GPT-4o: Diese beeindruckenden Fähigkeiten stecken noch im neuen KI-Modell von OpenAI

Bei der Präsentation von GPT-4o hat sich OpenAI hauptsächlich auf die Sprach- und Audiofunktion konzentriert. Die Besonderheit von GPT-4 ist jedoch, dass es von Grund auf multimodal ist.
GPT-4o akzeptiert jede Kombination von Text, Audio, Bild und Video als Eingabe und erzeugt jede Kombination von Text, Audio und Bild als Ausgabe. OpenAI demonstrierte nach der Enthüllung von GPT-4o einige der neuen Möglichkeiten.
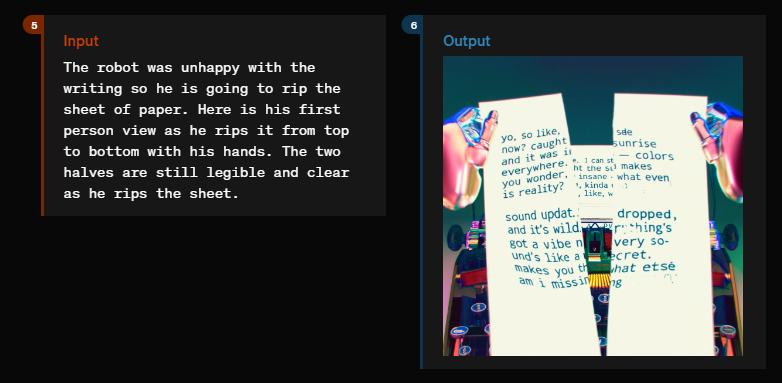
So ist das Modell beispielsweise in der Lage, visuelle Erzählungen zu generieren. In einem Beispiel schreibt ein Roboter mehrere Tagebucheinträge auf einer Schreibmaschine.
Das Modell kann die Szene weiterentwickeln und zeigen, wie der Roboter die Seite zerreißt, weil er unzufrieden mit dem Geschriebenen ist. Dabei steht die Geschichte auf einem Schreibmaschinenblatt, das auf einem Bild abgebildet ist.
Es ist auch möglich, detaillierte und konsistente Charakterdesigns für Filme oder Geschichten zu erstellen. In einer Demo entsteht so der Roboter Geary, der Baseball spielt, programmiert, Fahrrad fährt und kocht, oder die Postbotin Sally, die Briefe austrägt und von einem Golden Retriever verfolgt wird.

GPT-4o beherrscht zudem unterschiedliche kreative typografische Stile. Es kann ein Gedicht etwa direkt als gestaltetes Blatt Papier ausgeben oder sogar neue Schriftarten entwickeln.

