Roboter läuft dank Training nach dem Sprachmodell-Prinzip sicher durch San Francisco

Eine Studie der University of California, Berkeley, ermöglicht es Robotern, sich nach dem Prinzip der Wortvorhersage von Sprachmodellen fortzubewegen. Dieser Ansatz könnte den Weg für eine neue Generation von Robotern ebnen, die mit minimalem Trainingsaufwand in komplexen Umgebungen navigieren können.
In ihrem Artikel "Humanoid Locomotion as Next Token Prediction" behandeln die Forscher die komplexe Aufgabe der Roboterbewegung als Sequenzvorhersageproblem, ähnlich der Vorhersage des nächsten Wortes in der Sprachgenerierung.
Dazu verwenden sie dieselbe Transformer-Technologie, die den Durchbruch bei großen Sprachmodellen brachte, und passen sie für die Vorhersage von Roboterschritten an.
Die Schritte des Roboters werden als "Token" behandelt, vergleichbar mit Wörtern in einem Satz. Durch autoregressive Vorhersage dieser Token lernt der Transformer, die nächste Bewegung auf der Grundlage der vorherigen Bewegungssequenz vorherzusagen. Der Roboter sagt also jeden nächsten Schritt auf der Grundlage der bereits ausgeführten Schritte voraus.
Das Modell wurde mit einer Mischung aus verschiedenen Datenquellen trainiert, darunter menschliche Bewegungsdaten und YouTube-Videos. Nach Angaben der Forscherinnen und Forscher war der Roboter in der Lage, durch die Straßen von San Francisco zu navigieren, ohne zuvor spezifische Beispiele für diese Umgebung gesehen zu haben (zero-shot) - und das nur mit einem Training auf der Grundlage von 27 Stunden Laufdaten.
Das Modell sei auch in der Lage, Befehle auszuführen, die es im Training nicht gesehen habe, wie rückwärtszulaufen. Dank dieser Anpassungsfähigkeit könnte das Modell Roboter in die Lage versetzen, sich flexibel in komplexen realen Umgebungen zu bewegen - und das mit einem Bruchteil des sonst erforderlichen Trainingsaufwands.
Vorhersagen helfen, Trainingsdaten mit multimodalen Daten zu optimieren
Der Ansatz der Forscher eignet sich besonders für den Umgang mit unterschiedlichen Datenquellen wie Videos, Sensormessungen oder auch Computersimulationen. Diese Daten werden in ein gemeinsames Format konvertiert, damit der Transformer sie verarbeiten kann.
Das Forscherteam nutzte für das Robotertraining eine Vielzahl unterschiedlicher Daten: von kompletten Sequenzen aus neuronalen Netzen über modellbasierte Steuerungen ohne Aktionen hin zu annähernd übertragenen Motion-Capture-Daten von Menschen und aus Internetvideos rekonstruierten menschlichen Posen.
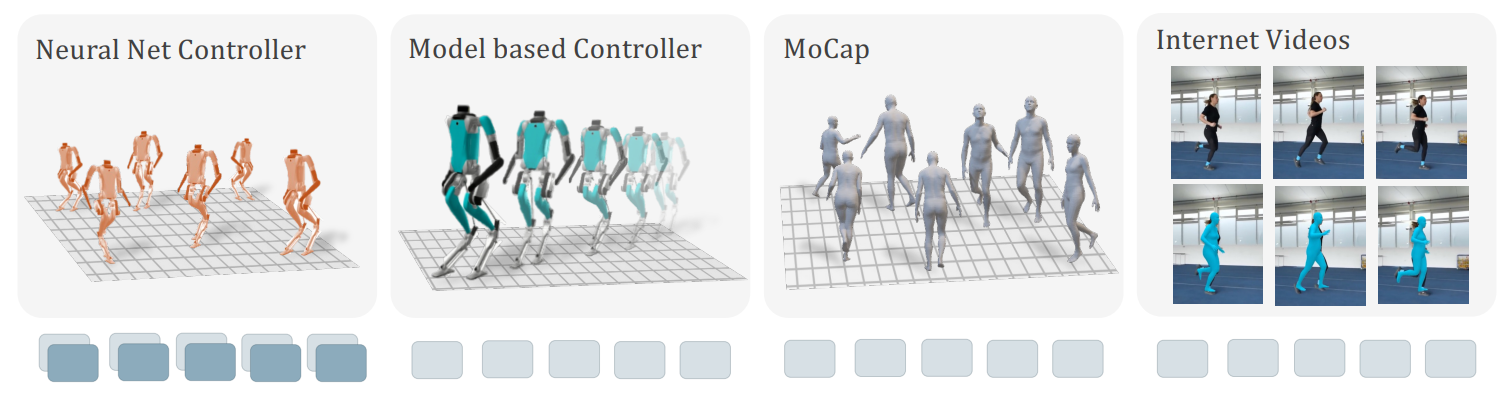
Auch unvollständige Daten wurden sinnvoll genutzt, indem fehlende Informationen durch lernfähige Maskentoken ersetzt wurden, die eine Vorhersage der verbleibenden Informationen ermöglichten. Bei YouTube-Videos nutzten die Forscher die Gelenkstellungen des menschlichen Körpers, um die Bewegung auf den humanoiden Roboter zu übertragen.
Unsere Kernaussage ist, dass wir auch dann, wenn eine Trajektorie unvollständig ist, d.h. wenn ein Teil der sensorischen oder motorischen Information fehlt, daraus lernen können, indem wir die vorhandene Information vorhersagen und die fehlenden Token durch lernfähige Maskentoken ersetzen.
Aus dem Paper
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.