KI überwacht KI: Wachsende Ähnlichkeit von Sprachmodellen birgt Risiken

Wenn Künstliche Intelligenz zur Bewertung und Kontrolle anderer KI-Systeme eingesetzt wird, kann deren zunehmende Ähnlichkeit problematisch sein. Das zeigt eine neue Studie, die eine Metrik zur Messung funktionaler Ähnlichkeit von Sprachmodellen vorstellt.
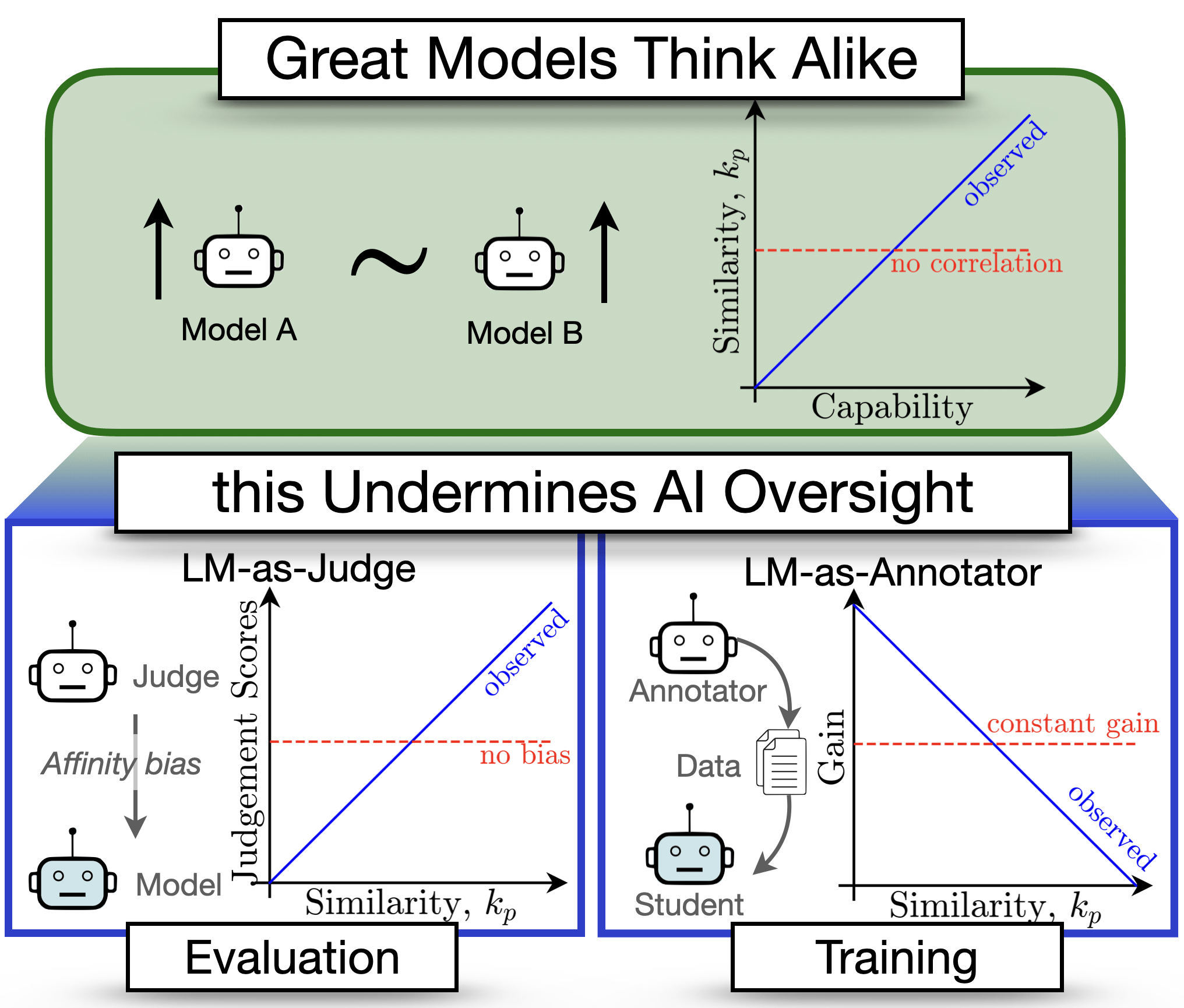
Sprachmodelle werden zunehmend zur Bewertung und Überwachung anderer KI-Systeme eingesetzt. Doch je besser die Modelle werden, desto ähnlicher werden ihre Fehler. Das kann die Vorteile solcher "KI-Aufsicht durch KI"-Ansätze untergraben, warnen Wissenschaftler:innen in einer neuen Studie.
