LongWriter: Aktuelle Sprachmodelle können viel längere Texte generieren als bisher angenommen

Forscher haben eine Methode entwickelt, um die Ausgabelänge von KI-Sprachmodellen auf über 10.000 Wörter zu erweitern. Bisher war eine Grenze von 2.000 üblich.
Heutige Sprachmodelle sind zwar in der Lage, Eingaben von Hunderttausenden oder sogar Millionen von Token zu verarbeiten, erzeugen aber ohne externe Eingriffe keine Ausgaben, die länger als bescheidene 2.000 Wörter sind.
Laut einer neuen Studie liegt das vor allem an den Trainingsdaten. Durch kontrollierte Experimente fanden die Forscher heraus, dass die effektive Ausgabelänge eines Modells durch die längste Ausgabe begrenzt ist, die es während des überwachten Feinabstimmens (Supervised Fine-Tuning, SFT) gesehen hat.
Mit anderen Worten: Die Ausgabebeschränkung liegt an der Knappheit an Beispielen mit langen Ausgaben in bestehenden SFT-Datensätzen. Um dieses Problem zu lösen, stellen die Wissenschaftler "AgentWrite" vor - eine agentenbasierte Pipeline, die lange Generierungsaufgaben in Teilaufgaben zerlegt. So können bestehende LLMs kohärente Ausgaben mit über 20.000 Wörtern erzeugen.
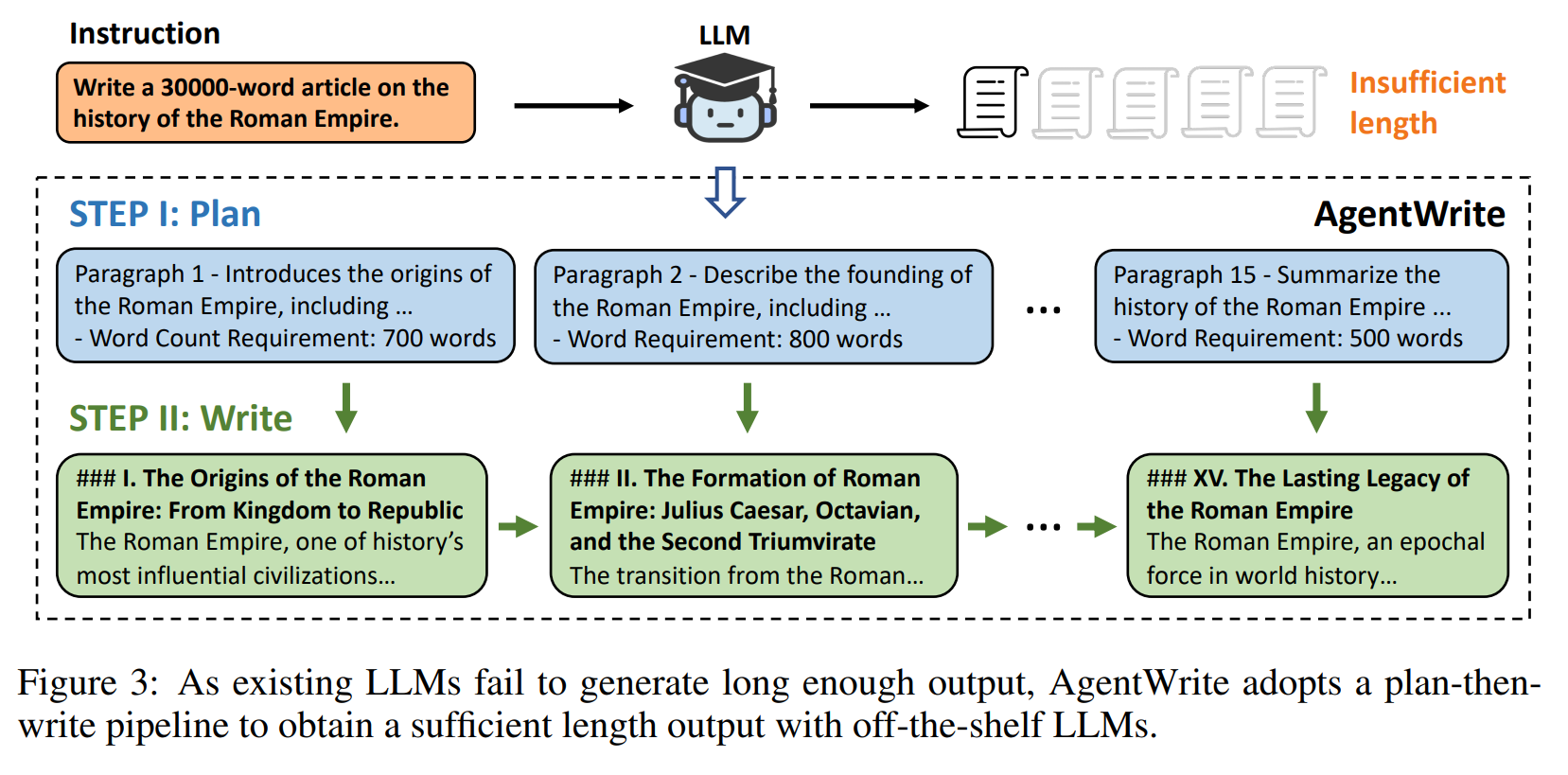
LongWriter generiert routinemäßig 40 Seiten Text
Mithilfe von AgentWrite erstellten die Forscher den Datensatz "LongWriter-6k". Er enthält 6.000 SFT-Daten mit Ausgabelängen zwischen 2.000 und 32.000 Wörtern. Durch das Training mit diesem Datensatz konnten sie die Ausgabelänge bestehender Modelle auf über 10.000 Wörter skalieren, ohne die Ausgabequalität zu beeinträchtigen.
Video: Bai, Zhang et al.
Zur Bewertung der ultralangen Generierungsfähigkeiten entwickelten sie außerdem "LongBench-Write" - einen umfassenden Benchmark mit verschiedenen Schreibanweisungen und Ausgabelängen von 0 bis über 4.000 Wörter.
Das 9-Milliarden-Parameter-Modell der Forscher, das zusätzlich durch Direct Preference Optimization (DPO) verbessert wurde, erreichte in diesem Benchmark Spitzenleistungen. Es übertraf sogar viel größere proprietäre Modelle.
Code und Modell für LongWriter sind auf GitHub verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.