Sesame veröffentlicht KI-Stimmengenerator CSM-1B als Open Source
Update –
- Open-Source-Veröffentlichung ergänzt
Update vom 14. März 2025:
Das KI-Unternehmen Sesame hat sein Basismodell CSM-1B als Open Source veröffentlicht. Der Code ist bei Github verfügbar.
Das eine Milliarde Parameter umfassende Modell steht unter der Apache-Lizenz 2.0 und kann damit weitgehend uneingeschränkt kommerziell genutzt werden. Die Audio-Generierung kann hier getestet werden. Eine feingetunte Variante von CSM-1B treibt auch die KI-Audio-Stimme von Maya an (siehe unten).
Interessant ist das Sicherheitskonzept von Sesame: Entwickler und Nutzer werden lediglich aufgefordert, das Modell nicht zum Klonen von Stimmen ohne Zustimmung, zur Erstellung irreführender Inhalte oder für andere "schädliche" Aktivitäten zu verwenden.
Für das Klonen von Stimmen reicht bereits eine Minute Ausgangsmaterial, was zahlreiche Betrugstechniken ermöglicht, zum Beispiel für gefälschte Anrufe. OpenAI hatte eine ähnliche Technologie nicht veröffentlicht, weil es einen solchen Missbrauch befürchtete. Das zeigt einmal mehr, dass es für proprietäre KI-Hersteller kaum einen Burggraben gibt.
Ursprünglicher Artikel vom 6. März 2025:
Sesame AI: Dieser Sprachassistant sagt "ähm", kichert und korrigiert sich selbst
Das kalifornische Start-up Sesame AI setzt auf gewollte Unvollkommenheiten in der Sprachausgabe. Ihr neues Modell soll ein erster Schritt zu authentischeren Dialogen und einer "Voice Presence" von Stimm-KIs sein.
Ersten Testberichten zufolge besticht Sesame vor allem durch Feinheiten wie Mikropausen, Betonungen und Lachen in den Dialogen. In einer Interaktion reagierte Sesames Avatarin Maya in Echtzeit auf ein plötzliches Kichern des Nutzers mit der Frage "Warum kicherst du?". - ein Zeichen für emotionale Aufmerksamkeit.
Auch menschliche Gewohnheiten wie Selbstkorrekturen mitten im Satz, Entschuldigungen für Unterbrechungen und Füllwörter wie "Ähm" werden vom System gezielt eingesetzt. Techradar hebt diese gewollten "Unzulänglichkeiten" positiv hervor, im Gegensatz zum polierten Corporate-Ton von ChatGPT oder Gemini.
In simulierten Anwendungen wie Gesprächen über Arbeitssorgen oder Partyplanungen antwortete und fragte das System situationsgerecht, statt auf Standardsätze zurückzugreifen.
Sesame AI nutzt semantische und akustische Token
Ein Paper gibt es bisher nicht, aber der Blogeintrag gibt einen kleinen Einblick in die Architektur. Das CSM von Sesame basiert auf einer zweigeteilten Transformer-Architektur: einem Backbone-Transformer (1–8 Milliarden Parameter) für die Basisverarbeitung und einem kleineren Decoder (100–300 Millionen Parameter) für die Audiogenerierung.
Die Sprachverarbeitung erfolgt über zwei Arten von Tokens: semantische Tokens für linguistische Eigenschaften und Phonetik und akustische Tokens für Klangeigenschaften wie Stimmlage und Betonung. Um das Training zu optimieren, wird der Audio-Decoder nur auf einem Sechzehntel der Audio-Frames trainiert, während die semantische Verarbeitung alle Daten verwendet.
Das Training umfasste eine Million Stunden englischsprachiger Audiodaten aus fünf Epochen. Das System verarbeitet Sequenzen von bis zu 2048 Tokens (etwa zwei Minuten Audio) in einer End-to-End-Architektur. Diese technische Umsetzung unterscheidet sich von klassischen Text-to-Speech-Systemen durch die integrierte Verarbeitung von Text und Audio.
Welches Sprachmodell hinter der Stimme steckt, erklärt Sesame nicht direkt im Blogbeitrag. Auf Nachfrage erklärt die Demo-Stimme jedoch, dass es sich um eine 27 Milliarden Parameter umfassende Version von Googles Open-Source-LLM Gemma handelt.
Kaum Unterschiede zwischen Mensch und KI erkannt
In Blindtests mit Sesame erkannten die Probanden bei kurzen Gesprächsausschnitten keinen Unterschied zwischen CSM und echten Menschen. Bei längeren Dialogen zeigten sich jedoch noch Schwächen wie gelegentliche unnatürliche Sprechpausen und Audioartefakte.
