Microsoft VALL-E: Text-zu-Sprach-Synthese mit effizienter Stimmklonfunktion

Microsofts generatives KI-Modell VALL-E kann Text in gesprochene Sprache verwandeln. VALL-E nutzt dafür Methoden großer Sprachmodelle - und ist sehr effizient.
Text-zu-Sprachmodelle sind in den vergangenen Jahren dank neuronaler Netze zunehmend leistungsfähiger geworden. Bei der Audio-Synthese verwandeln sie Phoneme in Mel-Spektrogramme, verarbeiten diese im Netzwerk und generieren dann die finalen Wellenformen.
Für das Training benötigen aktuelle Modelle meist qualitativ hochwertige Aufnahmen. Aus dem Internet gesammelte Aufnahmen mit niedriger Qualität führen zu schlechteren Ergebnissen.
Zudem nimmt die Qualität der generierten Audiodateien für Sprecher:innen, die nicht Teil des Trainings sind, deutlich ab. Um die Leistung in solchen Zero-Shot-Szenarien zu verbessern, setzten Forschende daher auf verschiedene Formen von Finetuning, Encoding-Methoden oder komplexe Anpassungen der Systeme.
Microsoft VALL-E lernt von GPT-3 & Co.
Forschende von Microsoft zeigen nun VALL-E, ein Text-zu-Sprache-Modell, das auf das Erfolgsrezept großer Sprachmodelle setzt: "Anstatt ein komplexes und spezifisches Netzwerk für dieses Problem zu entwerfen, besteht die ultimative Lösung darin, ein Modell mit so vielen und so unterschiedlichen Daten wie möglich zu trainieren", heißt es im Paper.
VALL-E wurde daher mit 60.000 Stunden englischer Sprache von 7.000 Sprechern trainiert. Nach Angaben des Teams sind das mehr als 100 Mal so viele Daten, wie bisher in diesem Bereich verwendet wurden. Microsoft verwendet den riesigen LibriLight-Datensatz, den das Team mit KI transkribiert hat.
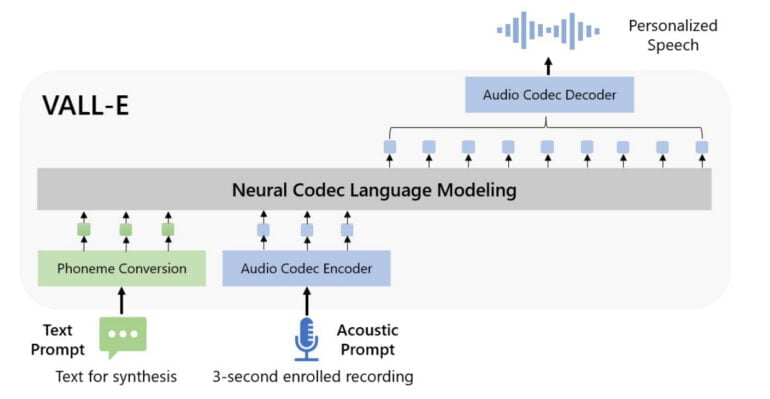
VALL-E verarbeitet eine Kombination aus Text-Prompts und drei Sekunden kurzen akustischen Prompts, die im Netz direkt als akustische Token repräsentiert werden. Damit verzichtet VALL-E auf die sonst üblichen Mel-Spektrogramme. Die akustischen Tokens im Netz werden dann von einem Audio Codec Decoder in Wellenformen verwandelt.
VALL-E erbt die Vorteile großer Sprachmodelle
In ihren Tests zeigen die Forschenden, dass VALL-E Text-Prompts mit der im akustischen Prompt vorgegebenen Stimme generieren kann.
Akustischer Prompt
Text-Prompt
"Her husband was very concerned that it might be fatal."
VALL-E
Das Modell übernimmt dabei auch weiter Aspekte des Audioschnipsels: Eine verrauschte Telefonaufnahme klingt auch in der synthetisierten Fortführung durch.
Akustischer Prompt
Text-Prompt
"Um we have to pay have this security fee just in case she would damage something but um."
VALL-E
Zusätzlich übernimmt das Modell auch durch Emotionen beeinflusste Stimmlagen, etwa die eines zornigen Sprechers.
Akustischer Prompt
Text-Prompt
"We have to reduce the number of plastic bags."
VALL-E
Wenn der akustische Prompt Nachhall hat, kann VALL-E auch Sprache mit Nachhall synthetisieren, während die Basislinie saubere Sprache ausgibt. Außerdem kann VALL-E die gleiche Emotion des Prompts in der Sprachsynthese beibehalten, auch wenn das Modell nicht auf einen emotionalen TTS-Datensatz abgestimmt ist.
Aus dem Paper
Interessant ist das, weil VALL-E nicht explizit darauf trainiert wurde, Emotionen in Stimmen zu übernehmen. Das Modell zeige also einige emergente Fähigkeiten und könne im Kontext lernen - so wie große Sprachmodelle.
Weitere Audio-Beispiele gibt es auf GitHub. Der Code ist bisher nicht verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.