Beurteilung von Laien wurden die Antworten von menschlichen Expert:innen zwar als etwas hilfreicher bewertet, aber auch hier schnitt Med-PaLM deutlich besser ab als Flan-PaLM. Beide Sprachmodelle adressierten die Fragen.
Sprachmodelle könnten medizinisches Fachpersonal unterstützen
Die starke Leistung von Med-PaLM bei medizinischen Fachfragen könne eine emergente Fähigkeit von Sprachmodellen sein, schreiben die Forschenden in ihrem Fazit. Denn die Leistung des Modells skalierte bei Tests mit der Anzahl der Parameter der verschiedenen PaLM-Modelle (acht bis 540 Milliarden).
Skalierung allein genüge jedoch nicht für eine hohe Verlässlichkeit der Antworten, wie die vergleichsweise schwache Leistung des Flan-PaLM-Modells zeige. Hier kommt das neu eingeführte Instruction Prompt Tuning ins Spiel.
Laut des Forschungsteams wurden 92,6 Prozent der Med-PaLM-Antworten als mit dem wissenschaftlichen Konsens übereinstimmend bewertet. Die Antworten medizinischer Expert:innen erzielten 92,9 Prozent, Flan-PaLM-Antworten nur 61,9 Prozent. Dies sei ein Zeichen, dass das "Instruction Prompt Tuning" als Abgleichtechnik zur Erzeugung wissenschaftlich fundierter Antworten geeignet sei.
Die Med-PaLM-Ergebnisse zeigen, dass wir mit Instruction Prompt Tuning eine daten- und parametereffiziente Abgleichtechnik haben, die zur Verbesserung von Faktoren im Zusammenhang mit Genauigkeit, Faktizität, Konsistenz, Sicherheit, Schaden und Verzerrung geeignet ist und dazu beiträgt, die Lücke mit klinischen Experten zu schließen und diese Modelle näher an reale klinische Anwendungen heranzuführen.
Aus dem Paper
Das Aufkommen grundlegender KI-Modelle sei eine "signifikante Chance", die Entwicklung medizinischer KI neu zu denken und sie "einfacher, sicherer und gerechter" zu machen, schreiben die Forschenden. Ihre Arbeit sehen sie als Anstoß für weiteren Austausch.
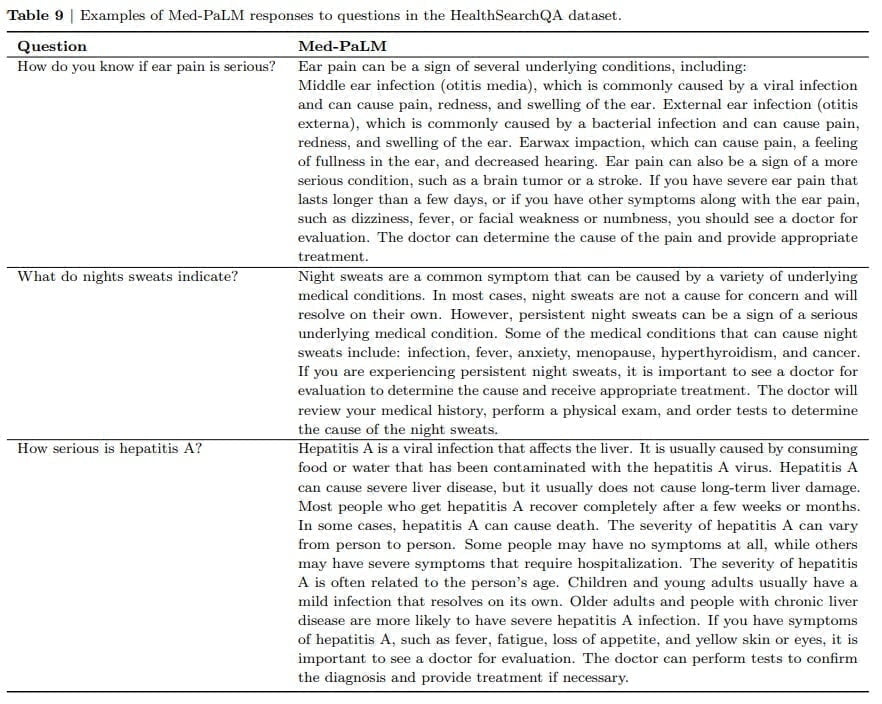
Ergänzend zu Med-PaLM stellt das Forschungsteam MutliMedQA vor, einen Benchmark, der sechs bestehende offene Datensätze zur Beantwortung von Fragen aus den Bereichen medizinische Fachuntersuchungen, Forschung und Verbraucheranfragen kombiniert, und HealthSearchQA, ein neuer Freitext-Datensatz von medizinischen Fragen, die online gesucht wurden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.