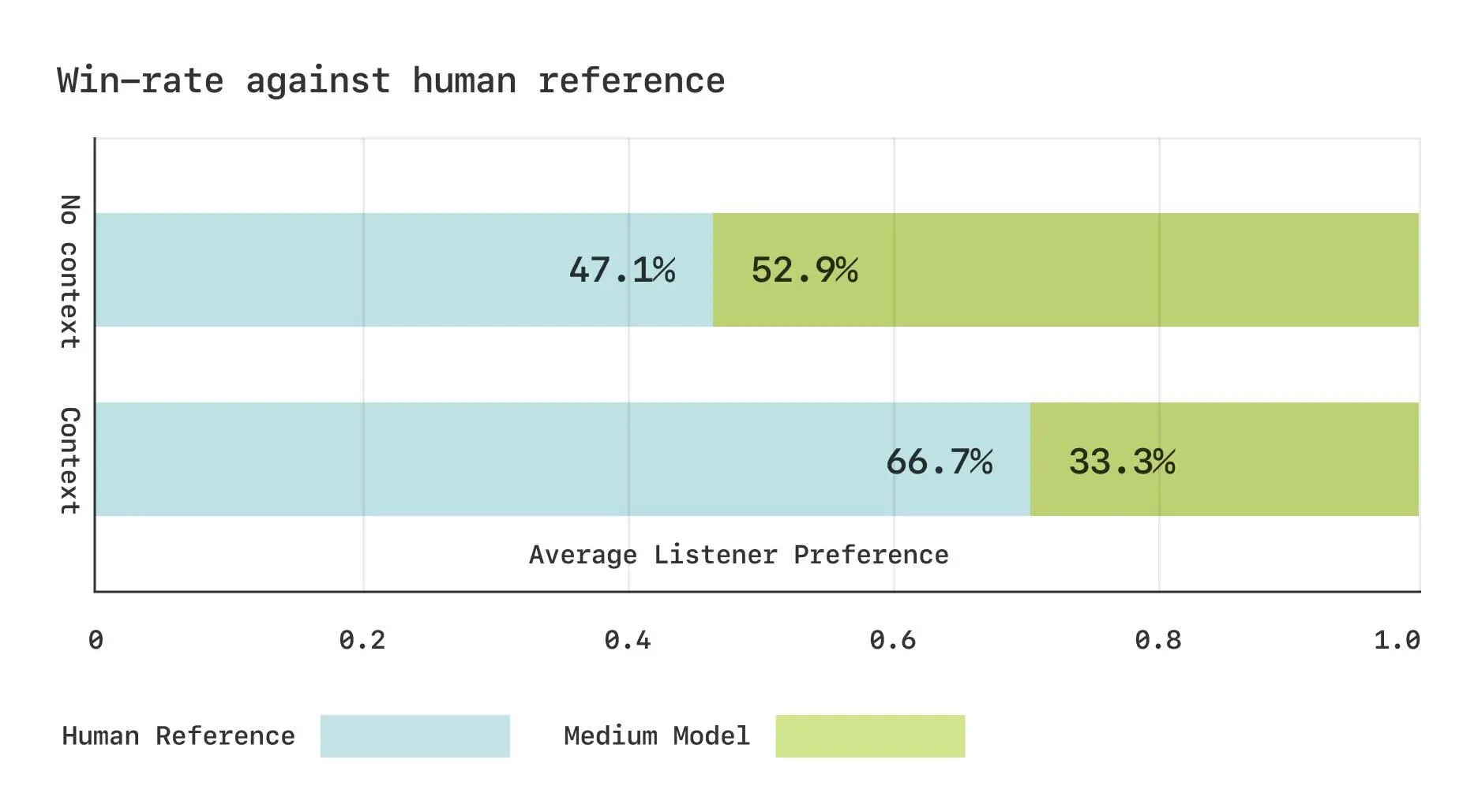
Um die Leistung des Modells zu messen, entwickelte Sesame eigene phonetische Benchmarks. In Hörversuchen beurteilten die Testpersonen die generierte Sprache ohne Kontext als gleichwertig mit den realen Aufnahmen, mit Kontext bevorzugten sie jedoch immer noch das Original.
Wichtige Modellkomponenten sollen Open-Source werden
Sesame plant, wichtige Komponenten seiner Forschung als Open Source unter der Apache 2.0-Lizenz zur Verfügung zu stellen. In den kommenden Monaten soll das Modell sowohl in der Größe als auch im Trainingsumfang weiter skaliert werden. Zudem ist eine Erweiterung auf über 20 Sprachen geplant.
Ein besonderer Fokus liegt dabei auf der Integration vortrainierter Sprachmodelle und der Entwicklung voll duplexfähiger Systeme, die Gesprächsdynamiken wie Sprecher:innenwechsel, Pausen und Tempo direkt aus den Daten lernen können. Diese Entwicklung würde grundlegende Änderungen in der gesamten Verarbeitungskette erfordern, von der Datenkuration bis hin zu Post-Trainingsmethoden.
"Die Entwicklung eines digitalen Begleiters mit Sprachpräsenz ist nicht einfach, aber wir machen stetige Fortschritte an mehreren Fronten, einschließlich Persönlichkeit, Gedächtnis, Ausdrucksfähigkeit und Angemessenheit", resümieren die Entwickler:innen.
Sesame AI wurde von einem Team um den ehemaligen Oculus-CTO Brendan Iribe gegründet. In einer ersten Series-A-Finanzierungsrunde konnte das Startup namhafte Investoren gewinnen, angeführt von Andreessen Horowitz. Eine Demo ist verfügbar.
Welchen Einfluss natürliche KI-Stimmen auf die Akzeptanz von Assistenten haben können, hat der Hype um den Advanced Voice Mode von ChatGPT gezeigt. Gleichzeitig dürften sich Sprachassistenten mit LLM generell immer mehr durchsetzen, wie die Veröffentlichung von Amazons neuer Alexa+ vermuten lässt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.