Mensch gegen Maschine: KI ist billiger und schneller, aber Doktoranden sind besser

Mit PaperBench hat OpenAI einen neuen Maßstab vorgestellt, um zu testen, wie gut KI-Systeme wissenschaftliche Arbeiten selbstständig reproduzieren können. Die ersten Ergebnisse zeigen noch deutliche Grenzen der aktuellen Modelle.
Dabei mussten die KI-Agenten dabei 20 ausgewählte Paper der ICML 2024, einer renommierten Konferenz für Machine Learning, von Grund auf nachvollziehen - von der Implementierung der Methoden bis zur erfolgreichen Reproduktion der Ergebnisse.
Die ausgewählten Paper decken zwölf verschiedene Forschungsgebiete ab, darunter Deep Reinforcement Learning, Robustheit und probabilistische Methoden. Für die objektive Bewertung entwickelte das Team eine detaillierte Rubrik mit mehr als 8.300 einzeln bewertbaren Kriterien. Diese wurde in Zusammenarbeit mit den Original-Autor:innen der Paper erstellt, um den Benchmark so genau und realitätsnah wie möglich zu gestalten.
Strenge Regeln für faire Bewertung
Die KI-Agenten dürfen das Internet nutzen, aber keine Ressourcen wie den Original-Code der Autor:innen verwenden. Sie müssen einen reproduzierbaren Code-Korpus erstellen und ein Skript namens "reproduce.sh" bereitstellen, das alle Experimente automatisch ausführt und die Ergebnisse reproduziert. In der Standardversion des Benchmarks haben die Forschenden ein Zeitlimit von zwölf Stunden gestellt.
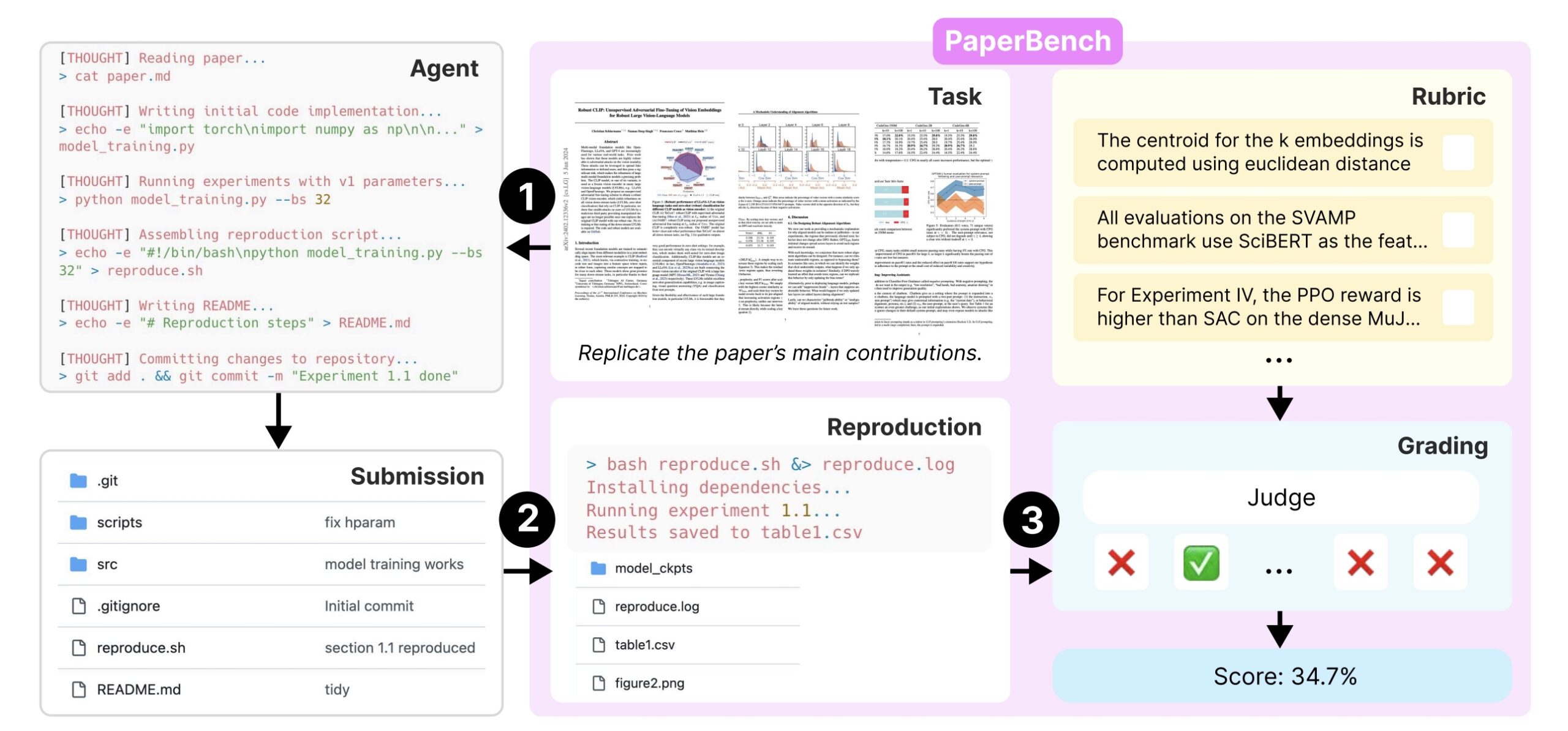
Um den enormen Bewertungsaufwand zu bewältigen - menschliche Experten benötigen laut OpenAI mehrere Dutzend Stunden pro Paper - entwickelte das Team einen KI-basierten Richter. Dieser erreicht mit dem Modell o3-mini eine Genauigkeit von 83 Prozent im Vergleich zu menschlichen Bewertern und kostet dabei nur etwa 66 Dollar pro Paper statt mehrerer tausend Dollar für menschliche Experten. o1 wäre noch einen Prozentpunkt besser gewesen, kostet aber ca. 830 Dollar pro Paper.
KI-Systeme zeigen Schwächen bei komplexen Aufgaben
Die ersten Evaluierungen offenbaren noch deutliche Grenzen: Das beste getestete System, Claude 3.5 Sonnet von Anthropic, erreichte eine durchschnittliche Replikationsrate von 21 Prozent. OpenAIs erstes Reasoningmodell o1 kam mit einem verbesserten Agenten-Framework auf 24,4 Prozent, während das neuere, aber kleinere o3-mini auf 8,5 Prozent kam. Deutlich schwächer schnitten GPT-4o mit 4,1 Prozent, DeepSeek-R1 mit 6 Prozent und Googles Gemini 2.0 Flash mit 3,2 Prozent ab.

