OpenAI finanzierte heimlich die Entwicklung eines bedeutenden unabhängigen Mathe-Benchmarks

Die Finanzierung des als unabhängig geltenden Mathematik-Benchmarks FrontierMath durch OpenAI wurde erst bekannt, als das Unternehmen dort einen neuen Rekord aufstellte. Der Benchmark-Entwickler Epoch AI räumt Fehler in der Kommunikation ein.
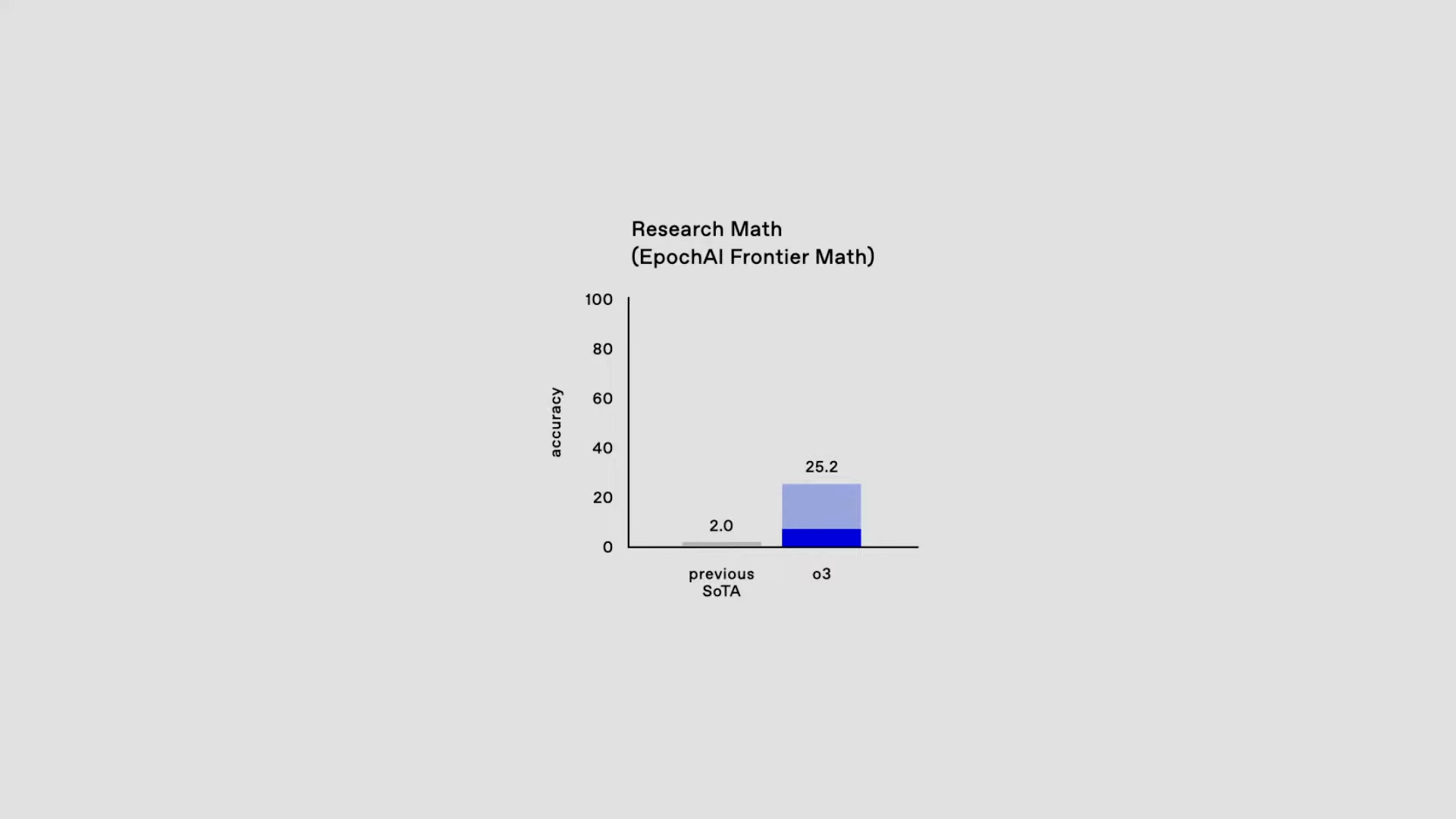
Die Tatsache, dass OpenAI FrontierMath mitfinanziert, wurde erst am 20. Dezember bekannt, zeitgleich mit der Ankündigung des neuen OpenAI-Modells o3, das mit 25,2 Prozent gelösten Aufgaben im besagten Benchmark einen neuen Rekord aufstellte. Der Benchmark testet die mathematisch-logischen Fähigkeiten von KI-Modellen anhand schwieriger Mathematik-Aufgaben. Bisherige Modelle erreichten nicht mehr als zwei Prozent.
