Metas "Self-Rewarding Language Models" sollen menschliches Feedback überflüssig machen

Die "Self-Rewarding Language Models" von Meta sollen sich selbst verbessern und von Menschen abhängige Feedbackmethoden ergänzen oder in Zukunft ganz ersetzen. Ein erster Test zeigt das Potenzial, aber es sind noch viele Fragen offen.
Forscher von Meta und der New York University haben ein neues Konzept für Sprachmodelle vorgestellt, die sogenannten "Self-Rewarding Language Models". Diese Modelle sind in der Lage, während des Trainings ihre eigenen Belohnungen zu generieren, was zu einer kontinuierlichen Verbesserung ihrer Leistung führt. Damit stehen sie im Gegensatz zu herkömmlichen Ansätzen wie dem Reinforcement Learning mit menschlichem Feedback (RLHF) oder der Direct Preference Optimization (DPO), bei denen das Belohnungssignal von Menschen kommt.
Als Motivation für ihre Arbeit nennen die Forscher die Überwindung einer zentralen Einschränkung solcher auf menschliches Feedback angewiesenen Methoden: Sie sind durch die Leistungsfähigkeit und die Perspektive des menschlichen Urteils begrenzt. Die Idee hinter selbstbelohnenden Modellen ist es, diese Beschränkung zu überwinden, indem die Modelle lernen, sich selbst zu bewerten und zu verbessern, potenziell über das Niveau hinaus, das durch menschliches Feedback erreicht werden kann.
Llama 2 70B zeigt als Self-Rewarding LM deutlich verbesserte Leistung
Die Methode beginnt mit einem vortrainierten Sprachmodell, in diesem Fall Metas Llama 2 70B. Dieses Modell verfügt bereits über eine umfangreiche Wissensbasis und die Fähigkeit, auf eine Vielzahl von Anfragen zu reagieren. Zunächst generiert das Modell Antworten auf Anfragen und bewertet diese selbst nach Kriterien, die in einem Prompt festgelegt sind. Dieses Feedback nutzt das Modell dann als Trainingsdaten zur Verbesserung zukünftiger Generierungen, ähnlich wie bei DPO, jedoch ohne menschlichen Input. Auf Basis dieser Selbstbewertung lernt das Modell dann, bessere Antworten zu geben - aber auch, seine eigenen Antworten besser zu bewerten und damit wiederum zukünftige Antworten zu verbessern.
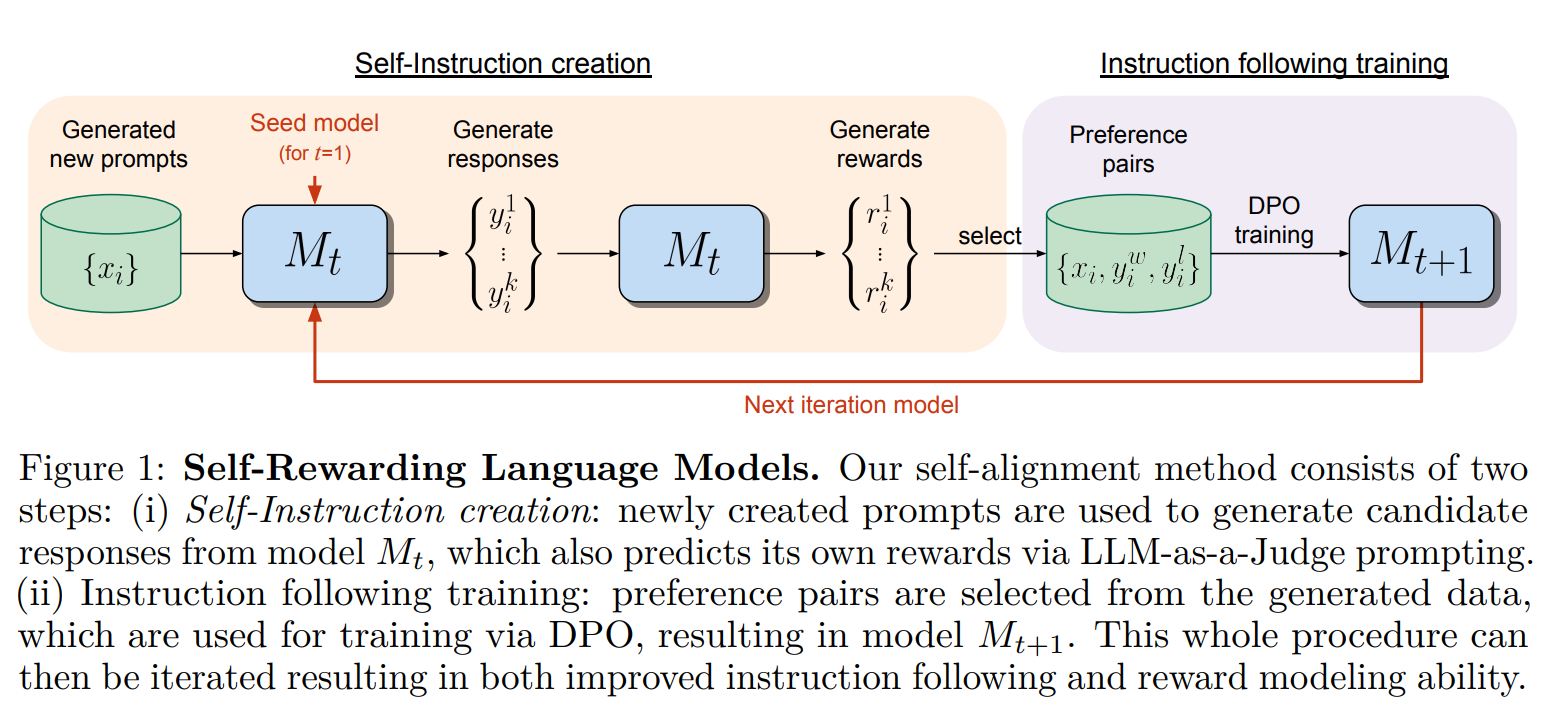
Da das Modell ständig durch die Bewertung seiner eigenen Antworten lernt, kann es sich also theoretisch immer weiter verbessern, ohne auf menschliche Daten oder Einschränkungen angewiesen zu sein. Wo genau die Grenzen dieses Prozesses liegen, will das Team weiter untersuchen.
