Erratische Gedankensprünge beeinflussen die Leistung von Reasoning-LLMs wie o1
Eine neue Studie untersucht das Phänomen des "Underthinking" in Large Reasoning Models wie OpenAI o1. Häufige Strategiewechsel während des Reasoning-Prozesses führen zu einer ineffizienten Ressourcennutzung und beeinträchtigen die Genauigkeit bei komplexen Aufgaben.
Die Studie zeigt, dass "o1-ähnliche" KI-Modelle ein Phänomen aufweisen, das die Forscher "Underthinking" nennen: Die Modelle neigen demnach dazu, vielversprechende Lösungsansätze zu früh aufzugeben und stattdessen häufig zwischen verschiedenen Strategien hin- und herzuspringen. Häufig leiten sie den Gedankensprung mit einem "Alternativ …" ein.

Die Forscher stellten fest, dass die Modelle bei falschen Antworten deutlich häufiger zwischen verschiedenen Denkansätzen wechselten als bei richtigen Lösungen. Je schwieriger die Aufgaben waren, desto ausgeprägter war der "Gedankensprung-Effekt". 70 Prozent der falschen Antworten enthielten zudem mindestens einen richtigen Gedankengang, der aber offensichtlich nicht zu Ende gedacht wurde.
Weshalb ist das ein Problem? Mehr Gedankenwechsel führen zu mehr falschen Antworten führen zu mehr Tokenverbrauch. Underthinking führt so dazu, dass Modelle ihre Rechenressourcen ineffizient nutzen und letztlich weniger genaue Ergebnisse liefern, insbesondere bei anspruchsvollen mathematischen Aufgaben.
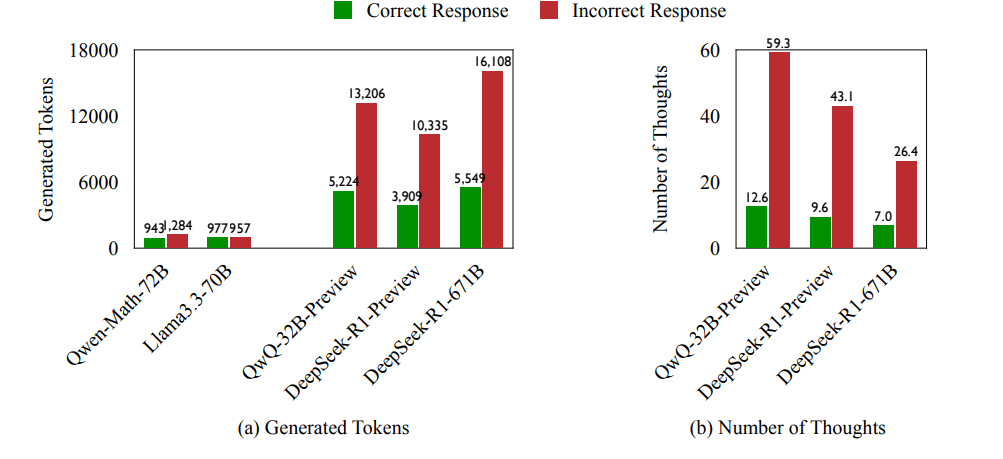
Die Wissenschaftler untersuchten das Problem systematisch anhand von drei anspruchsvollen Testsätzen, darunter mathematische Wettbewerbsaufgaben und Fragen aus Physik und Chemie auf Hochschulniveau. Dabei zeigte sich, dass die untersuchten Modelle QwQ-32B-Preview und DeepSeek-R1-671B bei falschen Antworten durchschnittlich 225 Prozent mehr Token verbrauchten und 418 Prozent häufiger zwischen verschiedenen Gedankengängen wechselten als bei richtigen Antworten.
Neue Methode verbessert KI-"Denkprozesse"
Um das Ausmaß des "Underthinking" zu messen, entwickelten die Forscher eine Metrik, die die Token-Effizienz in fehlerhaften Antworten bewertet. Die Metrik ermittelt, welcher Anteil der generierten Tokens tatsächlich dazu beiträgt, einen korrekten Lösungsansatz zu verfolgen, bevor das Modell zu einer anderen Strategie übergeht.
