Forscher verbessern KI-Logik durch Fokus auf kritische Token
Forscher haben eine neue Methode entwickelt, die die Argumentationsfähigkeit von KI-Sprachmodellen verbessert. Der Schlüssel liegt in der Identifizierung besonders wichtiger Wörter.
Wissenschaftler der Tsinghua University und des Tencent AI Lab haben eine neue Methode namens "cDPO" (contrastive Direct Preference Optimization) vorgestellt, die die Argumentationsfähigkeit von großen Sprachmodellen verbessert.
Die Forscher entdeckten, dass einzelne Wörter - sogenannte "kritische Token" - einen überproportional großen Einfluss auf die Qualität von KI-Argumentationen haben können. In Experimenten konnten sie nachweisen, dass die gezielte Manipulation dieser Token die Wahrscheinlichkeit korrekter Antworten deutlich erhöht.
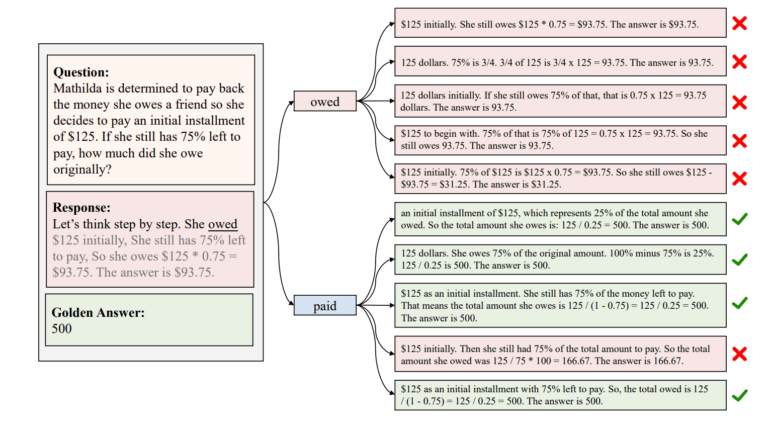
cDPO identifiziert automatisiert kritische Token
Ausgehend von dieser Erkenntnis entwickelten die Forschenden cDPO (contrastive DPO), ein Verfahren zur automatischen Erkennung und Belohnung kritischer Token während des Alignment-Prozesses eines Sprachmodells. Die Methode verwendet kontrastive Schätzung, um diese kritischen Token zu identifizieren.
Dafür trainieren die Wissenschaftler zwei separate Modelle: ein "positives" Modell auf korrekten Argumentationspfaden und ein "negatives" Modell auf fehlerhaften Pfaden. Die beiden Modelle liefern unterschiedliche Wahrscheinlichkeiten für die Generierung einzelner Token.
Die Differenz dieser Wahrscheinlichkeiten dient als Indikator für die Kritikalität eines Tokens, erklären die Autoren. Je größer die Abweichung, desto wahrscheinlicher handelt es sich um ein kritisches Token, das zu fehlerhaften Schlussfolgerungen führt.
cDPO schlägt andere Alignmentmethoden
Die Forschenden evaluierten cDPO mit Llama-3 (8B und 70B) und deepseek-math (7B) auf den Benchmarks GSM8K und MATH500. Die Ergebnisse zeigen eine signifikante Verbesserung gegenüber herkömmlichen DPO-Varianten sowie anderen Alignmentmethoden. So erzielt cDPO in der Praxis durchweg höhere Erfolgsraten bei der Lösung von Argumentationsaufgaben.
Allerdings liegt die Verbesserung gegenüber den bisher besten Alignmentmethoden nur bei wenigen Prozentpunkten - die logischen Schwächen großer Sprachmodelle lassen sich also auch durch den Ausschluss kritischer Token nicht beheben.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.