Nvidia verbessert Llama-Modell mit neuem Trainingsansatz

Das neue Sprachmodell von Nvidia setzt sich in Alignment-Benchmarks an die Spitze. Möglich macht dies ein spezielles Trainingsverfahren, das Bewertungs- und Präferenzmodelle kombiniert.
Nvidia hat mit Llama-3.1-Nemotron-70B-Instruct ein neues großes Sprachmodell auf Basis von Metas Open-Source-Modell Llama 3.1 vorgestellt, das darauf optimiert wurde, hilfreiche Antworten auf Nutzeranfragen zu geben. Das Besondere daran ist die Kombination verschiedener Trainingsmethoden.
Die Ergebnisse zeigen jedoch nur, dass die Antworten eher menschlichen Vorlieben entsprechen, nicht aber, dass die Antworten inhaltlich besser sind, wie ein Blick ins Ranking des MMLU-Pro-Benchmarks zeigt. Dort schneidet die Nemotron-Variante sogar leicht schlechter ab als das Grundmodell.
Grundlage für das Training waren zwei von Nvidia erstellte Datensätze: HelpSteer2 und HelpSteer2-Preference. HelpSteer2 enthält über 20.000 Prompt-Antwort-Paare, bei denen jede Antwort von mehreren Annotatoren auf einer Skala von 1 bis 5 hinsichtlich Kriterien wie Hilfsbereitschaft, Korrektheit und Kohärenz bewertet wurde.
HelpSteer2-Preference ergänzt dies um Vergleiche zwischen jeweils zwei Antworten auf denselben Prompt. Die Annotator:innen gaben an, welche Antwort sie bevorzugen und wie stark diese Präferenz ist.
Kombination zweier Belohnungsmodelle
Nvidia nutzte diese Daten, um zwei Arten von Belohnungsmodellen zu trainieren: Regressions- und Bradley-Terry-Modelle. Regressionsmodelle wie SteerLM lernen, den einzelnen Antworten Werte für die verschiedenen Kriterien zuzuordnen. Bradley-Terry-Modelle hingegen lernen aus den Präferenzvergleichen, den Belohnungsunterschied zwischen zwei Antworten zu maximieren.
Die Forscher fanden heraus, dass eine Kombination beider Ansätze die besten Ergebnisse liefert. Dazu trainierten sie zunächst ein SteerLM-Regressionsmodell nur anhand der Hilfsbereitschafts-Bewertungen. Dieses Modell diente dann als Ausgangspunkt für ein skaliertes Bradley-Terry-Modell, das zusätzlich die Stärke der Präferenzen zwischen den Antworten berücksichtigt. Durch eine Extrapolation der gelernten Gewichte (ExPO) konnte die Leistung weiter gesteigert werden.
Zur Feinabstimmung des Sprachmodells auf die gelernten Belohnungen setzte Nvidia auf den Algorithmus REINFORCE. Im Gegensatz zu dem häufig verwendeten PPO (Proximal Policy Optimization) schätzt REINFORCE den Wert einer Aktion stabiler und unvoreingenommener.
Verbesserung der Hilfsbereitschaft und längere Antworten
Dies führte in Kombination mit dem trainierten Belohnungsmodell zu einer deutlichen Verbesserung der Ergebnisse bei Benchmarks, die die Hilfsbereitschaft der Antworten messen. Auch die Länge lag mit durchschnittlich 2200 Zeichen pro Antwort gut 400 Zeichen über der anderer Modelle.
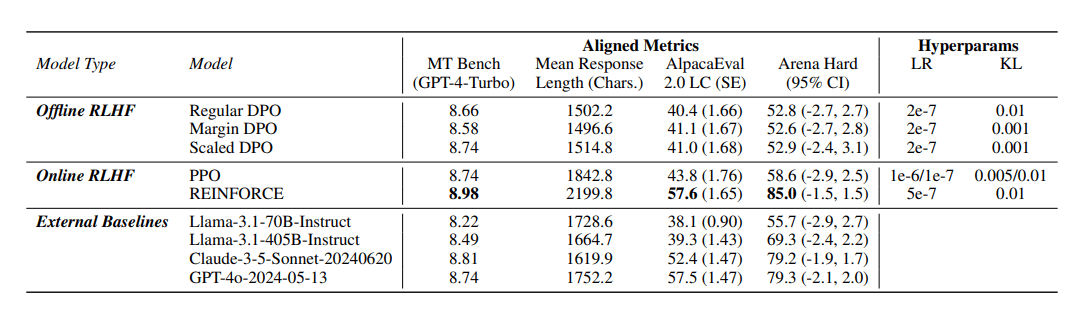
Das finale Modell Llama-3.1-Nemotron-70B-Instruct erreicht in den Benchmarks Arena Hard, AlpacaEval 2 LC und GPT-4-Turbo MT-Bench jeweils den ersten Platz. Es übertrifft damit Spitzenmodelle wie GPT-4o und Claude 3.5 Sonnet. In Arena Hard erzielt es einen Wert von 85.0 und liegt damit deutlich vor dem Ausgangsmodell Llama-3.1-70B-Instruct mit 55.7.
Nemotron besteht Erdbeeren-Test
Die Verbesserungen zeigen sich auch in konkreten Anwendungen. So kann Llama-3.1-Nemotron-70B-Instruct etwa die Frage "How many r in strawberry?" korrekt beantworten, indem es die Buchstaben einzeln durchgeht und die "R" zählt. Das Ausgangsmodell sowie kommerzielle Konkurrenten hingegen gäben oft eine falsche Antwort.

Nvidia betont, dass das neue Modell die Techniken des Unternehmens zur Verbesserung der Hilfsbereitschaft in allgemeinen Anwendungsbereichen demonstriert. Für spezialisierte Domänen wie Mathematik wurde es jedoch nicht optimiert. Im Juni hatte Nvidia Nemotron-Sprachmodelle zur Datengenerierung veröffentlicht.
Llama-3.1-Nemotron-70B-Instruct könnt ihr kostenlos im HuggingChat oder bei Nvidia ausprobieren.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.