Chinesischer o1-Wettbewerber Kimi k1.5 jetzt als kostenlose Webversion verfügbar

Update –
- Webversion ergänzt
Update vom 25. Januar 2025:
Moonshot AI hat Kimi k1.5 für die Webnutzung auf Kimi.ai veröffentlicht. Neu ist zudem die Unterstützung der englischen Sprache, die nach Angaben des Start-ups noch verfeinert wird.
Kimi.ai bietet laut Moonshot AI unbegrenzte kostenlose Nutzung für k1.5, Echtzeit-Websuche über 100+ Websites, Analyse von bis zu 50 Dateien, fortschrittliches Reasoning und verbessertes Bildverständnis - allerdings ist eine Registrierung notwendig. Die geht über die Telefonnummer und demnächst über Google.
Ursprünglicher Artikel vom 21. Januar 2025:
Moonshot AI: KI-Startup präsentiert mit Kimi k1.5 den nächsten chinesischen o1-Konkurrenten
Nach DeepSeek-R1 kommt das nächste Reasoning-Modell aus China, das multimodale Kimi k1.5. Es übertrifft viele etablierte KI-Modelle bei komplexen Schlussfolgerungsaufgaben.
Das chinesische KI-Unternehmen Moonshot AI hat Kimi k1.5 long-CoT, Kimi k1.5 short-CoT und zwei neue Sprachmodelle vorgestellt, die durch den Einsatz von Reinforcement Learning (RL) sehr gute Ergebnisse beim maschinellen Schlussfolgern erzielen.
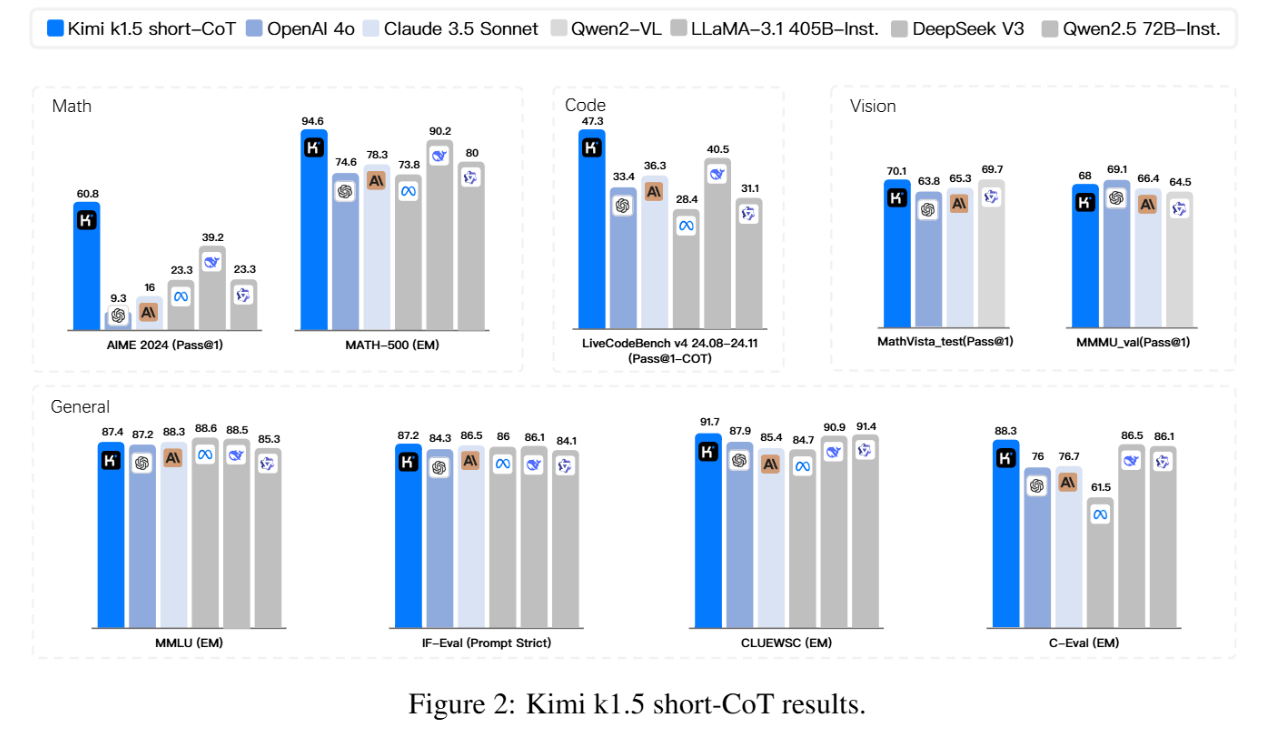
Laut dem technischen Bericht des Teams erreicht k1.5 sowohl in der Long-CoT- als auch in der Short-CoT-Version State-of-the-Art-Performance und kann laut Benchmarks mit etablierten Modellen wie OpenAIs o1 und auch DeepSeeks neuestem R1-Modell mithalten. Als "Long-CoT" (Chain-of-Thought) bezeichnet das Team eine Methode, bei der das Modell seine Gedankengänge ausführlich Schritt für Schritt erklärt, während "Short-CoT" auf prägnantere Antworten abzielt. In dieser Kategorie liegt es auf und teilweise über dem Niveau von GPT-4o und Claude 3.5 Sonnet.
