KI erzeugt GPU-Kernels, die PyTorch in mehreren Tests übertreffen
Ein Team an der Stanford University zeigt, dass große Sprachmodelle überraschend effiziente GPU-Kernels erzeugen können. Einige dieser automatisch generierten Varianten laufen schneller als die Standardfunktionen des populären KI-Frameworks PyTorch.
Genauer gesagt handelt es sich um sogenannte CUDA-C-Kernels: kleine, spezialisierte Programme, die direkt auf Nvidia-GPUs ausgeführt werden, um einzelne Rechenschritte wie etwa Matrixmultiplikationen oder Bildverarbeitung effizient umzusetzen.
Diese Kernels wurden automatisch von Sprachmodellen erzeugt und mit den Standardfunktionen von PyTorch verglichen. PyTorch ist ein weit verbreitetes Framework für maschinelles Lernen, das unter anderem von Meta entwickelt wird. Es stellt vorgefertigte Rechenoperationen bereit, die auf GPUs ausgeführt werden und für viele KI-Anwendungen essenziell sind.
Mehrfach liefen die automatisch erzeugten Varianten schneller als die Standardroutinen in PyTorch. So beschleunigten sie die sogenannte Layer-Normalisierung – ein Zwischenschritt, der die Werte eines neuronalen Netzwerks auf ein vergleichbares Niveau bringt – um das 4,8-Fache.
Ähnliche Vorteile gab es bei der Bildfaltung (Conv2D), die Bildinformationen mit Filtern kombiniert, bei der Softmax-Funktion, die Rohwerte in Wahrscheinlichkeiten umrechnet, sowie bei einer Kombi-Operation aus Bildfaltung, ReLU-Aktivierung (negative Zahlen werden einfach auf Null gesetzt) und Max-Pooling, bei dem aus jedem kleinen Bildausschnitt nur der höchste Zahlenwert weitergereicht wird. In all diesen Fällen war der KI-generierte Code teils deutlich schneller.
Optimierung durch parallele Suchverfahren
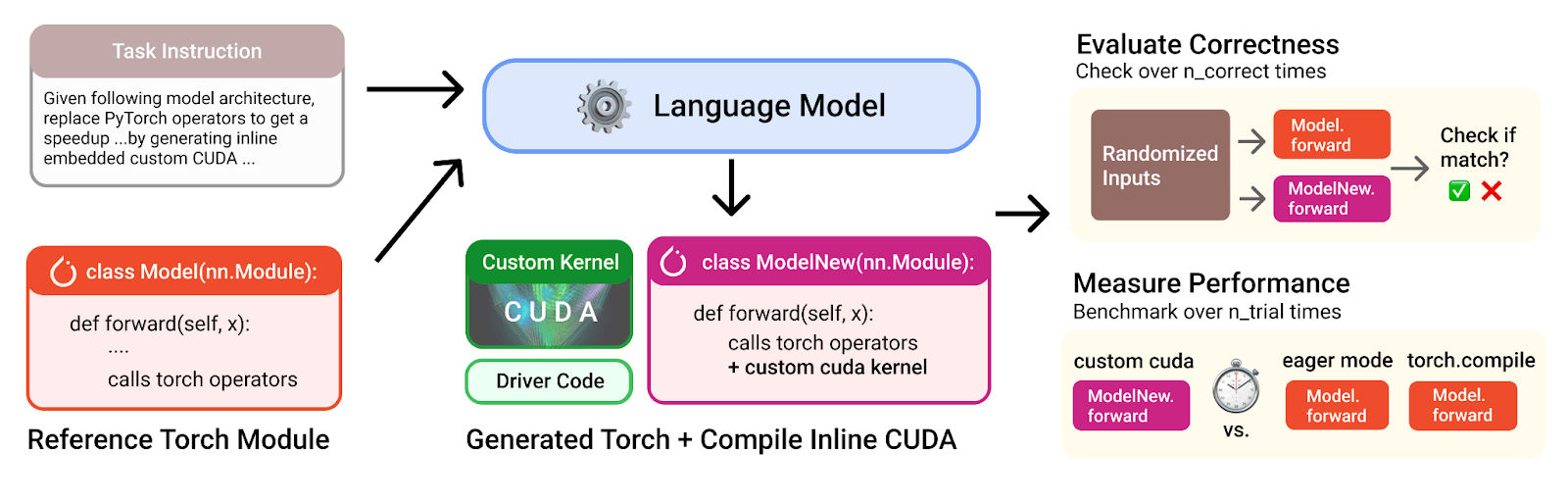
Die Grundlage der Experimente bildete ein Benchmark namens KernelBench. Dort soll ein Sprachmodell einzelne PyTorch-Operatoren durch eigene CUDA-Implementierungen ersetzen, mit dem Ziel, die Ausführung auf der GPU zu beschleunigen.
