FreeControl ermöglicht mehr Kontrolle über Stable Diffusion - ohne Training

Bildgeneratoren können mit mehr als nur Textprompts gesteuert werden, z.B. mit ControlNet. Diese Methoden erforderten in der Vergangenheit jedoch einen hohen Trainingsaufwand. FreeControl soll das ändern.
Forschende der University of California in Los Angeles, der University of Wisconsin-Madison und Innopeak Technology Inc. haben eine neue Methode zur kontrollierbaren Text-zu-Bild-Generierung (T2I) entwickelt, die sie "FreeControl" nennen.

FreeControl benötigt kein explizites Training
FreeControl soll Benutzern eine fein abgestimmte räumliche Kontrolle über Diffusionsmodelle bieten. Im Gegensatz zu früheren Ansätzen, die zusätzliche Module für jeden Typ von räumlichen Bedingungen, Modellarchitekturen und Checkpoints erfordern, braucht FreeControl dieses explizite Training nicht.
FreeControl extrahiert zunächst eine Reihe von Schlüsselmerkmalen aus Beispielbildern. Diese Beispielbilder bestehen aus einem Eingabebild, das den Bildaufbau vorgibt, einem generierten Bild, das automatisch aus dem jeweiligen Prompt generiert wird, und einer weiteren Variante, bei der der Prompt so angepasst wird, dass nur das wesentliche Konzept - z.B. Mann - und nicht alle Details - z.B. Ein Lego-Mann hält eine Rede - enthalten sind. Die extrahierten Merkmale umfassen also Bildkomposition, Inhalt und Stil sowie das wesentliche Konzept. Zusammen leiten sie die Generierung des endgültigen Bildes.
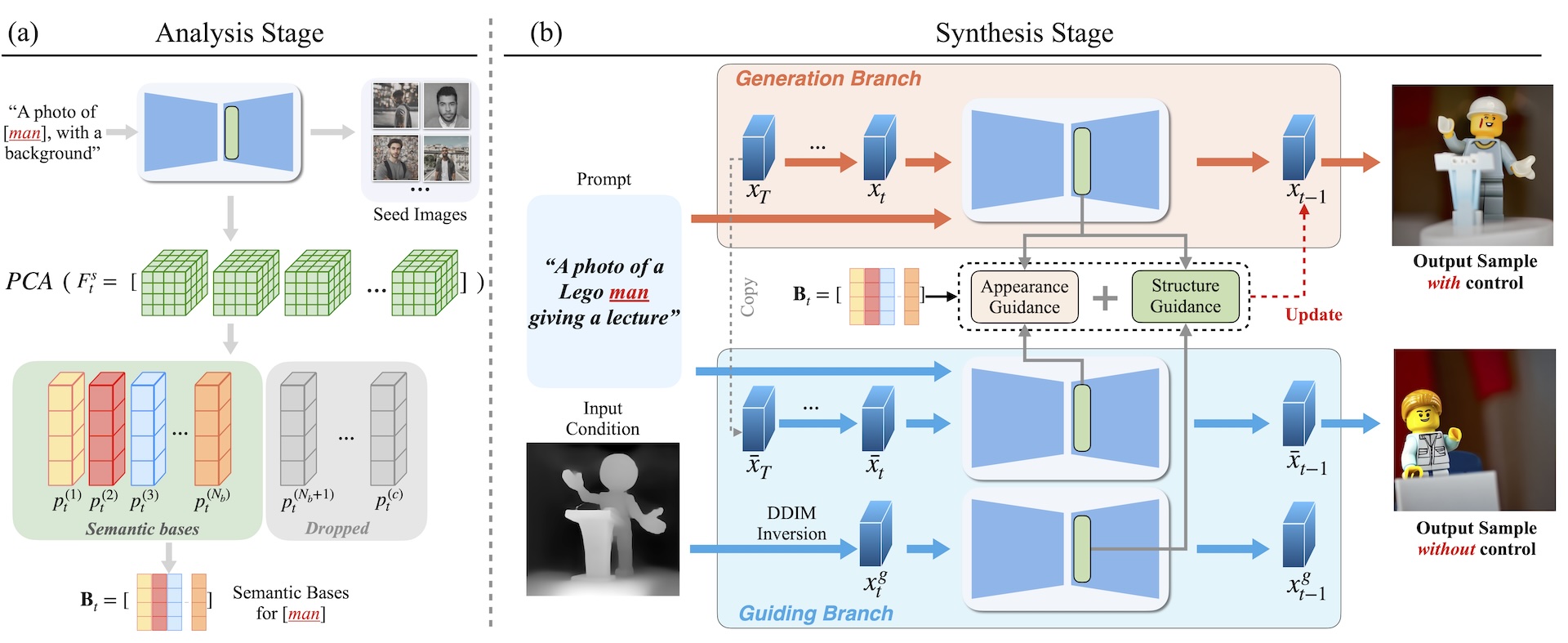
Auch für Bild-zu-Bild geeignet
FreeControl generiert den Autor:innen zufolge hochwertige Bilder und soll bessere Ergebnisse erzielen als andere Methoden, die versuchen ohne Training die Bildgenerierung zu leiten. Die FreeControl-Methode könne außerdem problemlos für Bild-zu-Bild-Prompting angepasst werden.
Mit ControlNet gab es seit Frühjahr 2023 einen ersten Ansatz, um die Ausgabe von Stable-Diffusion-Modellen mit anderen Bedingungen als nur Textprompts zu kontrollieren. Einen Schritt weiter ging das kurz darauf veröffentlichte GLIGEN, das Positions- und Größenangaben der im Bild gewünschten Objekte aufnahm.
FreeControl scheint eine logische, noch mächtigere Weiterentwicklung dieser Ideen zu sein, die einerseits unabhängig von ressourcenintensivem Training funktioniert und andererseits eine ganze Reihe verschiedener Eingabebedingungen akzeptiert.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.