Epoch AI, der Entwickler des Benchmarks, war bis zur Bekanntgabe von o3 vertraglich verpflichtet, die finanzielle Beteiligung von OpenAI nicht offenzulegen. Die Offenlegung erfolgte mit der fünften Aktualisierung des wissenschaftlichen Papiers lediglich in einer Fußnote: "Wir danken OpenAI für die Unterstützung bei der Erstellung des Benchmarks." Zuvor gab es keinen Hinweis auf eine Verbindung zwischen OpenAI und dem Benchmark.
Die mehr als 60 Mathematiker, die an der Entwicklung der Benchmark-Aufgaben beteiligt waren, wurden laut eines Beitrags bei LessWrong nicht systematisch über die Finanzierung von OpenAI informiert - auch nicht nach der Ankündigung von o3.
Sie unterzeichneten zwar Geheimhaltungsvereinbarungen, die aber nur mit der Vertraulichkeit der Aufgaben begründet wurden. Laut dem Beitrag hatten die meisten Beteiligten den Eindruck, dass die Aufgaben und Lösungen privat bleiben und nur von Epoch AI verwendet werden würden.
Mündliche Vereinbarung soll Training auf Benchmark-Daten verhindern
Tamay Besiroglu von Epoch AI räumt in einer Antwort bei LessWrong Fehler ein: "Wir hätten uns stärker für Transparenz einsetzen müssen, besonders gegenüber den Mathematikern, die wissen sollten, wer Zugang zu ihrer Arbeit haben würde."
Laut Besiroglu hatte OpenAI im Vorfeld der o3-Bekanntgabe Zugang zu einem Großteil der Mathematikaufgaben und deren Lösungen erhalten. Ein separater Datensatz blieb jedoch unter Verschluss, um unabhängige Überprüfungen zu ermöglichen.
Laut Epoch AI gibt es auch eine mündliche Vereinbarung, dass OpenAI das zur Verfügung gestellte Material nicht zum Training von Modellen verwenden darf. Damit soll eine Benchmark-Optimierung und eine weitere Verbreitung der Aufgaben verhindert werden.
"Wir hätten härter verhandeln sollen, um von Anfang an transparent sein zu können", schreibt Besiroglu. In Zukunft will das Unternehmen bei Kooperationen von Anfang an auf volle Transparenz bestehen.
Die mangelnde Transparenz von Epoch AI und OpenAI stellt nicht zwangsläufig die Qualität und Bedeutung des Benchmarks in Frage.
"Ich glaube, dass OAI bei der Darstellung der Ergebnisse korrekt war, aber Epoch kann dafür nicht bürgen, bis wir das Modell mithilfe des von uns in der Entwicklung befindlichen Testdatensatzes unabhängig evaluiert haben", schreibt Elliot Glazer, leitender Mathematiker bei Epoch AI.
Allerdings wäre bei einem so bedeutenden Instrument zur KI-Bewertung von Anfang an maximale Offenheit wünschenswert gewesen - insbesondere da KI-Benchmarking an sich ein komplexes Gebilde ist: Die realen Auswirkungen eines Modells anhand von Benchmark-Resultaten zu prognostizieren ist schwierig, und die Resultate hängen stark von Messmethoden, Prompts und anderen Modelloptimierungen ab. Gleichzeitig sind Benchmark-Ergebnisse aber ein Instrument, um Aufsehen zu erzeugen und Investorengelder anzuziehen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.