RUBICON: Neues Bewertungssystem für KI-Unterhaltungen in der Softwareentwicklung

Forscher von Microsoft haben mit RUBICON eine Technik entwickelt, um die Qualität von Unterhaltungen zwischen Softwareentwicklern und KI-Assistenten automatisiert zu bewerten. Das System generiert dafür maßgeschneiderte Bewertungskriterien.
Die Bewertung von KI-Assistenten wie GitHub Copilot stellt Werkzeugentwickler vor Herausforderungen, denn die Qualität der Interaktionen zwischen Mensch und KI lässt sich aufgrund der Vielfalt an Aufgaben und der Komplexität der Unterhaltungen nur schwer einschätzen.
Forscher von Microsoft stellen nun mit RUBICON eine Technik vor, um die Qualität solcher domänenspezifischen Unterhaltungen automatisiert zu bewerten. RUBICON steht für "Rubric-based Evaluation of Domain Specific Human-AI Conversations" und wurde auf der AIware-Konferenz 2024 präsentiert.
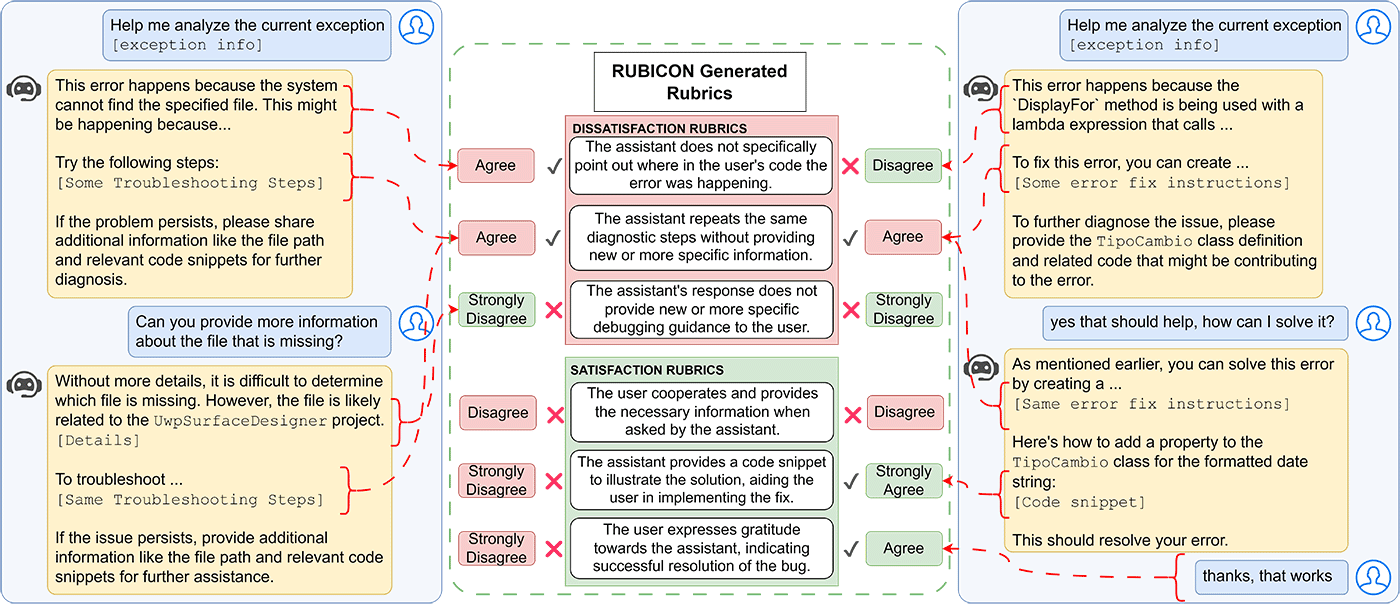
Das System besteht aus drei Hauptkomponenten: der Generierung von Bewertungskriterien, der Auswahl der relevantesten Kriterien und der eigentlichen Bewertung der Unterhaltungen. Zur Generierung der Kriterien analysiert RUBICON zunächst einen Trainingsdatensatz aus Unterhaltungen, die als positiv oder negativ gekennzeichnet sind.
Dabei identifiziert es Muster, die auf Zufriedenheit oder Unzufriedenheit der Nutzer hindeuten. Im Gegensatz zu früheren Ansätzen bezieht RUBICON dabei Prinzipien für effektive Kommunikation, wie die Grice'schen Konversationsmaximen (welche vier Dimensionen der Gesprächseffektivität erfassen: Quantität, Qualität, Relevanz und Art und Weise), und domänenspezifisches Wissen mit ein.
Auf dem Weg zur besseren Coding-KI
So werden die generierten Kriterien auf die jeweilige Anwendungsdomäne zugeschnitten. In einem zweiten Schritt wählt RUBICON mittels eines iterativen Verfahrens eine Teilmenge der generierten Kriterien aus, die am besten zwischen positiven und negativen Unterhaltungen unterscheiden können. Schließlich bewertet ein großes Sprachmodell die zu testenden Unterhaltungen anhand der ausgewählten Kriterien und eines ermittelten Schwellenwerts.
Die Forscher evaluierten RUBICON anhand von 100 Unterhaltungen zwischen Entwicklern und einem KI-Assistenten für das Debugging in C#. Dabei zeigte sich, dass die von RUBICON generierten Kriterien eine deutlich bessere Unterscheidung zwischen positiven und negativen Unterhaltungen ermöglichten als Kriterien früherer Verfahren oder manuell erstellte Kriterien.
Mit RUBICON konnten 84 Prozent der Unterhaltungen mit einer Präzision von über 90 Prozent als positiv oder negativ klassifiziert werden. Frühere Verfahren erreichten maximal 64 Prozent.
Laut Micorosft wurde RUBICON bereits erfolgreich in einer beliebten Entwicklungsumgebung eines großen Softwareunternehmens eingesetzt, um zwei KI-Assistenten zu überwachen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.