Was ChatGPT hilft, könnte auch Computer Vision helfen
OpenAIs ChatGPT profitiert vom Training mit menschlichem Feedback. Google zeigt nun, dass diese Methode auch Computer-Vision-Modelle verbessern kann.
Die ersten Deep-Learning-Modelle zur Objekterkennung basierten auf überwachtem Lernen mit einer großen Anzahl markierter Bilder. Beispielsweise wird ein Bild einer Katze mit einem digitalen Etikett mit dem Wort "Katze" versehen. Auf diese Weise lernt das System den Zusammenhang zwischen Wort und Bild.
Mit dem Aufkommen und dem Erfolg der Transformer-Architektur in der Sprachverarbeitung begannen Forscherinnen und Forscher, Transformer und selbstüberwachtes Lernen erfolgreich in der Computer Vision einzusetzen.
Exakt beschriftete Bilddateien wurden überflüssig: Wie Textmodelle lernten auch Bildmodelle aus großen Mengen unstrukturierter Daten. Googles Vision Transformer war eine der ersten Architekturen, die das Niveau älterer, überwacht trainierter Modelle erreichte.
Reinforcement Learning kann vortrainierte KI-Modelle verbessern
Bereits nach der Veröffentlichung des großen Sprachmodells GPT-2 begann OpenAI verstärkt mit dem Training von Sprachmodellen durch Reinforcement Learning mit menschlichem Feedback (RLHF) zu experimentieren. Denn große, vortrainierte Sprachmodelle sind zwar extrem vielseitig einsetzbar, aber schwer zu kontrollieren - eine Tatsache, die derzeit Microsoft mit dem Chatbot Bing zu spüren bekommt.
RLHF versucht dagegen, dem großen Sprachmodell über Belohnungssignale beizubringen, welche Textgenerierungen erwünscht und welche falsch oder unerwünscht sind. Wie ChatGPT zeigt, führt dies nicht nur zu einem zielgerichteteren Modell - es scheint sich auch positiv auf die Leistung des Systems auszuwirken.
Google-Forschende haben diese Erkenntnis nun aufgegriffen und getestet, ob auch große Computer-Vision-Modelle von Reinforcement Learning (RL) mit Belohnungssignalen profitieren können. Das Team trainierte mehrere Vision-Transformer-Modelle und optimierte sie dann mit einem einfachen Reinforcement-Learning-Algorithmus für bestimmte Aufgaben wie Objekterkennung, panoptische Segmentierung - eine Kombination aus semantischer Segmentierung und Erkennung - oder das Einfärben von Bildern.
Auch Computer-Vision-Modelle profitieren von Belohnungssignalen
Das Team zeigt, dass die durch RL verbesserten Modelle für die Objekterkennung und die panoptische Segmentierung auf dem Niveau von Modellen liegen, die auf diese Aufgaben spezialisiert sind. Das Modell für die Einfärbung liefert dank RL ebenfalls bessere Ergebnisse.
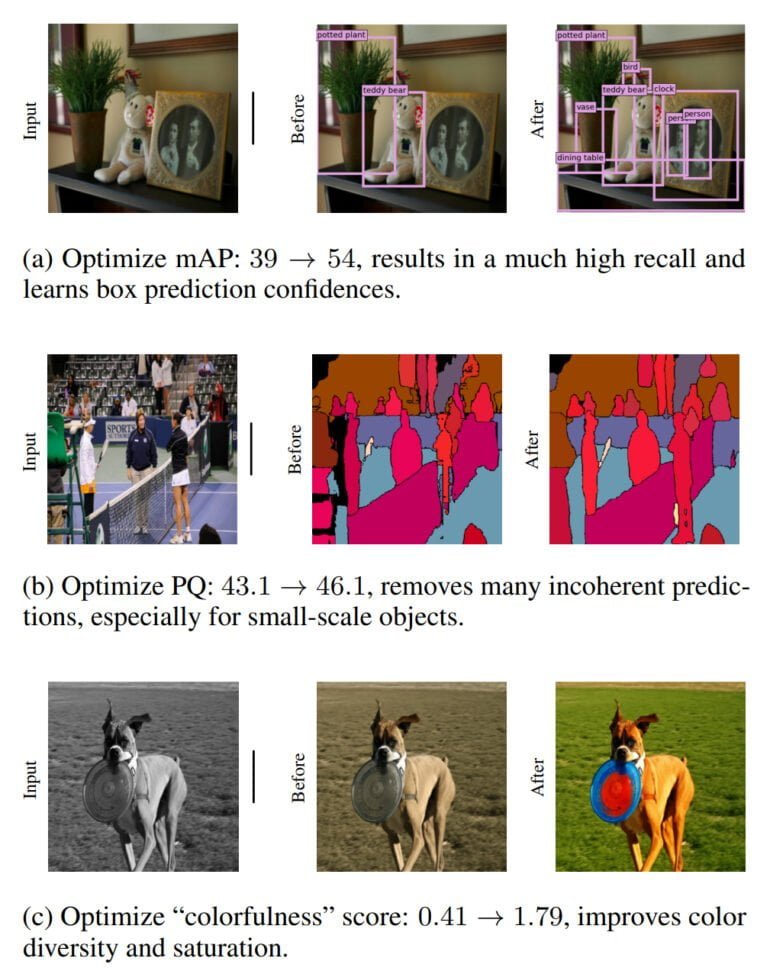
Die Arbeit von Google zeigt als Machbarkeitsstudie, dass Reinforcement Learning mit Belohnungssignalen in der maschinellen Bildverarbeitung, ähnlich wie in der Sprachverarbeitung, zu besseren Modellen führen kann.
Der nächste Schritt wäre, diese Belohnungssignale mit menschlichem Feedback zu kombinieren - wie bei ChatGPT. Die Forschenden halten das für eine vielversprechende Forschungsrichtung und möchten RLHF in der Computer Vision auf anspruchsvolle Aufgaben wie die Steuerung von Roboterarmen, die Objekte greifen sollen, anwenden. Hier könnten die für die Steuerung verantwortlichen Modelle durch RLHF eine höhere Erfolgsrate beim Greifen ermöglichen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.