ERNIE-Music: Erster Durchbruch für Text-zu-Waveform?
Mithilfe von Internetkommentaren haben chinesische Forschende Daten aus Text und Musik gesammelt. ERNIE-Music nutzt die, um aus Text Musik zu generieren.
Aus Text Musik zu generieren, stellt derzeit noch eine große Herausforderung dar. Dafür gibt es mehrere Gründe, ein wesentlicher ist jedoch das Fehlen einer kritischen Masse an Trainingsdaten. Um ein solches Text-Musik-Modell zu entwickeln, benötigt man nicht nur die Musik selbst, sondern vor allem auch eine Beschriftung der entsprechenden Daten in Textform.
Einige Methoden versuchen daher, dieses Problem zu umgehen, wie beispielsweise Riffusion, bei dem mithilfe von Stable Diffusion direkt Bilder von Musik in Wellenform erzeugt und dann in hörbare Schnipsel umgewandelt werden.
Forschende des chinesischen Internetkonzerns Baidu präsentieren nun eine mögliche Lösung für den Datenmangel und das generative Text-zu-Waveform-Modell ERNIE-Music.
Positiv bewertete Kommentare dienen für Text-Training
ERNIE-Music ist laut dem Team das erste KI-Modell, das aus freiem Text Musik in Waveform generiert. Die dafür notwendigen Daten sammelt Baidu aus chinesischen Musikplattformen - welche das genau sind, verrät das Paper nicht.
Insgesamt trägt das Team 3.890 Text- und Musikpaare zusammen. Die Texte stammen aus positiv bewerteten Kommentaren auf den Musikplattformen und beschreiben laut den Forschenden die Musik.
"Nach unserer Beobachtung sind die 'populären Kommentare' im Allgemeinen von relativ hoher Qualität und enthalten in der Regel viele nützliche musikbezogene Informationen wie Musikinstrumente, Genres und ausgedrückte menschliche Stimmungen", heißt es im Paper.

Baidu nutzt die Daten, um das ERNIE-Music-Diffusionsmodell auf die Synthese von Waveforms aus Textbeschreibungen zu trainieren. Die so generierte Musik weise eine große Vielfalt auf, sowohl in Bezug auf Melodien und Emotionen als auch in Bezug auf Instrumente wie Klavier, Violine, Erhu und Gitarre.
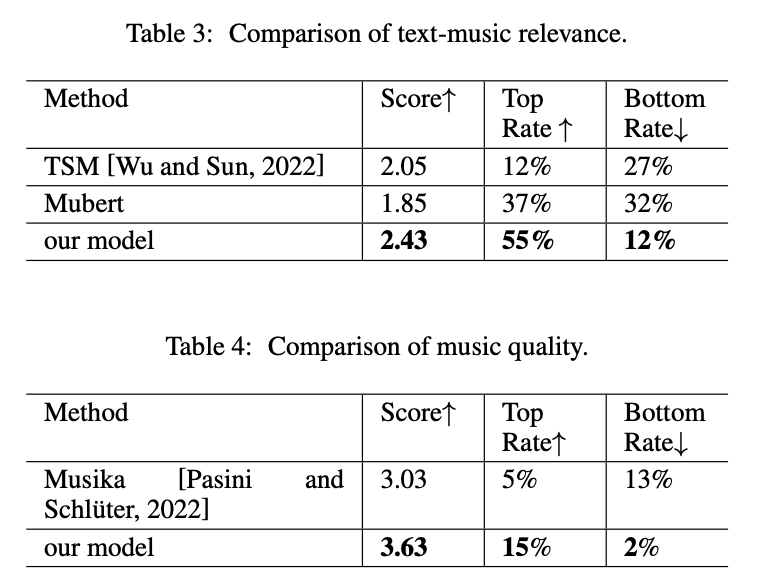
Um ERNIE-Music zu evaluieren, greift das Team auf menschliches Feedback von zehn Personen zurück, die generierte Musik von ERNIE-Music mit anderen Modellen wie Mubert, Text-to-Symbolic Music und Musika vergleichen. Das Modell des chinesischen Teams schneidet in diesen Benchmarks am besten ab.
Baidu untersucht auch, ob das für ERNIE-Music durchgeführte Training mit freiem Text bessere Ergebnisse liefert als ein Training mit aus dem Text extrahierten relevanten Schlüsselwörtern wie "piano, violin, gentle, melancholic". Tatsächlich können die Forschenden zeigen, dass sich das gewählte Textformat im Training auswirkt und das mit Freitext trainierte Modell im Vergleich deutlich besser abschneidet.
Die Ergebnisse zeigen, dass unser auf freiem Text basierendes bedingtes generatives Modell vielfältige und kohärente Musik erzeugt und ähnliche Arbeiten in Bezug auf Musikqualität und Text-Musik-Relevanz übertrifft.
Aus dem Paper
Kommt jetzt das "DALL-E für Musik"?
Wie sind also die Ergebnisse der Forscher von Baidu einzuordnen? Sind wir damit einem "DALL-E für Musik" einen Schritt näher gekommen? Leider stellt das Team weder Hörproben noch Quellcode zur Verfügung, eine unabhängige Bewertung steht also noch aus. Aber Baidus Ansatz folgt dem auch in der Bildsynthese so erfolgreichen End-to-End-Training mit multimodalen Datenpaaren und bietet eine vergleichsweise einfache Lösung, diese für Musik zu gewinnen.
Allerdings ist die hier gesammelte Datenmenge im Vergleich zur benötigten winzig, und es bleibt abzuwarten, ob die Methode auf mehr Musik und andere Sprachen skaliert werden kann. Eine solche Skalierung dürfte zudem ähnliche Urheberrechtsdiskussionen nach sich ziehen wie bei den Bildmodellen - nur dass die Musiker:innen durch ihre Labels eine viel größere Lobby haben.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.