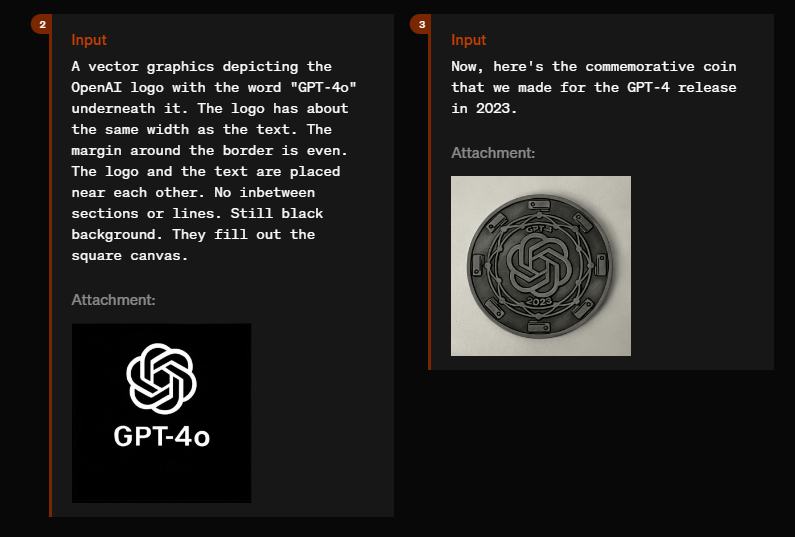
GPT-4o beherrscht auch die Gestaltung von Gedenkmünzen, wie sie z.B. anlässlich der Veröffentlichung von GPT-4 im Jahr 2023 herausgegeben werden. Auch futuristische oder altviktorianische Schriften sind möglich.
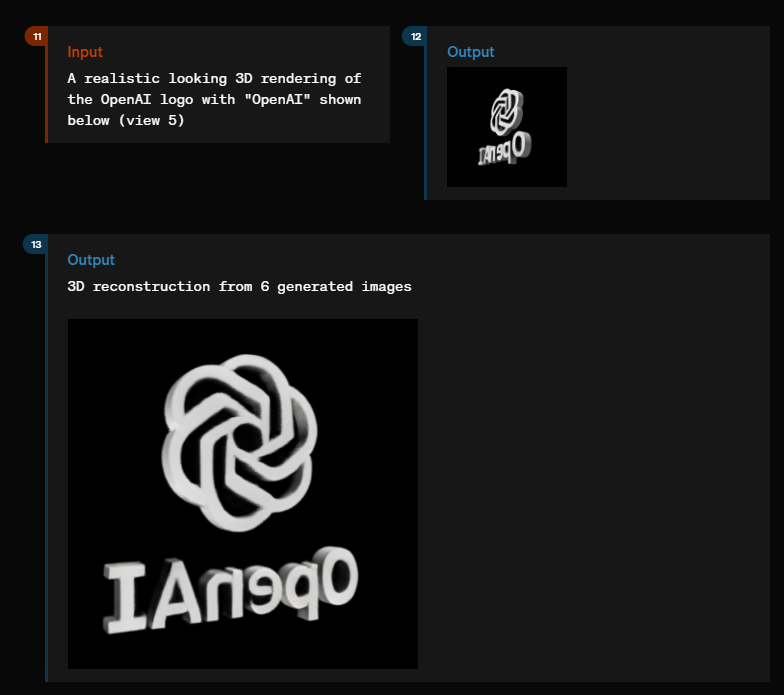
Im Bereich der 3D-Modellierung kann GPT-4o realistische 3D-Renderings von Objekten wie dem OpenAI-Logo oder einer Seehund-Skulptur erzeugen und diese aus verschiedenen Blickwinkeln darstellen. Dafür reichen einige wenige Eingabebilder.
Schließlich zeigen die Demos, dass das Modell in der Lage ist, kausale Zusammenhänge in Bildern zu verstehen. In einem Beispiel werden drei Würfel mit den Buchstaben "G", "P" und "T" gestapelt. Dabei muss einerseits die Reihenfolge der Buchstaben (G, P, T) und andererseits die Reihenfolge der Farben (rot, blau, grün) eingehalten werden.
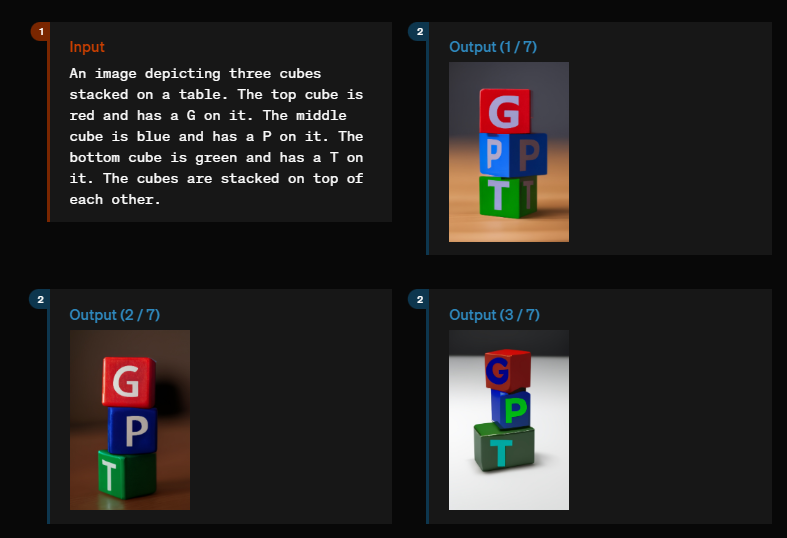
Dieser Test galt lange Zeit als Maßstab für das Weltverständnis von Bildgeneratoren. GPT-4o scheint ihn, zumindest in dieser speziellen Demonstration, über viele Versuche hinweg zuverlässig zu bestehen. Nur in einem Beispiel ist der mittlere Block rot und der obere blau.
Andere Beispiele sind das Platzieren von Logos auf Objekten, das Transkribieren und Zusammenfassen von Audio- und Videomaterial oder das Umwandeln von Fotos von Personen in neue Situationen wie Kinoplakate oder Stile wie Karikaturen.

Die Fülle an Fähigkeiten macht deutlich: GPT-4o ist ein Schritt in Richtung eines Omni-Modells, das Text, Bild, Audio und Video versteht und generiert.
Prafulla Dhariwal, Leiter der Omni-Entwicklung, bezeichnet Omni als das erste "vollständig native multimodale Modell" und die Einführung als "große, unternehmensweite Anstrengung".
Die neue Tokenisierung deutet darauf hin, dass das Modell von Grund auf neu entwickelt wurde. GPT-4o könnte eine Art Vorläufer von GPT-5 sein, das nun als eigenständiges Modell veröffentlicht wurde. Spekulationen zufolge ist Omni schon seit 2022 in Arbeit.
Wann und in welchem Umfang die einzelnen multimodalen Fähigkeiten in ChatGPT oder über API verfügbar sind, und wie sie sich im Vergleich zu Standalone-Modellen etwa für 3D- oder Bildgenerierung schlagen, bleibt abzuwarten.
Wie OpenAI selbst sagt: "Wir kratzen immer noch an der Oberfläche dessen, was das Modell kann und wo seine Grenzen liegen."
OpenAI verspricht einen iterativen Rollout, zunächst sollen die Audio-Fähigkeiten kommen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.