Grokking im Machine Learning: Wenn stochastische Papageien Modelle lernen

KI-Modelle verallgemeinern unter bestimmten Umständen über die Trainingsdaten hinaus. Dieses Phänomen wird in der KI-Forschung als "Grokking" bezeichnet - Google gibt nun Einblick in aktuelle Erkenntnisse.
Während des Trainings scheinen KI-Modelle manchmal plötzlich ein Problem zu "verstehen", obwohl sie zunächst nur Trainingsdaten auswendig gelernt haben. In der KI-Forschung wird dieses Phänomen als "Grokking" bezeichnet, eine Wortschöpfung des amerikanischen Schriftstellers Robert A. Heinlein, die vor allem in der Computerkultur verwendet wird und eine Art tiefes Verstehen beschreibt.
Beim Grokking in KI-Modellen gehen die Modelle plötzlich von der einfachen Reproduktion der Trainingsdaten zur Entdeckung verallgemeinerbarer Lösungen über - anstelle eines stochastischen Papageis entsteht also ein KI-System, das tatsächlich ein Modell des Problems bildet, um Vorhersagen zu treffen.
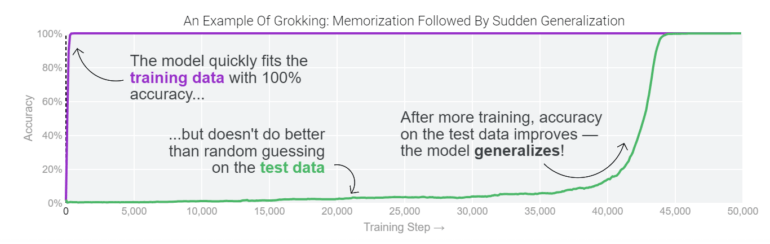
Forschende bemerkten Grokking erstmals im Jahr 2021, als sie kleine Modelle für algorithmische Aufgaben trainierten. Die Modelle passten sich durch Auswendiglernen an die Trainingsdaten an, zeigten aber bei Testdaten eine zufällige Leistung. Nach längerem Training verbesserte sich plötzlich die Genauigkeit der Testdaten, da die Modelle begannen, über die Trainingsdaten hinaus zu verallgemeinern. Seitdem wurde das Phänomen in verschiedenen Tests reproduziert, zum Beispiel in Othello-GPT.
Google-Team zeigt, dass "Grokking" ein "kontingentes Phänomen" ist
Grokking hat großes Interesse bei KI-Forschenden geweckt, die besser verstehen wollen, wie neuronale Netze lernen". Denn Grokking weist darauf hin, dass Modelle eine unterschiedliche Lerndynamik beim Einprägen und beim Verallgemeinern aufweisen können und ein Verständnis dieser Dynamik könnte wichtige Erkenntnisse darüber liefern, wie neuronale Netze lernen.
Während es zunächst in kleinen, nur auf eine Aufgabe trainierten Modellen beobachtet wurde, deuten neuere Arbeiten darauf hin, dass Grokking auch in größeren Modellen auftreten und in einigen Fällen sogar zuverlässig vorhergesagt werden kann. Die Erkennung solcher Grokking-Dynamiken in großen Modellen bleibt jedoch weiter eine Herausforderung.
In einem neuen Beitrag geben Google-Forschende nun einen visuell gut aufbereiteten Einblick in das Phänomen und die aktuelle Forschung. Das Team hat mehr als 1.000 kleine Modelle mit unterschiedlichen Trainingsparametern für algorithmische Aufgaben trainiert und zeigt, dass "Grokking ein kontingentes Phänomen ist - es verschwindet, wenn die Modellgröße, der Gewichtsabfall, die Datengröße und andere Hyperparameter nicht genau richtig sind.
Grokking "Grokking" könnte große KI-Modelle verbessern
Nach Ansicht des Teams sind noch viele Fragen offen, etwa welche Modellbeschränkungen Grokking zuverlässig verursachen, warum die Modelle zunächst das Auswendiglernen der Trainingsdaten bevorzugen und inwieweit die in der Forschung verwendeten Methoden zur Untersuchung des Phänomens in kleinen Modellen auch auf große Modelle anwendbar sind.
Fortschritte im Verständnis von Grokking könnten in Zukunft das Design großer KI-Modelle beeinflussen, sodass diese zuverlässig und schnell über die Trainingsdaten hinaus verallgemeinern.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.