Pix2pix-zero erleichtert die Bildbearbeitung in Stable Diffusion

Pix2pix-zero soll einfache Bildbearbeitungen mittels Stable Diffusion ermöglichen, ohne dabei unbeabsichtigte Veränderungen vorzunehmen.
Für generative KI-Modelle wie Stable Diffusion, DALL-E 2 oder Imagen existieren verschiedene Methoden wie Inpainting, Prompt-to-Prompt oder InstructPix2Pix, die eine Bearbeitung echter oder generierter Bilder ermöglichen.
Forschende der Carnegie Mellon University und Adobe Research stellen nun mit pix2pix-zero eine Methode vor, die besonderen Wert auf den Erhalt der Struktur des Originalbildes legt. Damit sollen einfache Änderungen ohne aufwendiges Feintuning oder Prompt-Engineering möglich sein.
Pix2pix-zero synthetisiert nach Vorlage
Methoden wie Prompt-to-Prompt oder InstructPix2Pix können die Struktur des Ausgangsbildes verändern oder so stark an ihm haften, dass die gewünschten Veränderungen nicht vorgenommen werden.
Eine Lösung ist die Kombination von Inpainting und InstructPix2Pix, die gezieltere Veränderungen erlaubt. Pix2pix-zero verfolgt einen anderen Ansatz: Die Forschenden synthetisieren ein komplett neues Bild, verwenden dabei aber eine Anleitung für den generativen Prozess.
Die Methode unterstützt einfache Veränderungen wie "Katze zu Hund", "Hund zu Hund mit Sonnenbrille" oder "Skizze zu Ölgemälde". Als Eingabe dient ein Originalbild, aus dem ein BLIP-Modell eine Textbeschreibung ableitet, die dann von CLIP in ein Text-Embedding umgewandelt wird.
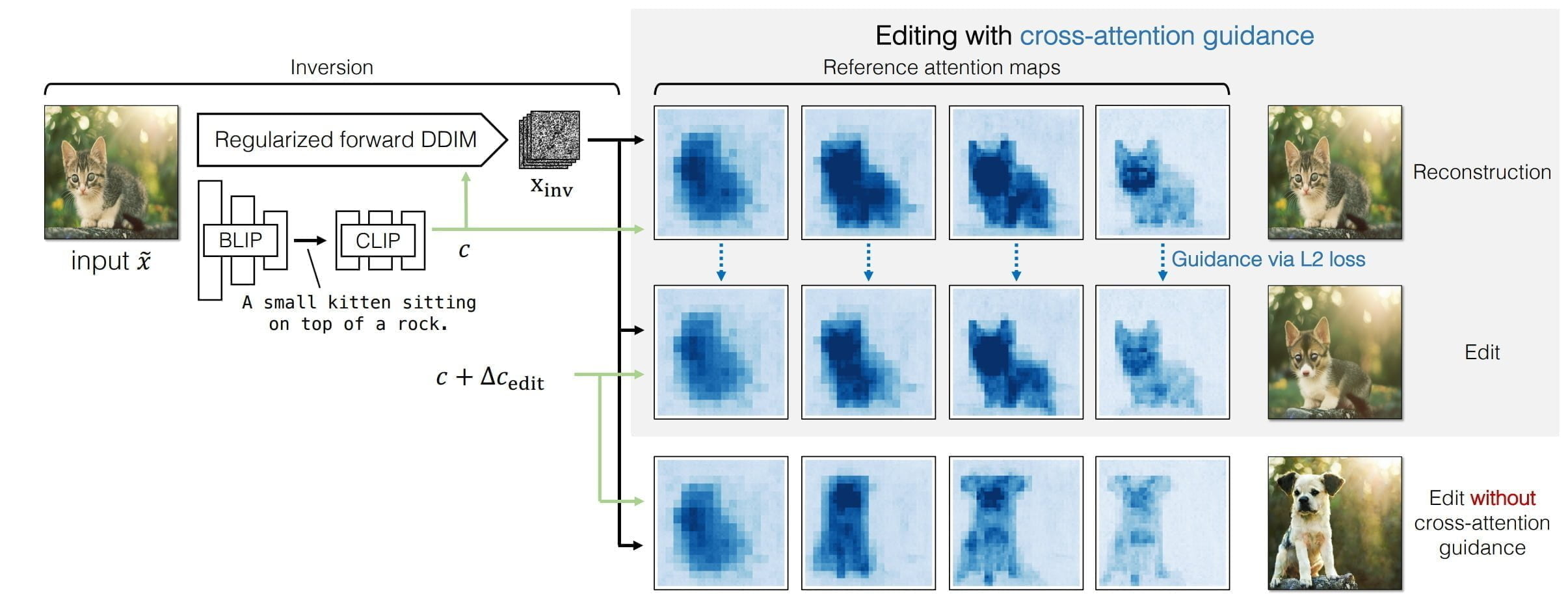
Zusammen mit einer invertierten Rauschdarstellung wird das Text-Embedding zur Rekonstruktion des ursprünglichen Bildes verwendet. Die einzelnen Abschnitte dieser Rekonstruktion dienen in einem zweiten Schritt als Leitfaden für die Synthese des gewünschten Bildes, zusammen mit dem ursprünglichen Text-Embedding und einem neuen Text-Embedding, das die Veränderung leitet.
