Mit "InternLM" meldet sich China im Wettrennen um große Sprachmodelle

InternLM ist ein großes Sprachmodell mit 104 Milliarden Parametern, das vom staatlichen chinesischen KI-Labor Shanghai AI Lab in Zusammenarbeit mit dem Überwachungsunternehmen SenseTime vorgestellt wird.
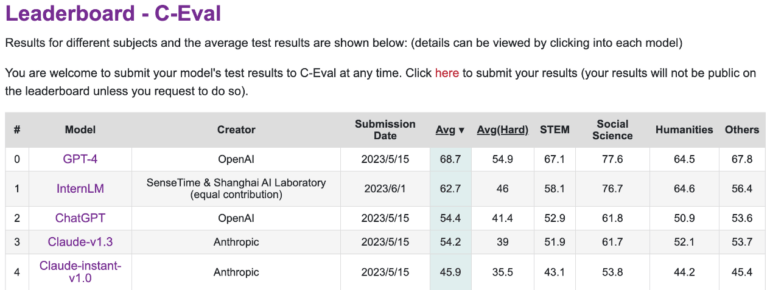
An der Entwicklung sind auch die Chinese University of Hongkong, die Fudan University und die Shanghai Jiaotong University beteiligt. Entsprechend stark ist das Modell vorwiegend in chinesischer Sprache. Hier kann es OpenAIs ChatGPT oder Anthropics Claude deutlich übertreffen.
Im C-Eval Leaderboard zur Bewertung der Fähigkeiten großer Sprachmodelle in chinesischer Sprache liegt es jedoch hinter GPT-4. InternLM wurde mit 1,6 Billionen Token trainiert und dann wie GPT-4 mittels RLHF und ausgewählten Beispielen auf menschliche Bedürfnisse verfeinert. Als Basis dient eine GPT-ähnliche Transformer-Architektur.
Für das Training wurden hauptsächlich Daten aus "Massive Web Text" verwendet und mit Enzyklopädien, Büchern, wissenschaftlichen Papieren und Code angereichert. Die Forscherinnen und Forscher entwickelten auch das Trainingssystem "Uniscale-LLM", das dank einer Reihe paralleler Trainingstechniken in der Lage sein soll, große Sprachmodelle mit mehr als 200 Milliarden Parametern auf 2048 Grafikprozessoren zuverlässig zu trainieren.
InternLM in Benchmarks auf ChatGPT-Niveau
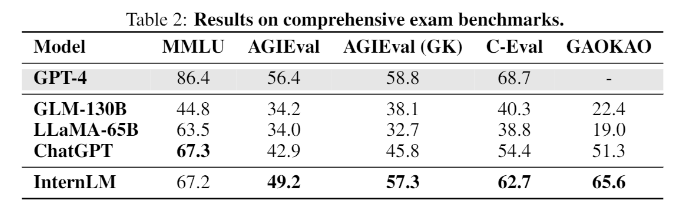
In Benchmarks mit Aufgaben, die menschlichen Tests nachempfunden sind, wie MMLU, AGIEval, C-Eval und GAOKAO-Bench, erreicht InternLM ebenfalls Leistungen auf ChatGPT-Niveau. Es bleibt jedoch hinter GPT-4 zurück, was die Forschenden auch auf das kleine Kontextfenster von nur 2000 Token zurückführen.
In anderen Bereichen wie der Wissensabfrage hängt das Modell ebenfalls hinter OpenAIs besten Modelle hinterher. Populäre Open-Source-Sprachmodelle wie Metas LLaMA mit 65 Milliarden Parametern übertrifft InternLM in den meisten getesteten Benchmarks signifikant.
Das Sprachmodell wird vom Team nicht veröffentlicht, bisher ist nur eine technische Dokumentation verfügbar. Allerdings schreibt das Team auf Github, dass es in Zukunft "mehr mit der Community teilen" möchte, ohne jedoch Details zu nennen.
Unabhängig von der Veröffentlichung gibt InternLM einen interessanten Einblick in den aktuellen Stand der chinesischen Forschung zu großen Sprachmodellen, wenn man davon ausgeht, dass das staatliche AI Labor und SenseTime hier ihre bisher beste Arbeit vorgelegt haben. "Es ist ein langer Weg zu höherer Intelligenz", schreibt das Forschungsteam.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.