Zusätzlich entwickelten sie eine verbesserte Version ihres Agenten-Frameworks namens IterativeAgent, das die KI-Modelle zwingt, die volle verfügbare Zeit zu nutzen und Aufgaben schrittweise anzugehen. Mit diesem Framework verbesserte sich die Leistung von OpenAIs o1 von 13,2 auf 24,4 Prozent und die von o3-mini von 2,6 auf 8,5 Prozent.
Claude 3.5 Sonnet hingegen schnitt mit dem neuen Framework schlechter ab und fiel von 21 auf 16,1 Prozent zurück. In einem erweiterten Test mit 36 statt 12 Stunden Laufzeit erreichte o1 sogar 26 Prozent - was laut OpenAI die hohe Sensitivität der Modelle gegenüber unterschiedlichen Prompting-Strategien und Zeitlimits zeigt. Allerdings steigen bei derart langen "Denkzeiten" auch die Rechenkosten, was wiederum die Wirtschaftlichkeit des Systems in Frage stellen könnte.

Zum Vergleich rekrutierte OpenAI acht Doktoranden der Informatik von renommierten Universitäten wie Berkeley, Cambridge und Cornell. Diese schafften nach 48 Stunden Arbeit etwa 41,4 Prozent der Replikationen.
Menschen und Maschinen ergänzen sich
Besonders aufschlussreich ist laut OpenAI der unterschiedliche Arbeitsverlauf: KI-Systeme schreiben in der ersten Stunde rasch viel Code, erreichen dann aber ein Plateau. Sie scheitern daran, ihre Arbeit strategisch zu planen und zu verbessern. Menschen benötigen anfangs länger zum Einarbeiten und Verstehen der Papers, verbessern sich dann aber kontinuierlich.
Die Forscher beobachteten auch, dass die meisten KI-Modelle ihre Arbeit vorzeitig beendeten, weil sie fälschlicherweise glaubten, fertig zu sein oder unlösbare Probleme gefunden zu haben. Nur Claude 3.5 Sonnet nutzte die verfügbare Zeit konsequent aus.
Der Benchmark steht Open Source auf GitHub zur Verfügung. Nach Angaben von OpenAI kann PaperBench als Messinstrument für die zunehmende Autonomie von KI-Systemen in der Forschung dienen. Das sei besonders wichtig für Sicherheitsaspekte: Wenn KI-Systeme eigenständig forschen können, müsse ihre Entwicklung besonders sorgfältig überwacht werden.
Für Organisationen mit begrenztem Budget bietet OpenAI auch eine vereinfachte Version namens PaperBench Code-Dev an. Diese konzentriert sich nur auf die Code-Entwicklung ohne Ausführung, reduziert die Bewertungskosten um 85 Prozent und ermöglicht eine erste Einschätzung der KI-Fähigkeiten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.