Alibabas Qwen2.5-VL-32B analysiert Bilder schnell und präzise

Update vom 26. März 2025:
Alibaba hat nun mit Qwen2.5-VL-32B eine neue Version seines multimodalen KI-Modells vorgestellt. Das unter Apache-2.0-Lizenz veröffentlichte Modell mit 32 Milliarden Parametern soll besser auf menschliche Präferenzen eingehen, verbesserte mathematische Fähigkeiten bieten und genauere Bildanalysen ermöglichen. In ersten Benchmarks übertrifft es laut Hersteller vergleichbare Modelle wie Gemma 3-27B und Mistral Small 3.1 24B - und teilweise sogar das hauseigene, doppelt so große Qwen2-VL-72B oder OpenAIs kommerziell angebotenes GPT-4o, jedoch in einer älteren Version als die aktuell verfügbare.
Besonders bei komplexen Aufgaben zeige das neue Modell seine Stärken: Im MMMU-Benchmark (Multimodal Machine Understanding), der das Verständnis verschiedener Medientypen testet, sowie bei MathVista, einem Test für mathematisches Reasoning anhand von Bildern, erreicht es neue Bestwerte. Auch beim MM-MT-Bench, der die Qualität der Interaktion mit Nutzer:innen bewertet, übertrifft es seinen Vorgänger deutlich. In gleichem Maßstab sei Qwen-2.5-VL-32B auch in reinen Textaufgaben besser geworden.
Entwickler Simon Willison testete das Modell auf einem Mac mit 64 GB RAM und bestätigt die verbesserten Fähigkeiten bei der Bildanalyse. In seinem Test lieferte das Modell detaillierte, gut strukturierte Beschreibungen einer komplexen Küstenkarte mit präziser Interpretation von Tiefenlinien und geografischen Merkmalen. Für Apple-Silicon-Nutzer:innen ist das Modell bereits in verschiedenen optimierten Versionen (4-bit, 6-bit, 8-bit und bf16) verfügbar.
Das Qwen-Team kündigt an, sich bei der Weiterentwicklung auf längere und effektivere Reasoning-Prozesse konzentrieren zu wollen, um noch komplexere visuelle Aufgaben bewältigen zu können. Ende 2024 hatten die Entwickler:innen mit QVQ ihr erstes multimodale Modell mit Reasoning-Fähigkeiten präsentiert.
Ursprünglicher Artikel vom 29. Januar 2025:
Alibabas Qwen2.5-VL könnte Basis für den Open-Source-Operator werden
Das chinesische Technologieunternehmen Alibaba hat seine aktuelle Qwen2.5-Serie um das multimodale VL-Modell ergänzt. Damit holt Alibaba immer weiter zur kommerziellen Konkurrenz auf.
Die neue Version baut auf dem im Herbst 2024 vorgestellten Open-Source-Modell Qwen2-VL auf und soll laut dem Forschungsteam noch besser mit verschiedenen Datentypen wie Text, Bild und Video bis zu einer Stunde Laufzeit umgehen können. Insbesondere bei Diagrammen, Icons, Grafiken und Layouts verspricht Alibaba Fortschritte. Das Modell ist in Versionen mit 3, 7 und 72 Milliarden Parametern verfügbar.
Diese Verbesserungen sollen das Modell als visuellen Agenten besonders nützlich machen. In verschiedenen Demos zeigt Alibaba, wie Qwen2.5 Bildschirminhalte analysiert und Anweisungen ausgibt, die dann per Mausklick ausgeführt werden.
In dieser Demo hilft Qwen2.5-VL ausgehend von Start- und Zielort beim Buchen eines Flugtickets. | Video: Qwen
Hier hilft Qwen2.5-VL die Wettervorhersage für Manchester, UK abzurufen. | Video: Qwen
Auch komplexere Bedienoberflächen wie die von Gimp kann Qwen2.5-VL verstehen. | Video: Qwen
Qwen2.5 ist aber immer noch ein multimodales VLM und kein spezialisiertes Agentenmodell wie die kürzlich von OpenAI vorgestellte CUA, die Operator antreibt. Dennoch ist es gut darin, Oberflächen zu analysieren, geeignete Schaltflächen zu identifizieren und Abläufe zu planen. Im richtigen Framework könnte es so als das "Gehirn" in einem Open-Source-Operator dienen.
