Microsofts VALL-E 2 klont Stimmen in Sekunden - und bleibt vorerst unter Verschluss

Ein Forschungsteam bei Microsoft hat mit VALL-E 2 ein deutlich verbessertes KI-System für die Sprachsynthese vorgestellt. Es glaubt nicht daran, dass die Welt schon bereit für die Veröffentlichung ist.
Laut dem Team ist es das erste System, das bei der Generierung von Sprache aus Text die Leistung von Menschen erreicht - und das sogar für unbekannte Sprecher:innen, von denen nur eine kurze Sprachprobe vorliege. Selbst komplexe Sätze oder solche mit vielen Wiederholungen seien damit verlässlich zu erstellen.
Kommerziell verfügbare Software wie die von ElevenLabs war bislang schon in der Lage, Stimmen zu klonen, benötigte dafür aber eher Referenzmaterial in der Größenordnung von Stunden. VALL-E 2 schafft es hingegen mit wenigen Sekunden.
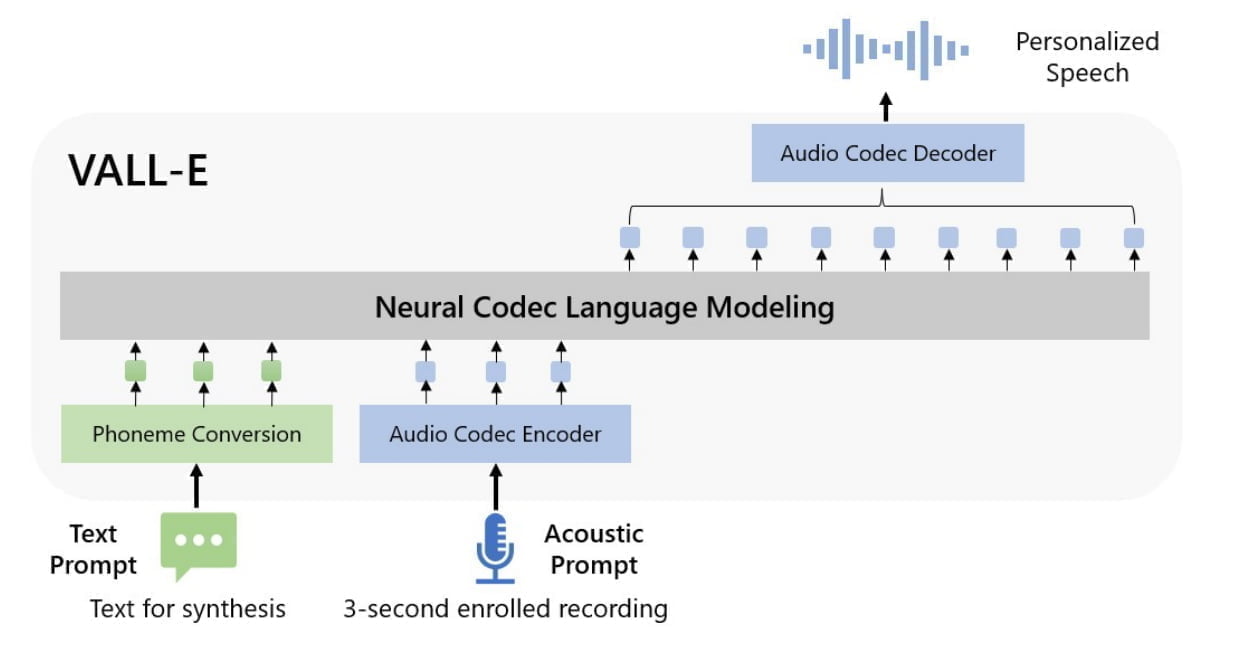
VALL-E 2 baut auf seinem Vorgänger VALL-E von Anfang 2023 auf und nutzt neuronale Codec-Sprachmodelle, um Sprache zu erzeugen. Diese Modelle lernen, Sprache als Abfolge von Codes darzustellen, ähnlich wie bei digitaler Audiokompression. Zwei entscheidende Verbesserungen machen den Durchbruch möglich.
VALL-E 2 liefert zwei zentrale Neuerungen
Erstens verwendet VALL-E 2 eine neuartige "Repetition Aware Sampling"-Methode für den Dekodierprozess, bei dem die gelernten Codes in hörbare Sprache umgewandelt werden. Dabei passt sich die Auswahl der Codes dynamisch an deren Wiederholung in der bisherigen Ausgabesequenz an.