In den ersten Experimenten zeigten die drei iterativ aufeinander aufbauenden, selbst belohnenden Modelle jedoch deutliche Verbesserungen im Befolgen von Anweisungen - zumindest im AlpacaEval 2.0 Benchmark, den das Team für die Evaluierung verwendete und in dem GPT-4-Turbo die Qualität der Antworten bewertet. Im Benchmark schnitt die Llama 2 70B Variante besser ab als mehrere bekannte Modelle, darunter Claude 2, Gemini Pro und GPT-4 0613.
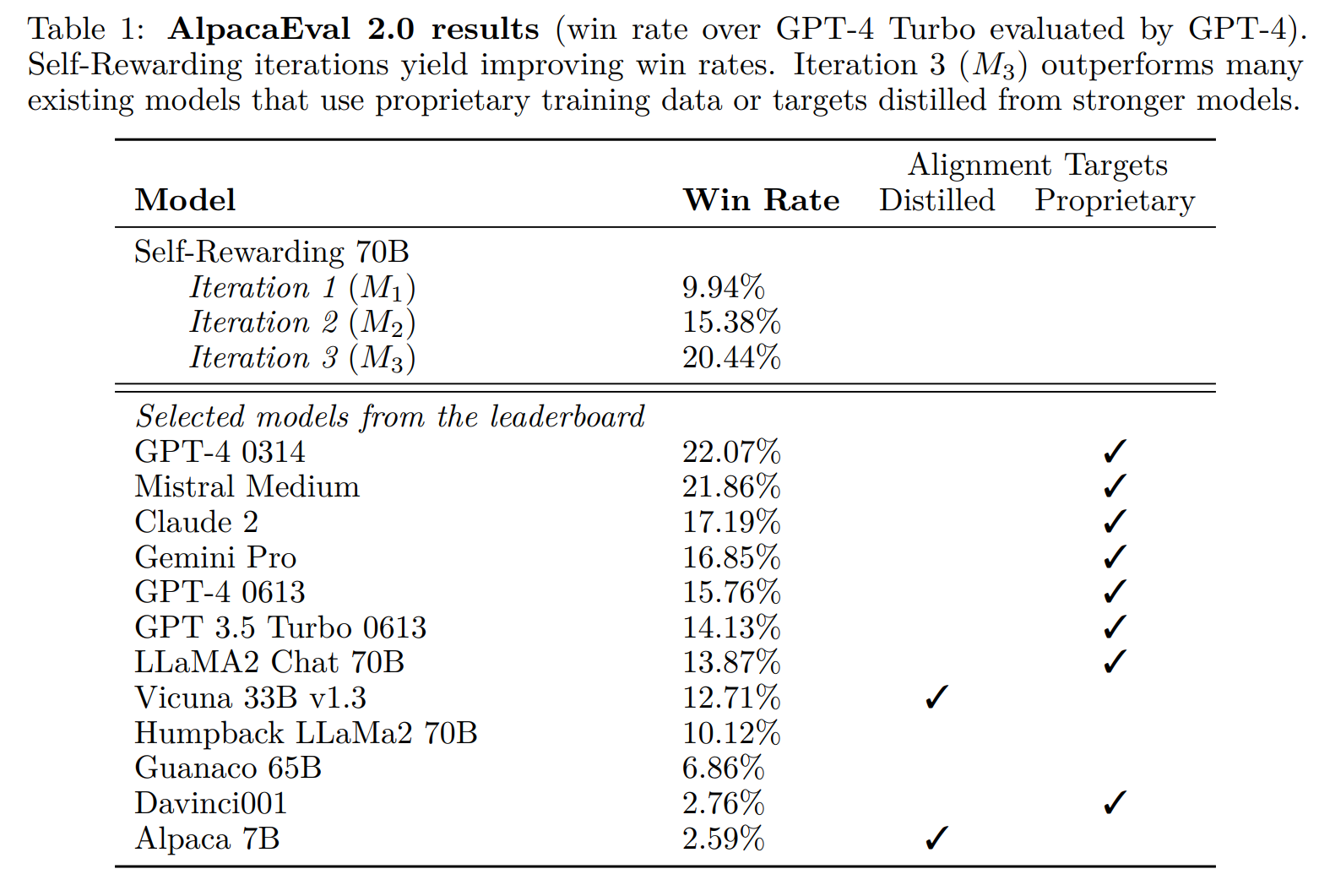
Es ist unklar, ob ein hoher Wert in diesem Benchmark tatsächlich einer guten Leistung in der Praxis entspricht, zumal GPT-4 Modelle mit längeren Ausgaben und solche, die mit GPT-4-Ausgaben trainiert wurden, in der Bewertung bevorzugt. Tatsächlich stellt das Team fest, dass die Outputs ihrer Modelle iterativ länger werden.
Das Team plant daher, die Methode weiter zu untersuchen, menschliche Bewertungen der Outputs durchzuführen und zu prüfen, ob die Methode anfällig für "reward-hacking" ist, bei dem das Modell lernt, Lücken oder Schwächen im Belohnungssystem auszunutzen, um eine höhere Belohnung zu erhalten, ohne sich in der eigentlichen Aufgabe zu verbessern.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.