Da die Veränderung "Katze zu Hund" nicht detailliert durch eine Texteingabe beschrieben wird, kann dieses neue Text-Embedding nicht aus einem Prompt gewonnen werden. Stattdessen generiert pix2pix-zero über GPT-3 eine Reihe von Prompts für "Katze", z.B. "Eine Katze wäscht sich, eine Katze beobachtet Vögel am Fenster, ..." und für "Hund", z.B. "Das ist mein Hund, ein Hund hechelt nach einem Spaziergang, ...".
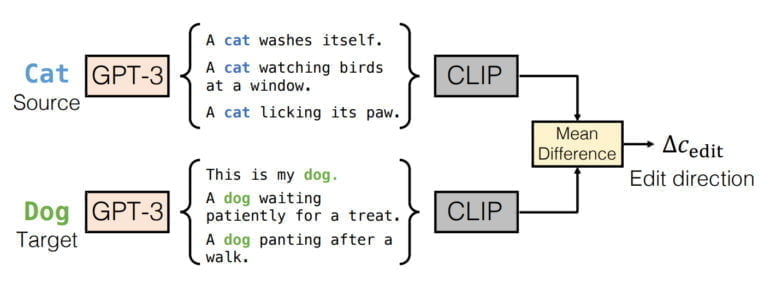
Für diese generierten Prompts berechnet pix2pix-zero zuerst die CLIP-Embeddings und dann die mittlere Differenz aller Embeddings. Das Ergebnis dient dann als neues Text-Embedding für die Synthese des neuen Bildes, zum Beispiel das Bild eines Hundes.
Pix2pix-zero bleibt nahe am Original
An verschiedenen Beispielen zeigen die Forscherinnen und Forscher, wie nah pix2pix-zero am Originalbild bleibt - auch wenn immer wieder kleine Veränderungen sichtbar werden. Die Methode funktioniert mit verschiedenen Bildern, darunter Fotos oder Zeichnungen, und kann Stile, Objekte oder Jahreszeiten verändern.
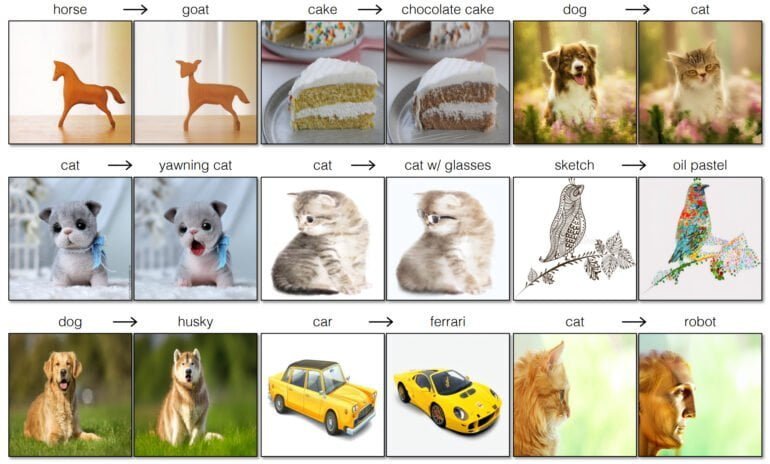
Im Vergleich zu einigen der verglichenen Methoden liegt pix2pix-zero jedoch qualitativ deutlich vorne. Ein direkter Vergleich mit InstructPix2Pix wird in der Arbeit nicht gezeigt.

Die Qualität der Ergebnisse hänge auch von Stable Diffusion selbst ab, heißt es in dem Papier. Die zur Orientierung verwendeten "Cross-Attention Maps", die zeigen, auf welche Bildbereiche das Modell in jedem Entrauschungsschritt seine Aufmerksamkeit richtet, liegen in Stable Diffusion in einer Auflösung von 64 mal 64 Pixeln vor. Höhere Auflösungen könnten in Zukunft noch detailliertere Ergebnisse liefern.
Ein weiterer Nachteil der diffusionsbasierten Methode ist, dass sie viele Schritte und damit viel Rechenleistung und Zeit benötigt. Als Alternative schlägt das Team daher ein GAN vor, das mit den von pix2pix-zero erzeugten Bildpaaren für die gleiche Aufgabe trainiert wird.
Vergleichbare Bildpaare seien bisher nur sehr aufwendig und damit teuer zu erzeugen, so das Team. Die kleinste Variante des GAN erreicht ähnliche Ergebnisse wie pix2pix-zero bei einer 3.800-fachen Beschleunigung. Auf einer Nvidia A100 entspricht dies 0,018 Sekunden pro Bild. Die GAN-Variante ermöglicht somit Änderungen in Echtzeit.
Mehr Informationen und Beispiele gibt es auf der Projektseite von pix2pix-zero.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.