Ein Forschungsteam verschiedener Institutionen aus Tübingen, Hyderabad (Indien) und Stanford hat dafür eine neue Metrik namens CAPA (Chance Adjusted Probabilistic Agreement) entwickelt. Sie misst, wie ähnlich sich zwei Sprachmodelle in ihren Fehlern sind - und zwar über das hinaus, was man aufgrund ihrer Genauigkeit erwarten würde.
KI-Richter bevorzugen ihnen ähnliche Modelle
In einem ersten Experiment ließen die Forschenden Sprachmodelle als "Richter" die Ausgaben anderer Modelle bewerten. Die KI-Richter gaben durchweg Modellen höhere Bewertungen, die mehr Fehler mit ihnen teilten. Und zwar auch dann, wenn man die tatsächliche Leistungsfähigkeit der bewerteten Modelle berücksichtigt.
"Es hat sich gezeigt, dass menschliche Interviewer voreingenommen gegenüber Kandidaten mit ähnlichen Kenntnissen und Eigenschaften sind, ein Phänomen, das als Affinitätsverzerrung bezeichnet wird", erklären die Forschenden. "Wir untersuchen, ob Sprachmodelle auch eine Verzerrung gegenüber ähnlichen Modellen zeigen."
Unähnlichkeit treibt Lernerfolg beim Training
In einem zweiten Experiment untersuchte das Team, was passiert, wenn man ein leistungsfähiges Modell auf den Ausgaben eines schwächeren Modells trainiert. Diese sogenannten synthetischen Daten spielen schon länger eine Rolle, um dem wachsenden Bedarf an Trainingsmaterial nachzukommen. Hier zeigte sich: Je unähnlicher sich die beiden Modelle waren, desto mehr profitierte das stärkere Modell vom Training auf den generierten Inhalten des schwächeren Modells.
Der Grund dafür ist laut den Forscher:innen, dass unähnliche Modelle über komplementäres Wissen verfügen. Dieses Potenzial werde beim Training besser ausgeschöpft. Die Studie liefert damit auch neue Erkenntnisse darüber, warum die Leistungssteigerung bei solchen "Weak-to-Strong"-Ansätzen von Aufgabe zu Aufgabe variiert.
Wachsende Ähnlichkeit der Fehler birgt Sicherheitsrisiken
Problematisch ist jedoch der generelle Trend, den die Forschenden bei der Analyse von über 130 Sprachmodellen entdeckten: Mit zunehmender Leistungsfähigkeit der Modelle werden auch deren Fehler immer ähnlicher. Das ist vor allem dann problematisch, wenn wir uns bei der Bewertung und Kontrolle von KI-Systemen immer mehr auf KI verlassen.
"Unsere Ergebnisse deuten auf das Risiko hin, dass bei der KI-Aufsicht durch KI gemeinsame blinde Flecken und Ausfallmodi auftreten, was für die Sicherheit bedenklich ist", warnen die Wissenschaftler:innen.
Die Forscher:innen plädieren deshalb dafür, der Ähnlichkeit von KI-Modellen und der Diversität in ihren Fehlern mehr Beachtung zu schenken. Eine Forschungslücke sehen sie noch bei der Erweiterung ihrer Metrik auf Freitext- sowie Reasoning-Antworten großer Sprachmodelle.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.