Qwen2.5 schlägt GPT-4o und Claude 3.5 Sonnet in Benchmarks
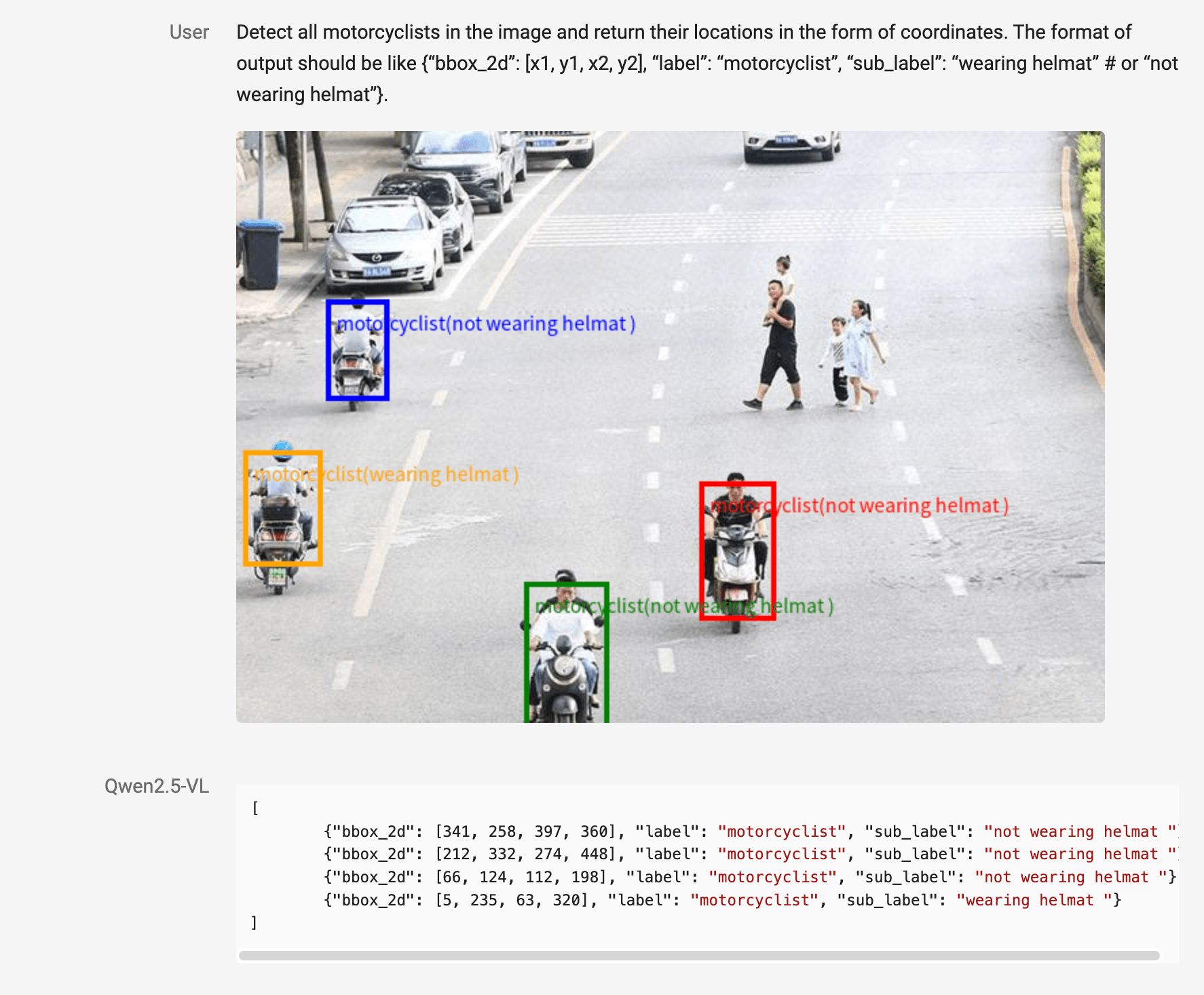
Qwen2.5-VL kann außerdem einzelne Objekte und ihre Teile präzise identifizieren und so etwa erkennen, ob ein Motorradfahrer einen Helm trägt oder nicht. Für Dokumente wie Rechnungen und Formularen können die extrahierten Informationen in einer strukturierten Form wie JSON ausgegeben und so leichter weiterverwendet werden.
Alibaba gibt an, dass Qwen2.5-VL-72B in verschiedenen Benchmarks gleichauf mit OpenAIs GPT-4o, Claude 3.5 Sonnet und Gemini 2.0 Flash ist und in einigen diese sogar übertrifft. Das gilt vor allem für Bereiche wie Dokumentenverständnis und den Einsatz als visueller Agent ohne spezielles Training.
Auch die kleineren Modelle Qwen2.5-VL-7B-Instruct und Qwen2.5-VL-3B sollen in vielen Aufgaben besser abschneiden als GPT-4o-Mini und die Vorgängerversion Qwen2-VL.
Qwen plant omnimodales Modell wie GPT-4o
Für die Zukunft plant das Qwen-Team die Weiterentwicklung der Modelle, insbesondere im Hinblick auf Problemlösungs- und Reasoning-Fähigkeiten sowie die Integration zusätzlicher Modalitäten. Langfristiges Ziel ist die Erstellung eines Omni-KI-Modells für alle möglichen Eingabearten und Aufgaben, also etwa auch für Spracheingabe in Audioform. Ein Paper mit weiteren Informationen zu Architektur und Training ist in Arbeit.
Die Qwen2.5-VL-Modelle sind quelloffen auf GitHub, Hugging Face und ModelScope sowie dem jüngst eingeführten ChatGPT-Klon Qwen Chat verfügbar, unterliegen jedoch teilweise Beschränkungen für die kommerzielle Nutzung. Aufgrund gesetzlicher Vorgaben in China lehnen die Modelle wie auch jene von Deepseek zudem die Diskussion bestimmter, von den Behörden als sensibel eingestufter Themen ab.
Die im September gestartete Qwen2.5-Serie wurde kürzlich außerdem um ein Modell mit einem Kontextfenster von bis zu einer Million Token erweitert.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.