Deepmind Ada bringt Foundation Models ins Reinforcement Learning

Deepminds AdA zeigt, dass Foundation Models auch im Reinforcement Learning generalistische Systeme ermöglichen, die neue Aufgaben schnell erlernen.
In der KI-Forschung wird der Begriff Foundation Model von einigen Wissenschaftler:innen benutzt, um große KI-Modelle zu bezeichnen, die meist auf Transformer-Architekturen basieren und generalistisch trainiert wurden. Ein Beispiel ist das große Sprachmodell GPT-3 von OpenAI, das mit vielen Texten auf die Vorhersage von Text-Tokens trainiert wird und dann spezialisierte Aufgaben durch Prompt-Engineering im Few-Shot-Setting ausführen kann.
Kurz gesagt: Ein Foundation Model ist ein großes KI-Modell, das aufgrund seines generalistischen Trainings mit großen Datensätzen später viele Aufgaben übernehmen kann, für die es nicht explizit trainiert wurde.
Deepminds AdA lernt im Kontext ohne Netzwerkupdate
Bisherige Foundation Models setzen vor allem auf selbstüberwachtes Training. Deepmind präsentiert nun einen "Adaptive Agent" (AdA), einen Reinforcement-Learning-Agenten, der Eigenschaften eines Foundation Models aufweist.
Das Deepmind-Team hat AdA in zahlreichen Durchläufen in der XLand-3D-Umgebung trainiert und dabei auf eine intelligente Auswahl der jeweiligen Aufgaben gesetzt: Anstatt die Herausforderungen zufällig zu wählen, trainiert AdA immer Aufgaben, die knapp über den aktuellen Fähigkeiten des Agenten liegen. Die Aufgaben erfordern Fähigkeiten wie Experimentieren, Navigation, Koordination, Arbeitsteilung mit anderen Agenten und den Umgang mit irreversiblen Entscheidungen.
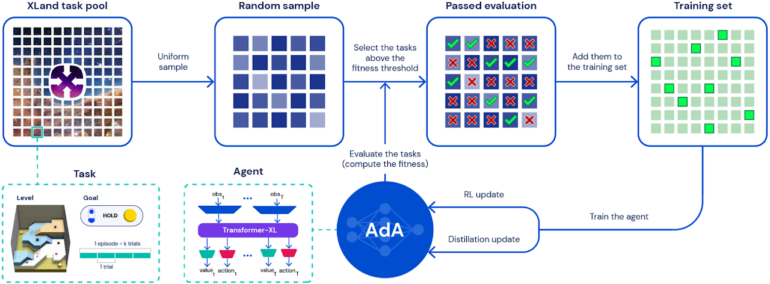
AdA setzt auf eine angepasste Transformer-Architektur, die es dem Agenten erlaubt, deutlich mehr Informationen zu speichern und so ein effizientes Training zu ermöglichen, so Deepmind.
Zusätzlich nutzt das Team die Destillation mit einem Teacher-Student-Verfahren, um den Lernprozess zu beschleunigen und größere Modelle zu trainieren. In der Arbeit trainierte das Unternehmen ein Modell mit 265 Millionen Parametern und zeigte, dass 500 Millionen Parameter mit der Methode möglich sind.
Deepmind AdA lernt in XLand 2.0
Durch das Training des Transfomer-Modells mit Millionen von Durchläufen in der XLand-Umgebung entstehe ein Foundation-RL-Modell, schreibt Deepmind. AdA zeige bei der Erkundung neuer Aufgaben ein "hypothesengetriebenes Explorationsverhalten", nutze die gewonnenen Informationen zur Verfeinerung von Strategien und erreiche eine annähernd optimale Leistung.
Der Prozess dauere auch bei schwierigen Aufgaben nur wenige Minuten und liege damit auf menschlichem Niveau. Das Ganze sei zudem ohne Aktualisierung der Gewichte im Netz möglich - AdA zeigt wie GPT-3 Few-Shot-Fähigkeiten, der Lernprozess findet im Kontextfenster des Modells statt.
In diesem Beitrag demonstrieren wir zum ersten Mal einen mit RL trainierten Agenten, der in der Lage ist, sich schnell an einen großen, offenen Aufgabenraum anzupassen, und zwar auf einer Zeitskala, die der von menschlichen Spielern ähnelt. Dieser adaptive Agent (AdA) erkundet strukturiert vorgegebene Aufgaben und verfeinert seine Strategie in Richtung eines optimalen Verhaltens bereits nach wenigen Interaktionen mit der Aufgabe.
Aus dem Paper
AdA basiert auf Black-Box-Meta-Reinforcement-Learning und zeigt, entgegen früheren Annahmen, dass die Methode skalierbar ist, so Deepmind. Unter Berücksichtigung der Skalierungsgesetze von Sprachmodellen oder anderen Foundation-Modellen könnten RL-Modelle wie AdA daher in Zukunft die Grundlage für nützliche RL-Modelle für Steuerungsprobleme in der realen Welt werden.
Wer mehr über Reinforcement Learning erfahren möchte, kann sich unseren DEEP MINDS-Podcast Folge #1 mit am Paper beteiligten KI-Experten Tim Rocktäschel anhören. Wer mehr über Meta-Learning wissen will, schaut in unsere DEEP MINDS Folge #6 zu Meta-Learning mit Robert Lange.
Mehr Informationen und Beispiele gibt es auf der AdA-Projektseite.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.