Zum Einsatz kamen dabei die großen Sprachmodelle OpenAI o3 und Gemini 2.5 Pro, die jeweils in mehreren Runden parallelisierte Optimierungsstrategien verfolgten. Die Ergebnisse werden dabei auf Korrektheit und Geschwindigkeit überprüft.
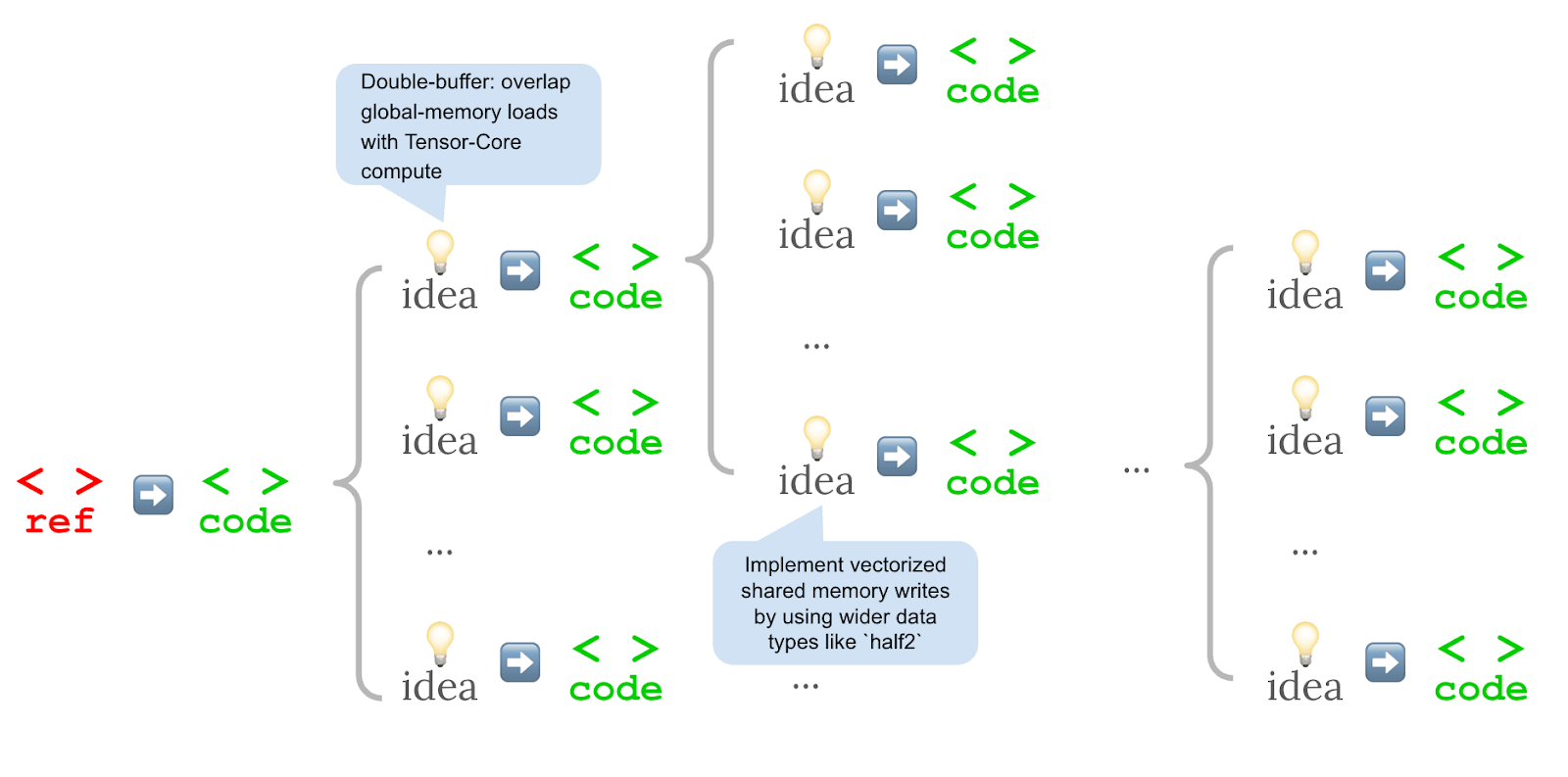
Im Unterschied zu herkömmlichen Verfahren, die nacheinander minimale Verbesserungen an einem Kernel vornehmen, setzt der neue Ansatz auf zwei Veränderungen: Zuerst wurden Optimierungsideen in natürlicher Sprache formuliert, dann aus jeder Idee mehrere Codevarianten gleichzeitig erzeugt. Diese werden parallel ausgeführt und die schnellsten Varianten in die nächste Runde übernommen.