Die Ergebnisse zeigten, dass o1-ähnliche LLMs unter erheblichem "Underthinking" leiden. Es zeigte sich auch, dass eine höhere Genauigkeit bei Antworten nicht immer mit weniger "Underthinking" einhergeht.
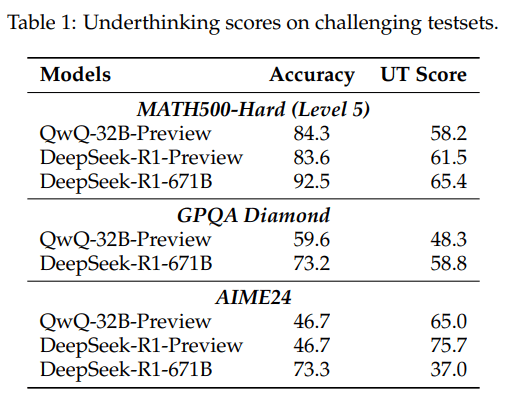
Als Lösungsansatz für das "Underthinking"-Problem schlagen die Studienautoren eine neue Decoding-Strategie namens "Thought Switching Penalty" (TIP, Gedankenwechsel-Strafe) vor.
Dabei wird der Wechsel zwischen verschiedenen Denkansätzen während des Reasoning-Prozesses "bestraft", indem die Wahrscheinlichkeit für entsprechende Token, etwa für "Alternativ", verringert wird. Auf diese Weise wird das Modell indirekt dazu gebracht, weniger häufig die Denkstrategie zu wechseln und stattdessen den aktuellen Ansatz weiterzuverfolgen.
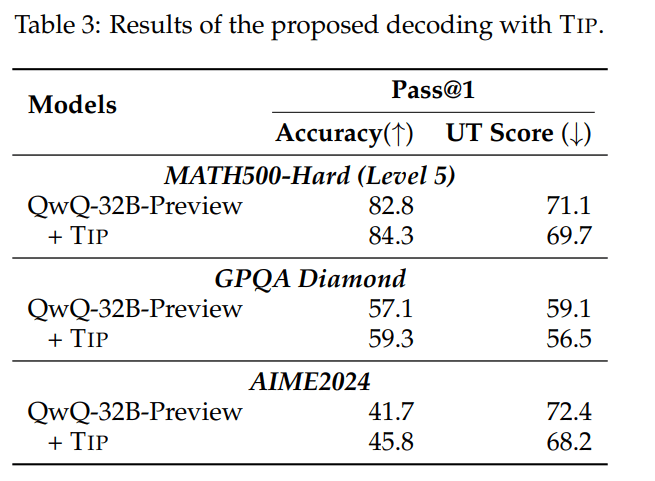
In Experimenten mit QwQ-32B-Preview konnten die Forscher zeigen, dass die TIP-Methode die Genauigkeit des Modells über verschiedene anspruchsvolle Datensätze im Bereich Mathe und STEM hinweg konsistent verbessert. Bei MATH500-Hard stieg die Genauigkeit von 82,8 auf 84,3 Prozent, während der Wert für "Underthinking" von 71,1 auf 69,7 sank.
Ähnliche Verbesserungen wurden auch bei GPQA Diamond und AIME2024 festgestellt. Die TIP-Methode lässt sich ohne Fine-Tuning und daher mit vergleichsweise geringem Aufwand auf bestehende "o1-ähnliche" LLMs anwenden.
Effizientes Denken in KI-Modellen hängt also neben der reinen Rechenleistung auch von der Fähigkeit ab, vielversprechende Gedankengänge konsequent zu verfolgen. In zukünftigen Arbeiten wollen die Forscher unter anderem untersuchen, wie Underthinking durch adaptive Mechanismen reduziert werden kann, bei denen die Modelle selbst lernen, Gedankensprünge zu regulieren.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.