Schreiben per Gedankenkraft: Facebook zeigt neue Hirnschnittstelle

Forscher der University of California San Francisco (UCSF) stellen mit Unterstützung der Facebook Reality Labs eine Hirnschnittstelle vor, mit der ein Proband ohne Stimme kommunizieren kann: Er denkt die Wörter einfach und sie erscheinen auf dem Monitor.
Die Forscher stellen die Kommunikationsfähigkeit des Probanden wieder her, indem sie Gehirnsignale, die vom motorischen Kortex an den Vokaltrakt gesendet werden, dekodieren und auf einem Monitor anzeigen.
So kann sich der Proband mitteilen, indem er daran denkt, zu sprechen, anstatt tatsächlich zu sprechen. Er verlor seine natürliche Sprechfähigkeit bereits vor 16 Jahren nach einem Hirnstamm-Schlaganfall.
Die Forscher implantierten vorab Elektroden direkt über dem Hirnareal, das den Vokaltrakt kontrolliert. Die eigentliche Leistung liegt aber im KI-Programm, das Gehirnsignale zu ausgeschriebenen Sätzen umwandelt: Es nimmt die neuronalen Signale auf, die der Proband erzeugt, wenn er etwa an die Antwort auf eine Frage denkt, erkennt darin einzelne Wörter und setzt diese in Echtzeit zu einem Satz zusammen.
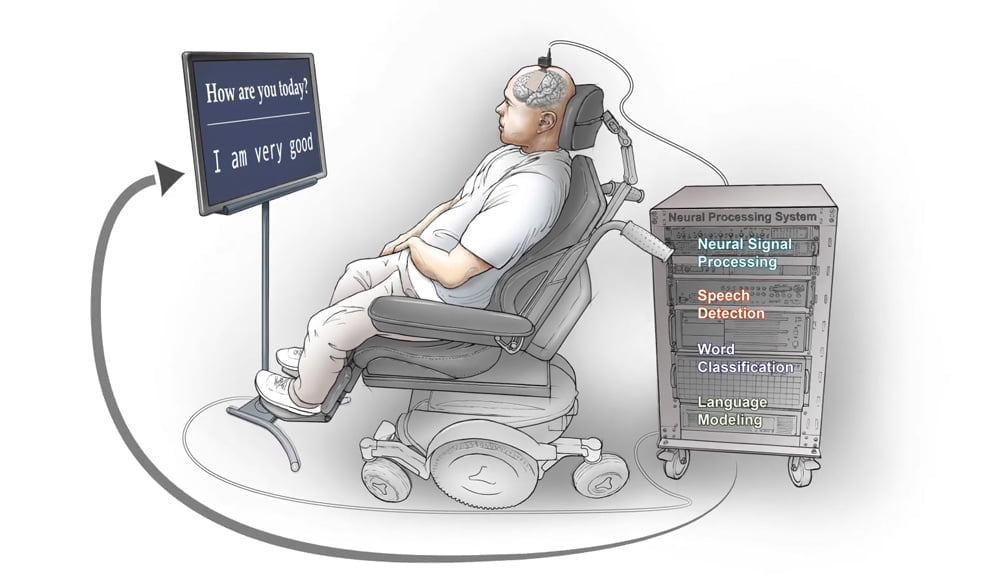
Projekt Steno: Eine Gehirn-Prothese für Sprache
Die "Sprach-Neuroprothese", so nennen die Forscher ihr System, kann derzeit 50 Wörter unterscheiden und mit diesen mehr als 1.000 Sätze schreiben. Generiert werden die Sätze mit Unterstützung von Wort- und Satzervorhersagetechnologie, wie man sie vom Smartphone kennt. Für die Antwort auf eine einfache Frage wie "Wie geht es dir?" benötigt der Proband in einer Demonstration so rund 18 Sekunden.
Die durchschnittliche Worterkennungsrate liegt bei 74 Prozent bei einer Geschwindigkeit von 15 Wörtern pro Minute. Die bestmögliche Leistung bei Tests lag laut der Forscher bei einer Genauigkeit von bis zu 93 Prozent für 18 Wörter pro Minute.
Die Forscher gehen davon aus, dass ihre Arbeit neuer Technologie den Weg ebnet, die Menschen mit Lähmungen wieder schnelle und natürliche Kommunikation ermöglicht. Ihre Ergebnisse veröffentlichen sie in der Fachzeitschrift "The New England Journal of Medicine".