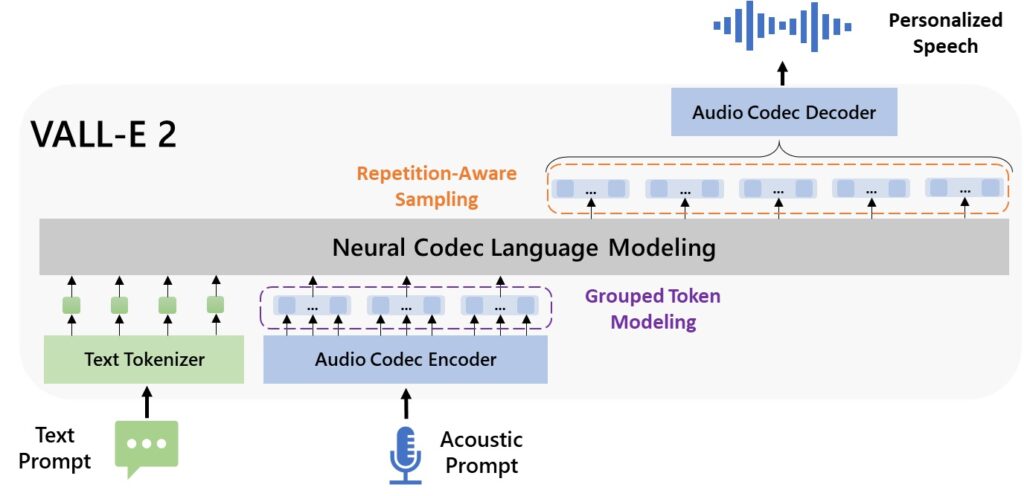
Statt wie VALL-E durchgängig zufällig aus den möglichen Codes auszuwählen, wechselt VALL-E 2 intelligent zwischen zwei Sampling-Methoden: Beim "Nucleus Sampling" werden nur die wahrscheinlichsten Codes berücksichtigt, während beim zufälligen Sampling alle Möglichkeiten gleichberechtigt sind. Durch den adaptiven Wechsel wird die Stabilität des Dekodierprozesses deutlich erhöht und Probleme wie Endlosschleifen vermieden.
Die zweite zentrale Neuerung ist die Modellierung der Codec-Codes in Gruppen statt einzeln. VALL-E 2 fasst mehrere aufeinanderfolgende Codes zusammen und verarbeitet sie gemeinsam als eine Art "Frame". Durch diese Gruppierung der Codes wird die Eingabesequenz für das Sprachmodell verkürzt, was die Verarbeitung beschleunigt. Gleichzeitig verbessert dieser Ansatz auch die Qualität der generierten Sprache, da er die Verarbeitung sehr langer Zusammenhänge vereinfacht.
Ein dreisekündiges Sample als Stimmenreferenz.
Prompt: They moved thereafter cautiously about the hut groping before and about them to find something to show that Warrenton had fulfilled his mission.
In Experimenten auf den Datensätzen LibriSpeech und VCTK übertraf VALL-E 2 die Leistung von Menschen in Bezug auf Robustheit, Natürlichkeit und Ähnlichkeit der generierten Sprache signifikant. Dabei reichten schon 3-Sekunden-Aufnahmen der Zielsprecher aus. Mit längeren Sprachproben von 10 Sekunden erzielte das System hörbar bessere Ergebnisse. Alle Beispiele hat Microsoft auf dieser Website veröffentlicht.
Ein dreisekündiges Sample als Stimmenreferenz.
Die synthetisierte Stimme mit 3-Sekunden-Sample.
Die synthetisierte Stimme mit 10-Sekunden-Sample.
Die Forscher:innen betonen, dass für das Training von VALL-E 2 lediglich Paare aus Sprachaufnahmen und deren Verschriftlichung benötigt werden. Das erleichtere die Datenaufbereitung im Vergleich zu Ansätzen, die zusätzliche Informationen wie zeitliche Zuordnungen erfordern.
Keine Veröffentlichung, da zu hohe Missbrauchsgefahr
VALL-E 2 könnte den Forschenden zufolge in vielen Bereichen wie Bildung, Unterhaltung, Barrierefreiheit oder Übersetzung zum Einsatz kommen. Die Forscher weisen aber auch auf offensichtliche Risiken des Missbrauchs hin, etwa Stimmen ohne die Zustimmung der Sprecher:in zu imitieren. Deswegen handelt es sich derzeit noch um ein reines Forschungsprojekt und Microsoft habe keine Pläne, VALL-E 2 in ein Produkt zu integrieren oder den Zugang für die Öffentlichkeit zu erweitern.
Zuvor sollte ihrer Meinung nach ein Protokoll entwickelt werden, das sicherstellt, dass die zu hörende Person der Synthetisierung zugestimmt hat sowie ein Verfahren zur digitalen Kennzeichnung solcher Inhalte. Dieser Vorschlag ist mutmaßlich von der Entwicklung in der Branche der KI-Bildmodelle inspiriert, wo Wasserzeichen wie C2PA Einzug halten. Das bestehende Problem, KI-Inhalte verlässlich als solche zu erkennen, lösen sie aber nicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.