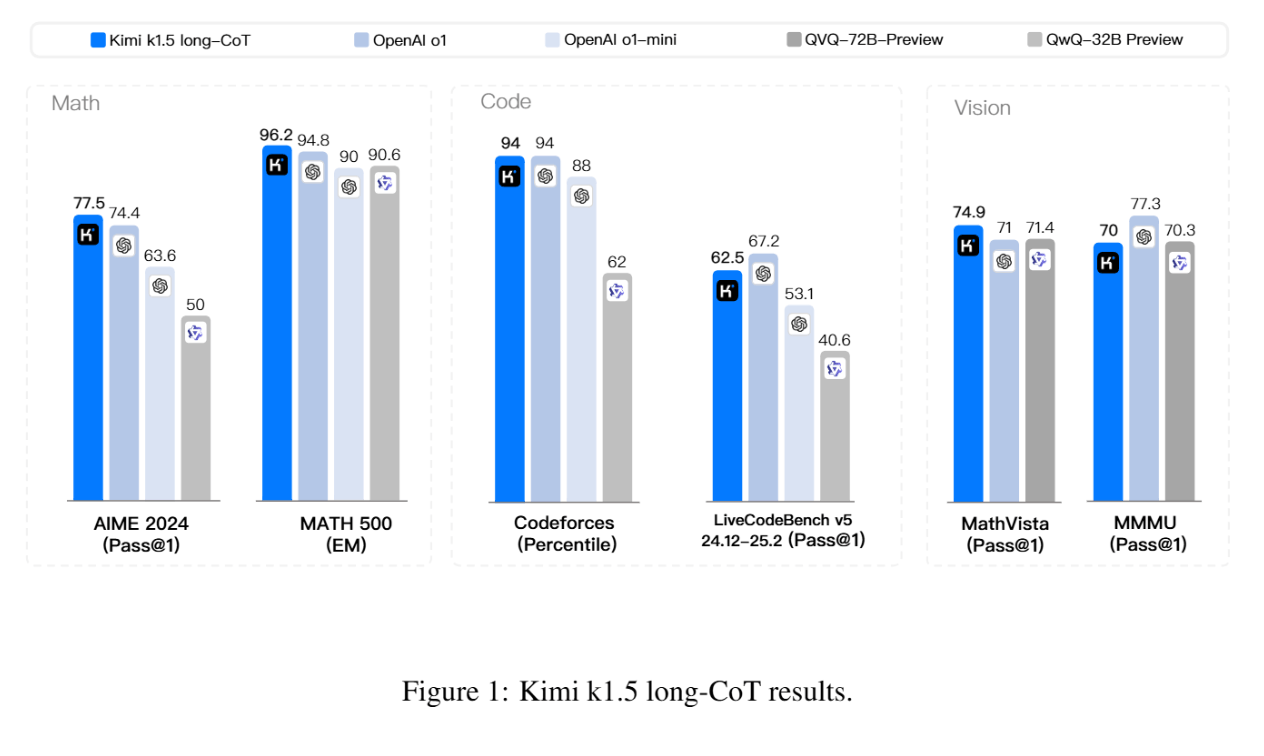
Das multimodale Training mit Text- und Bilddaten ermöglicht dem Modell auch modalitätsübergreifende Schlussfolgerungen. In multimodalen Benchmarks wie MathVista oder MMMU erreicht K1.5 Spitzenwerte. Im Gegensatz dazu kann das DeepSeeks R1-Modell keine Bilder verarbeiten.
Wie immer gilt jedoch: Wie nützlich das Modell in der Praxis jenseits von Benchmarks ist, muss sich in konkreten Anwendungsfällen zeigen.
Kimi k1.5 setzt auf SFT und RL
Wie die meisten großen Sprachmodelle wurde Kimi K1.5 zunächst mit einem riesigen Datensatz aus Text und Bildern vortrainiert. Dieser Schritt dient dazu, dem Modell ein grundlegendes Verständnis von Sprache und visuellen Informationen zu vermitteln.
