RTFM: Große Sprachmodelle lernen Tools indem sie Anleitungen lesen

Sprachmodelle, die Dokumentationen lesen, lernen erfolgreich, Werkzeuge zu benutzen - in einigen Fällen erfinden sie sogar neue Methoden, zeigt eine neue Forschungsarbeit.
Große Sprachmodelle wie ChatGPT können Tools oder APIs rudimentär nutzen. Traditionell werden Sprachmodelle dafür mit einigen Beispielen trainiert, in denen die Tools verwendet werden. Bei komplexeren Tools sind solche Demonstrationen jedoch selten oder fehlen ganz. Ein Team von Forschenden der University of Washington, der National Taiwan University und Google hat eine andere Idee: Einfach die Anleitung lesen - im Internet auch gerne mit RTFM abgekürzt.
Solche Dokumentationen beschreiben genau, was ein Werkzeug tut, zum Beispiel eine API-Dokumentation. Sie sind allgemeiner als eine Demonstration der Verwendung des Tools für eine bestimmte Aufgabe und für die meisten Software-Tools über "Readme"-Daten oder API-Referenzen leicht verfügbar. Das Team ging daher davon aus, dass sie nicht nur besser skalieren, sondern auch bessere Ergebnisse liefern als Demonstrationen, da die Modelle auch auf allgemeinere und flexiblere Weise etwas über die Werkzeuge lernen.
Training mit Anleitung ermöglicht Zero-Shot-Werkzeuggebrauch
Das Team trainierte daher verschiedene Modelle für sechs verschiedene Aufgaben mit Dokumentation und Demonstration und verglich ihre Leistung. Bei ausschließlicher Verwendung von Dokumentationen war die Zero-Shot-Leistung gleich oder besser als die von Modellen, die ausschließlich von Demonstrationen lernten. Nach einer Skalierung auf einen Datensatz von 200 Tool-Anleitungen übertraf das erste Modell dann das zweite deutlich.
Im Bereich der Bildverarbeitung war das Modell in der Lage, komplexe Bildverarbeitungs- und Videoverfolgungsfunktionen ohne weitere Demonstration auszuführen, indem es aus der Dokumentation neuer, hochmoderner Bildverarbeitungsmodule lernte. Als besonders bemerkenswert hebt das Team hervor, dass das Modell mit Ausgangstools und Dokumentationen in der Lage war, kürzlich veröffentlichte Bildverarbeitungstechniken wie Grounded-SAM und Videoverfolgung mit Track Anything zu reproduzieren - dies zeige das Potenzial der Methode für die automatische Wissensentdeckung.
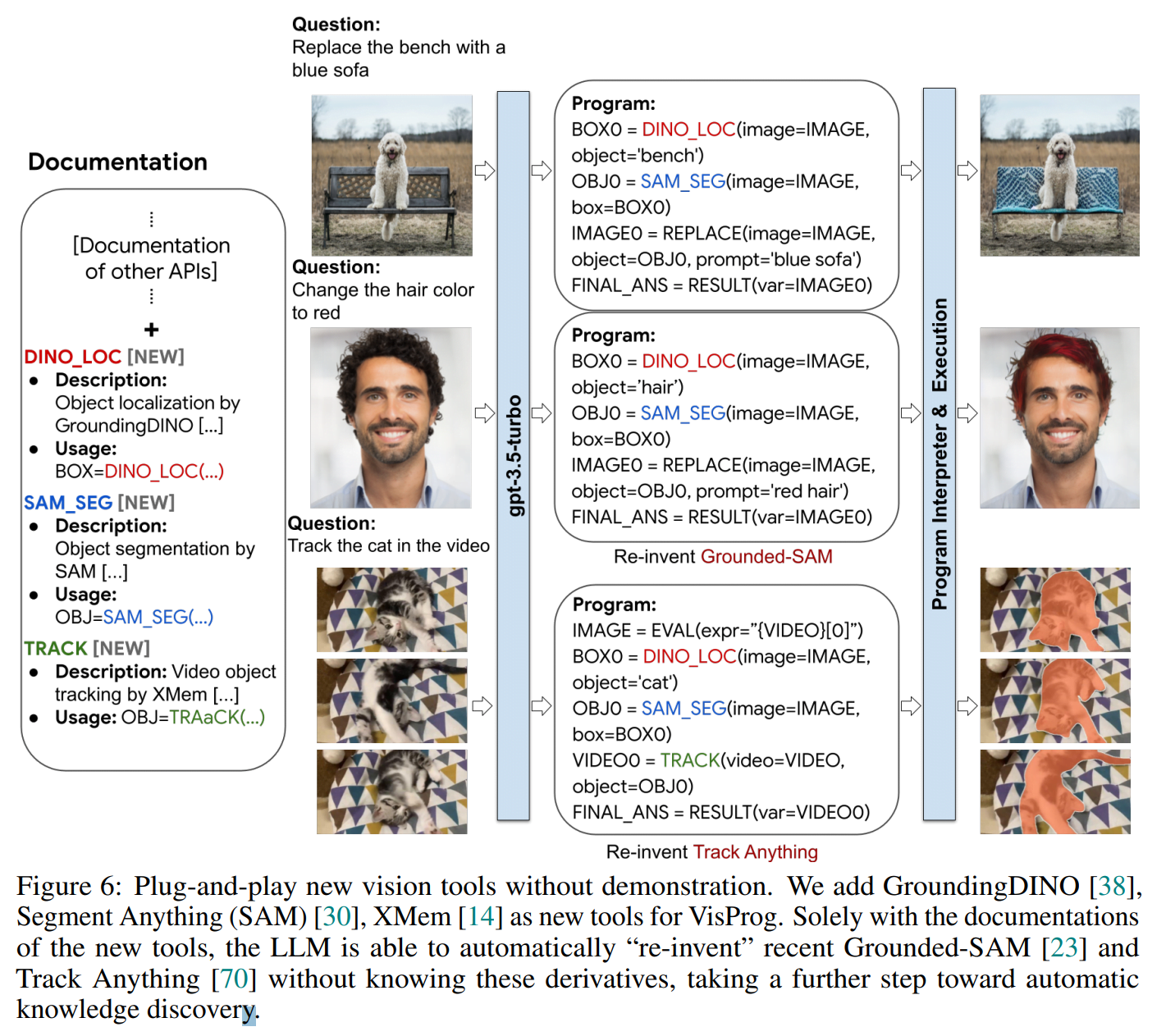
"Insgesamt zeigen wir eine neue Perspektive der Werkzeugnutzung mit großen Sprachmodelle auf, indem wir uns auf ihre internen Planungs- und Schlussfolgerungsfähigkeiten mit Dokumenten konzentrieren, anstatt ihr Verhalten explizit mit Demos zu steuern", heißt es im Paper.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.