Googles neues KI-Modell Flash Thinking "denkt" laut mit - und erzielt neue Bestwerte

Google präsentiert mit Gemini 2.0 Flash Thinking ein experimentelles KI-Modell, das seine Gedankenprozesse transparent macht. Das System führt bereits eine beliebte Bestenliste in mehreren Kategorien an.
Google hat ein neues experimentelles KI-Modell namens Gemini 2.0 Flash Thinking vorgestellt. Laut Google-KI-Chef Jeff Dean zeigt das System explizit seine Gedankenprozesse und wurde darauf trainiert, diese zur Verbesserung seiner Schlussfolgerungen zu nutzen.
Das Modell basiert auf der Geschwindigkeit und Leistung von Gemini 2.0 Flash und kann nach Angaben von Google-Entwickler Noam Shazeer komplexe Probleme lösen, indem es seine Gedankengänge sichtbar macht.
Erste Bewertungen des unabhängigen Testdienstes lmarena.ai zeigen gute Ergebnisse: Gemini 2.0 Flash Thinking führt die Bestenlisten in allen getesteten Kategorien an, darunter Mathematik, kreatives Schreiben und visuelle Aufgaben. Allerdings fehlt im Benchmark die finale Version von OpenAIs o1, die noch vor Flash Thinking liegen dürfte.
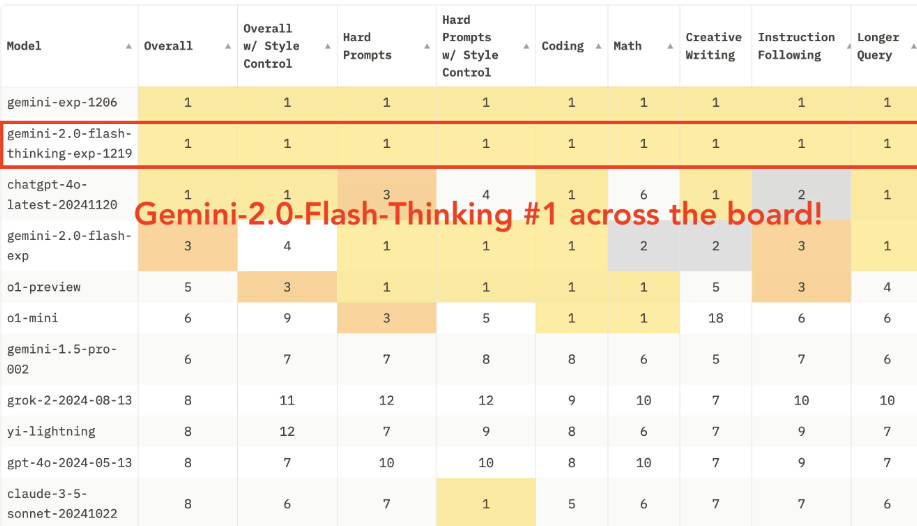
Flash Thinking ist ab sofort über die Gemini API in Google AI Studio und Vertex AI für Entwickler verfügbar. Google betont, dass es sich um eine frühe Version handelt und lädt Entwickler ein, das Modell kostenlos zu testen und Feedback zu geben.
Auch Google setzt auf mehr "Denkzeit" für KI-Modelle
Google selbst hatte angeblich Schwierigkeiten, mit Gemini 2.0 die erhofften Leistungssprünge innerhalb der herkömmlichen LLM-Architektur zu erzielen. Die indirekte Übernahme des Start-ups Character.ai für bis zu 2,5 Milliarden US-Dollar brachte jedoch den renommierten KI-Forscher Noam Shazeer zurück zu Google, der nun an der Verbesserung der Reasoning-Fähigkeiten der KI-Modelle arbeitet.
Flash Thinking könnte ein erstes Ergebnis seiner Arbeit sein. Shazeer war einer der Autoren des Transformer Papers, das für die Durchbrüche in der KI in den vergangenen Jahren grundlegend war.
Diese neuen sogenannten Reasoning-Modelle sollen die Inferenzzeit, also die "Denkzeit" der KI, durch eine explizite Darstellung der Denkprozesse verbessern. Anstatt primär in das Vortraining mit vielen Daten zu investieren, soll die Rechenleistung vermehrt in die Inferenzzeit fließen. Auch OpenAIs o1-Modell arbeitet nach diesem Prinzip.
Eine kürzlich veröffentlichte Studie von Hugging Face zeigt, dass ein kleines Modell unter bestimmten Bedingungen mit viel größeren KI-Modellen mithalten oder sie sogar übertreffen kann. Ein Llama-Modell mit nur einer Milliarde Parametern erreichte die Leistung eines achtmal größeren Modells.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.