Google "Muse" generiert hochwertige KI-Bilder in Rekordtempo

Googles neues Text-zu-Bild-Modell "Muse" generiert hochwertige Bilder in Rekordtempo. Sie soll zudem Texte und Konzepte in Bildern verlässlicher darstellen können.
Forschende von Google Research stellen "Muse" vor, eine Transformer-basierte generative Bild-KI, die Bilder auf dem Niveau aktueller Modelle generiert, dabei aber "signifikant effizienter" sein soll als existierende Diffusion-Modelle wie Stable Diffusion und DALL-E 2 oder autoregressive Modelle wie Google Parti.
Ähnliche Qualität, aber viel schneller
Muse erzielt bei Benchmarks zu Qualität, Diversität und Text-treue der generierten Bilder Ergebnisse auf Augenhöhe mit Stable Diffusion 1.4 und der internen Google-Konkurrenz Parti-3B und Imagen.

Allerdings ist Muse dabei signifikant schneller. Die Bild-KI übertrifft mit 1,3 Sekunden Generierungszeit pro Bild (512 x 512) die bis dato schnellste Bild-KI Stable Diffusion 1.4 mit 3,7 Sekunden deutlich.

Den Geschwindigkeitsvorsprung erzielte das Team durch einen komprimierten, diskreten latenten Raum und eine parallele Dekodierung. Das Team verwendet ein eingefrorenes T5-Sprachmodell, das auf Text-zu-Text-Aufgaben vortrainiert ist. Laut des Teams verarbeitet Muse einen Text-Prompt vollständig, anstatt sich nur auf besonders hervorstechende Wörter zu fokussieren.
Im Vergleich zu Pixelraum-Diffusionsmodellen wie Imagen und DALL-E 2 ist Muse aufgrund der Verwendung diskreter Token und der geringeren Anzahl von Abtastiterationen wesentlich effizienter; im Vergleich zu autoregressiven Modellen wie Parti ist Muse aufgrund der parallelen Decodierung effizienter.
Aus dem Paper
Die neue Architektur ermöglicht zudem eine Reihe an Bildberarbeitungsanwendungen ohne zusätzliches Fein-Tuning oder Umkehrung des Modells. Innerhalb eines Bildes können Objekte allein per Textbefehl ohne Maskierung ausgetauscht oder verändert werden.

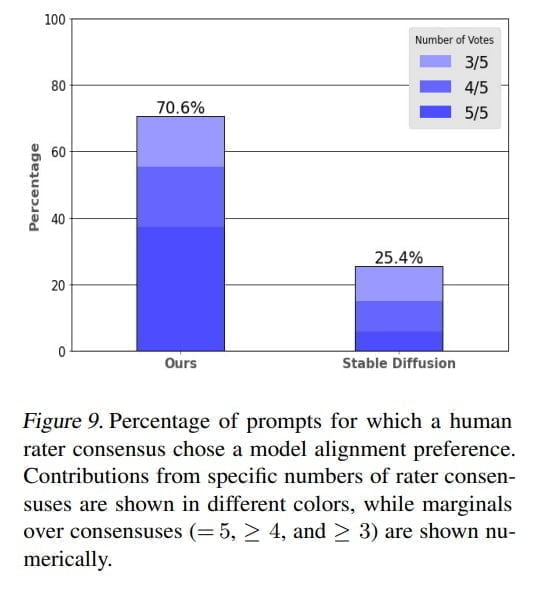
Bei einer Bewertung durch menschliche Tester:innen wurden die Bilder von Muse in rund 70 Prozent der Fälle als besser zur Texteingabe passend bewertet als jene von Stable Diffusion 1.4.
Muse soll zudem überdurchschnittlich gut vorgegebene Wörter in Bilder integrieren können, etwa ein T-Shirt mit dem Schriftzug "Carpe Diem". Bei der Komposition soll Muse ebenfalls präzise sein, stellt also im Prompt vorgegebene Bildelemente in genauer(er) Anzahl, Position und Farbe dar. Das klappt bei derzeit gängigen Bild-KI-Systemen häufig nicht.

Weitere Bild-Beispiele gibt es auf der Projektwebseite. Zu einer möglichen Veröffentlichung des Bildmodells, um mit OpenAIs DALL-E 2 oder Midjourney in den Wettstreit zu gehen, äußern sich die Forschenden und Google direkt bislang nicht. Derzeit ist nur Googles Bildmodell Imagen in einer stark eingeschränkten Beta in den USA verfügbar.
Das Muse-Team warnt, wie es mittlerweile üblich ist in wissenschaftlichen Papieren zu Sprach- und Bild-KI-Systemen, vor einem möglichen "Schadenspotenzial" je nach Anwendungsfall, etwa die Wiedergabe von sozialen Vorurteilen oder Falschinformationen. Deswegen verzichte es auf eine Veröffentlichung des Codes und eine öffentlich zugängliche Demo. Das Team hebt insbesondere das Risiko bei der Verwendung von Bild-KI-Modellen für die Generierung von Personen, Menschen und Gesichtern hervor.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.