Nach dem Pretraining wurde das Modell mit einem kleineren, speziell zusammengestellten Datensatz feinabgestimmt (SFT). Hierbei lernt das Modell, spezifische Aufgaben wie Fragen beantworten oder Code generieren zu lösen. Für Aufgaben, die sich mit Regeln überprüfen lassen (z.B. Mathematik oder Programmieren), wurde eine Technik namens "Rejection Sampling" verwendet, um mehr Trainingsdaten zu erzeugen. Dabei generiert das Modell mehrere Antworten, und nur die korrekten werden für das Training verwendet. Dieser Ansatz unterscheidet sich von anderen, die oft auf menschliche Bewertungen angewiesen sind. Um die Fähigkeit des Modells zu verbessern, komplexe Argumentationen Schritt für Schritt durchzuführen, wurde es zusätzlich mit einem synthetisch erweiterten Datensatz trainiert, der Beispiele für solche langen Gedankengänge (Long-CoT) enthält.
Abschließend wurde das Modell per Reinforcement Learning trainiert: Das Modell generiert Antworten auf verschiedene Aufgaben, und ein Belohnungsmodell bewertet die Korrektheit. Anhand dieser Belohnung lernt das Modell, welche Strategien zum Erfolg führen. Ein wichtiger Unterschied zu anderen RL-Ansätzen ist der Verzicht des Teams auf sogenannte Wertfunktionen. Diese dienen normalerweise dazu, den Wert von Zwischenschritten zu bewerten. Moonshot AI argumentiert, dass dies die Exploration des Modells einschränken kann, da auch falsche Zwischenschritte wertvolle Lernerfahrungen bieten können, solange das Modell am Ende zur korrekten Lösung gelangt. Stattdessen setzt das Team auf eine "Längenstrafe", die übermäßig lange Antworten bestraft und so die Effizienz des Modells fördert.
Kimi k1.5 unterscheidet sich daher von DeepSeeks R-1- und R-1-Zero-Modellen, die einen simpleren Reinforcement-Learning-Prozess mit regelbasiertem Feedback nutzen. R1-Zero wurde sogar ohne zusätzliche Daten ausschließlich mit RL trainiert.
Kimi k1.5 lernt aus langen Gedankenketten kürzere Schlussfolgerungen
Da lange Denkvorgänge (Long-CoT) zwar gute Ergebnisse liefern, aber auch rechenintensiv sind, hat das Team auch eine Methode entwickelt, um dieses Wissen auf Modelle mit kürzeren Antworten (Short-CoT) zu übertragen. Dazu gehören Methoden wie Modellfusion, "Shortest Rejection Sampling" (Auswahl der kürzesten richtigen Antwort aus mehreren Versuchen) und "Direct Preference Optimization" (DPO), bei der das Modell lernt, kürzere Antworten gegenüber längeren zu bevorzugen.
Während des Trainings beobachtete das Team, dass die Skalierung der Kontextlänge (auf bis zu 128k Token) zu einer kontinuierlichen Verbesserung der Modellleistung führt, da längere Kontexte komplexeres Reasoning und bessere Problemlösungen ermöglichen. Das Paper zeigt auch, dass es möglich ist, auf komplexe Komponenten wie Monte-Carlo Tree Search oder Wertfunktionen zu verzichten, um solche Reasoning-Modelle zu trainieren - ähnliche Ergebnisse wurden auch im DeepSeek-R1 Paper erzielt. Die entwickelten "Long2Short"-Methoden zeigen zudem, dass das Wissen aus Modellen mit langen Antworten erfolgreich auf effizientere Modelle mit kurzen Antworten übertragen werden kann. Ähnliche Fortschritte bei der Destillation von Wissen aus größeren Modellen in kleinere Modelle werden schon länger hinter den kleineren und besseren Modellen großer Anbieter wie Anthropics Claude 3.5 Sonnet vermutet.
Das 2023 gegründete Unternehmen Moonshot AI sammelte im Februar 2024 in einer von Alibaba angeführten Finanzierungsrunde mehr als 1 Milliarde US-Dollar ein und wurde mit 2,5 Milliarden US-Dollar bewertet. Im August 2024 stieg die Bewertung nach einer weiteren Finanzierungsrunde unter Beteiligung von Tencent und Gaorong Capital auf 3,3 Milliarden US-Dollar. Kimi ist der ChatGPT-Konkurrent des Unternehmens, der demnächst auch auf dem neuen k1.5-Modellen laufen soll. Anders als DeepSeek hat Moonshot AI seine Kimi k1.5-Modelle bisher nicht veröffentlicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.