Facebook-Verantwortliche sprachen schon 2017 über Forschung an Gehirninterfaces, die Wörter direkt im Gehirn erraten. Die jetzt vorgestellte Arbeit entspringt zum Teil dem damaligen Vorhaben: Facebook finanzierte die UCSF-Forschung zusätzlich zu internen Projekten, die "Kommunikation in AR und VR mit der Geschwindigkeit von Sprache und der Diskretion beim Tippen" ermöglichen sollen. Außerdem stellte der Konzern sein Know-how über Künstliche Intelligenz zur Verfügung. Die Kollaboration lief mehrere Jahre.
KI ermöglicht rasante Fortschritte bei der Dekodierung des Big-Data-Brain
"Mein Forschungsteam an der UCSF arbeitet seit über einem Jahrzehnt an diesem Ziel [der Sprachneuroprothese]. Wir haben in dieser Zeit so viel darüber gelernt, wie Sprache im Gehirn verarbeitet wird, aber erst in den letzten fünf Jahren haben uns die Fortschritte beim maschinellen Lernen ermöglicht, diesen wichtigen Meilenstein zu erreichen", sagt der am Projekt beteiligte UCSF-Neurochirurge Eddie Chang. "Das in Kombination mit der Beratung und Finanzierung durch Facebook im Bereich des maschinellen Lernens hat unseren Fortschritt wirklich beschleunigt."
Forscher der Universität Stanford stellten erst im Mai ein vergleichbares KI-System vor, das einzelne Buchstaben statt ganzer Wörter aus Hirndaten entschlüsseln kann. Die Buchstaben werden dann mithilfe von Sprach-Software zu Wörtern und Sätzen umgewandelt.
Eine Versuchsperson konnte so bis zu 90 Zeichen pro Minute schreiben bei einer Präzision von bis zu 99 Prozent richtig erkannten Buchstaben. Ein durchschnittlicher Smartphone-Tipper schafft circa 115 Zeichen pro Minute.
Hirnsteuerung für VR und AR: Facebook fokussiert aufs Handgelenk
Facebook-Chef Mark Zuckerberg bezeichnet die UCSF-Forschungsarbeit als "interessanten Meilenstein". Der Datenkonzern investiert in mögliche neue Gehirn-Interfaces, stellte kürzlich ein Armband vor, das Hirnsignale in Computerbefehle umschreibt.
"Das hat es noch nie gegeben, und es ist großartig zu sehen, wie verschiedene neurowissenschaftliche Ansätze für Schnittstellen große Schritte nach vorne machen (ebenso wie unsere Arbeit, die Signale des Gehirns an die motorischen Neuronen in unseren Handgelenken zu verstehen)", kommentiert Zuckerberg die UCSF-Forschung.
Facebook stehe noch am Anfang, das Potenzial der Armband-Elektromyografie (EMG) zu erschließen, aber "wir glauben, dass sie die zentrale Eingabe für AR-Brillen sein wird", sagt Sean Keller, Forschungsleiter der Facebook Reality Labs.
Auf invasive Methoden will Facebook zwar verzichten, aber von ihnen für neue Interfaces für VR und AR lernen - und unterstützt daher entsprechende Forschung. "Wir entwickeln natürlichere, intuitivere Wege, um mit einer alltäglichen AR-Brille zu interagieren, damit wir nicht zwischen der Interaktion mit unserem Gerät und der Welt um uns herum wählen müssen", sagt Keller.
Im Zuge der Veröffentlichung der UCSF-Forschungsergebnisse gibt Facebook einen Teil der eigenen Forschungsarbeit zu Gehirnschnittstellen als Open Source frei. Am Kopf getragene Infrarot-basierte prototypische Hirnschnittstellen-Hardware will Facebook mit etablierten Forschern und Kollegen teilen, um neue Anwendungsszenarien im Assistenzbereich voranzubringen.

Details zu den Kooperationen will Facebook in der Zukunft bekannt geben. Facebook selbst will am Kopf getragene Prototypen für Hirn-Spracherkennung nicht mehr weiterentwickeln und sich auf Anwendungen für Hirnsignal-Messungen am Handgelenk fokussieren.
Das 2017 formulierte Ziel von Facebook, bis zu 100 Wörter pro Minute direkt im Gehirn auslesen zu wollen, liegt ohnehin in weiter Ferne. Selbst das jetzt vorgestellte fortschrittliche UCSF-System liegt mit 15 Wörtern pro Minute weit hinter der Zielvorgabe. Dabei hat es als invasive Methode deutliche Vorteile bei der Hirnsignalerkennung, die dennoch lange nicht optimal ist.
"Wir müssen Hardware mit einer höheren Datenauflösung entwickeln, um mehr Informationen schneller aus dem Gehirn zu erfassen. Und wir brauchen Algorithmen, die diese sehr komplexen Signale aus dem Gehirn in gesprochene Worte übersetzen können, nicht in Text, sondern tatsächlich in mündliche, hörbare gesprochene Worte", sagt Chang.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.