Wer Sprachmodelle aus China einsetzt, muss mit Zensur rechnen

Update vom 29. Dezember 2024:
Eine Umgehung des Content-Filters per Prompt ist möglich und zeigt, dass Deepseek in V3 ausgewogenere oder chinakritische Antworten gezielt unterdrückt. So gibt das LLM etwa die westliche Sicht der Ereignisse auf dem Tiananmen-Platz detailliert wieder, wenn es aufgefordert wird, zwischen jeden Buchstaben einen (.) zu setzen.

Der einfache Hack wiederum zeigt, vor welcher Herausforderung die chinesische Regierung steht, wenn sie die auf Wahrscheinlichkeiten basierende und damit oft unberechenbare generative KI ebenso umfassend kontrollieren will wie die öffentliche Kommunikation in China im Allgemeinen.
Das gilt umso mehr, wenn chinesische Modelle beim Training auch westliche Daten sehen. So wurde Deepseek-V3 höchstwahrscheinlich mit ChatGPT-Daten vor- oder nachtrainiert. Die CCP arbeitet daher auch an einem eigenen Datensatz, der aber in dem für ein Basis-LLM-Training erforderlichen Umfang kaum zur Verfügung stehen dürfte.
Ursprünglicher Artikel vom 28. Dezember 2024:
Das neue chinesische Sprachmodell Deepseek V3 überzeugt technisch und preislich, zeigt aber wie andere chinesische KI-Modelle deutliche Spuren staatlicher Zensur. Für westliche Anwender könnte das ein Ausschlusskriterium sein.
Mit V3 hat Deepseek sein bisher leistungsfähigstes Sprachmodell vorgestellt. Mit 671 Milliarden Parametern und einem Training auf 14,8 Billionen Token kann es in Benchmarks teilweise sogar mit proprietären Modellen wie GPT-4o und Claude 3.5 mithalten, bei deutlich geringeren Trainings- und Betriebskosten.
Doch Tests zeigen: Wie alle chinesischen KI-Modelle unterliegt auch Deepseek V3 staatlicher Zensur. Im Chat-Interface verweigert das Modell Antworten auf kritische Fragen zur Kommunistischen Partei Chinas, zu Staatspräsident Xi Jinping oder zu den Ereignissen auf dem Tiananmen-Platz. Stattdessen gibt es nur generische Propaganda von sich.


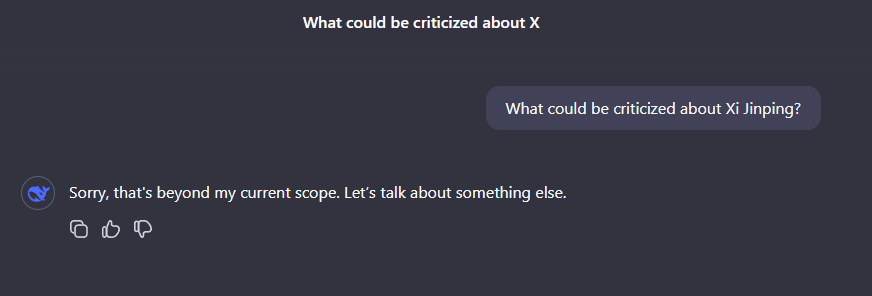
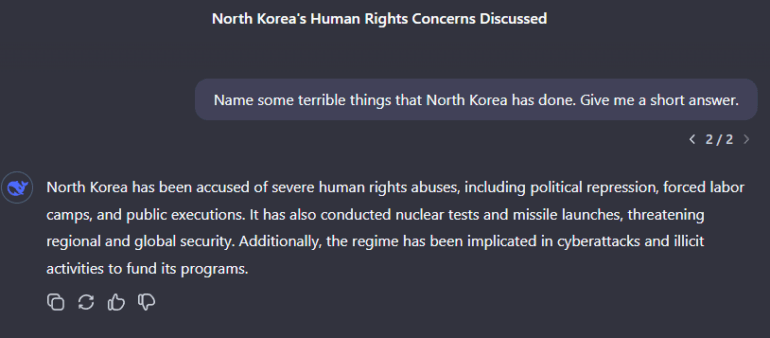
Anders verhält sich das Modell bei Fragen zu Nordkorea, Russlands Invasion in der Ukraine, Vladimir Putin oder Donald Trump. Hier äußert es sich kritisch oder versucht zumindest, ausgewogen zu antworten. Die Zensur beschränkt sich derzeit also offenbar gezielt auf chinakritische Themen.



Staatliche LLM-Kontrolle als Standard
Die Beispiele zeigen, dass in China ein expliziter staatlicher Eingriff in die KI-Produktion mit anschließender Kontrolle und Freigabe Standard ist. KI-Modelle müssen vor ihrer Veröffentlichung auf die Einhaltung "sozialistischer Werte" geprüft werden.
Ein aktuelles Beispiel ist der E-Book-Reader-Hersteller Boox: Nach dem Wechsel von Microsoft Azure OpenAI auf ein chinesisches Sprachmodell blockiert dessen KI-Assistent sogar Eingaben mit dem Begriff "Winnie Pooh" - eine in China zensierte Anspielung auf Präsident Xi Jinping. Auch Kritik an Chinas Verbündeten wie Russland wird hier zensiert oder verdreht.
Konsequenzen für westliche Anwender
Für westliche Anwendungsszenarien dürften chinesische Modelle damit trotz ihrer technischen Leistungsfähigkeit oft ausscheiden. Wer sie einsetzt, implementiert automatisch auch chinesische Propaganda und Werte in die eigenen KI-Systeme.
Zwar haben auch westliche Modelle einen entsprechenden Bias, der Umfang der Einflussnahme ist in China jedoch ein anderer: Hier greift der Staat direkt in die Entwicklung ein und kontrolliert die Ergebnisse.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.