Neues KI-Spracherkennungsmodell Moonshine ist bis zu fünfmal schneller als Whisper
Das neue Open-Source-Spracherkennungsmodell Moonshine ermöglicht durch seine optimierte Architektur eine schnellere und ressourcenschonendere Verarbeitung von Audiodaten als OpenAIs Whisper.
Forschende des US-Start-ups Useful Sensors haben mit Moonshine ein neues Open-Source-Spracherkennungsmodell entwickelt, das speziell für Echtzeit-Anwendungen auf ressourcenbeschränkter Hardware optimiert wurde. Im Vergleich zu OpenAIs State-of-the-Art-Modell Whisper erzielt Moonshine eine höhere Effizienz und Geschwindigkeit bei vergleichbarer Genauigkeit.
Bis zu fünfmal schneller als Whisper
Ein entscheidender Vorteil von Moonshine liegt in der Architektur des Modells. Während Whisper stets mit festen 30-Sekunden-Blöcken arbeitet, unabhängig von der tatsächlichen Länge der Spracheingabe, passt sich die Verarbeitungszeit von Moonshine proportional zur Länge der Audioeingabe an. Dieser Ansatz ermöglicht eine effizientere Verarbeitung, insbesondere bei kurzen Audiosegmenten.
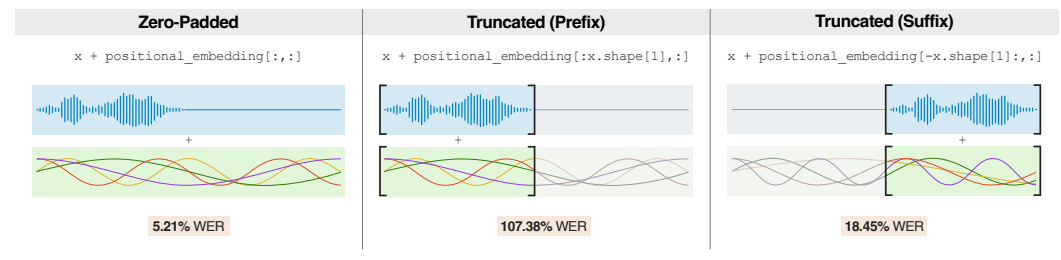
Die Forschenden haben in Tests gezeigt, dass Moonshine bei zehnsekündigen Audioclips bis zu fünfmal schneller ist als Whisper. Dieser Geschwindigkeitsvorteil resultiert aus der Eliminierung des Overheads, der durch die Auffüllung kürzerer Audiodaten mit Nullen entsteht, um die feste Eingabelänge von Whisper zu erreichen.
Um die Genauigkeit von Whisper zu erreichen und gleichzeitig die Recheneffizienz zu optimieren, haben die Forscher Moonshine mit einer Kombination aus öffentlich zugänglichen und intern erstellten Datensätzen trainiert. Insgesamt umfasste der Trainingsdatensatz rund 200.000 Stunden an Audiodaten.
Moonshine ist in zwei Varianten verfügbar: Tiny und Base. Das Tiny-Modell ist mit 27,1 Millionen Parametern deutlich kleiner als das Base-Modell mit 61,5 Millionen Parametern. Whisper tiny.en umfasst 37,8 Millionen Parameter, base.en 72,6 Millionen.
Trotz der geringeren Größe erreicht das Tiny-Modell eine mit dem Whisper-Pendant vergleichbare Genauigkeit bei einem Bruchteil des Rechenaufwands. Dies macht es besonders attraktiv für den Einsatz auf Geräten mit stark begrenzten Ressourcen.
In verschiedenen Benchmarks haben die Moonshine-Modelle im Durchschnitt eine leicht bessere Wortfehlerrate (WER) erzielt als die entsprechenden Whisper-Modelle. Auch bei unterschiedlichen Audiopegeln und Hintergrundgeräuschen zeigt Moonshine eine robuste Leistung und behält eine niedrigere WER als Whisper bei.
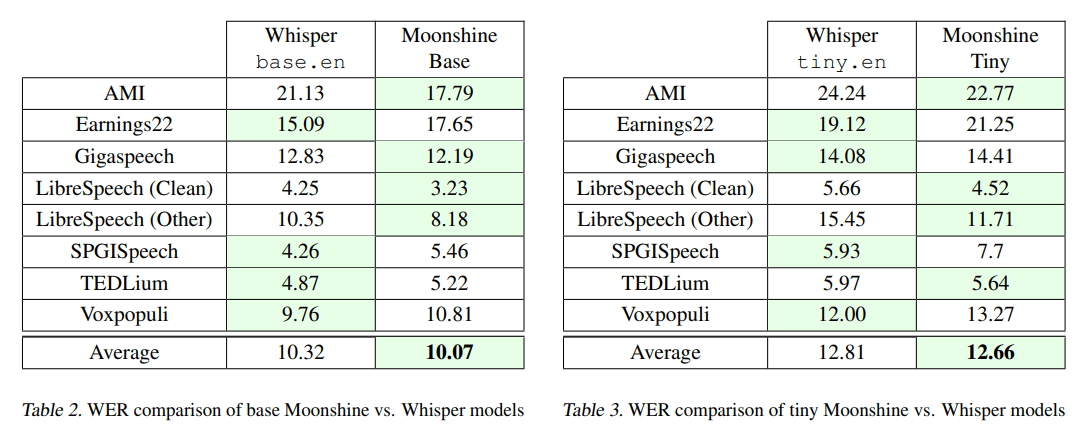
Verbesserungspotenzial bei sehr kurzen Segmenten
Die Forschenden sehen jedoch noch Verbesserungspotenzial bei der Verarbeitung sehr kurzer Audiosegmente unter einer Sekunde, da diese im Trainingsdatensatz unterrepräsentiert waren. Eine Erweiterung des Datensatzes um solche Beispiele könnte die Generalisierungsfähigkeit von Moonshine in diesem Bereich verbessern.
Durch die Optimierung für ressourcenbeschränkte Hardware und die Fähigkeit, ohne Internetverbindung zu arbeiten, könnte Moonshine die Entwicklung neuer Anwendungen vorantreiben, die bisher aufgrund technischer Einschränkungen nicht möglich waren.
Zwar lässt sich Whisper bereits auf Consumer-Hardware betreiben, für Smartphones und andere kleine Geräte wie den Einplatinenrechner Raspberry Pi benötigt das OpenAI-Modell jedoch noch zu viel Leistung. Moonshine steckt in dem Englisch-Spanisch-Übersetzer Torre, den das eher auf Hardware fokussierte Unternehmen Useful Sensors kürzlich ebenfalls präsentierte.
Moonshine ist als Open Source bei Github verfügbar.
Beim Einsatz von KI-basierten Transkriptionssystemen sollte man bedenken, dass auch diese halluzinieren können. Eine Studie der Cornell University zeigt, dass die Spracherkennungs-KI Whisper von OpenAI in etwa 1,4 Prozent der Fälle Inhalte halluziniert, die im Original nicht vorkommen. Besonders betroffen sind Menschen mit Sprachstörungen wie Aphasie. Andere Forscher berichten von noch höheren Fehlerraten bis zu 50 Prozent.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.