Diese strukturierte Suche verbesserte die Vielfalt der Lösungsansätze. Die leistungsfähigsten Varianten nutzten bekannte Optimierungsstrategien wie effizientere Speicherzugriffe, gleichzeitige Ausführung von Rechen- und Speicheroperationen, geringere Datenpräzision (zum Beispiel FP16 statt FP32), bessere Auslastung der GPU-Recheneinheiten oder einfache Schleifenstrukturen mit weniger Verzweigungen.
Die Forschenden betonen, dass dieser Ansatz ergänzend und nicht als Ersatz für weiteres Training gedacht ist. Durch die gezielte Suche entstehen auch synthetische Daten, die wiederum für das Training künftiger Modelle genutzt werden können. Der Ansatz sei daher ein Werkzeug zur Optimierung zur Laufzeit und gleichzeitig ein Beitrag zu datenbasiertem Modellverbesserung.
Beispiel: Eine Faltungsoperation wird immer schneller
Ein konkretes Beispiel zeigt, wie sich ein automatisch erzeugter Kernel für eine Bildfaltung (Conv2D) innerhalb von 13 Varianten von 20 Prozent auf fast 180 Prozent der PyTorch-Leistung steigern ließ. Dieser Kernel führt eine grundlegende Operation im Bereich der Bildverarbeitung aus, bei der Eingabebilder mit Filtermatrizen verrechnet werden.
Zu den Verbesserungen zählte unter anderem die Umwandlung der Faltung in eine Matrixmultiplikation, die auf spezialisierte Tensor-Cores der GPU zugreift. Außerdem wurde sogenanntes Double Buffering eingesetzt, um Rechen- und Speicherprozesse zu überlappen. Auch das Vorberechnen von Speicherzugriffsindizes in einem schnellen Zwischenspeicher (Shared Memory) trug zur Leistungssteigerung bei.
Das Ergebnis nutzte fortgeschrittene Programmiertechniken, die normalerweise nur von erfahrenen CUDA-Entwicklern umgesetzt werden.
Schwachstellen bei FP16, aber stetige Fortschritte
Trotz der Erfolge gibt es Einschränkungen. Besonders bei modernen KI-Operationen mit geringerer Datenpräzision wie FP16 zeigten sich noch Leistungsdefizite. So erreichte ein automatisch erzeugter Kernel für die Matrixmultiplikation mit FP16 nur 52 Prozent der PyTorch-Leistung. Bei Flash Attention, einer speicherintensiven Technik zur Gewichtung von Eingaben in großen Sprachmodellen, lag der Wert sogar nur bei 9 Prozent.
Allerdings betonen die Forschenden, dass solche Operationen zuvor überhaupt nicht zuverlässig erzeugt werden konnten. Das aktuelle Verfahren stellt daher bereits einen Fortschritt dar. Zudem war das verwendete Suchbudget vergleichsweise klein.
Die Ergebnisse stehen in einer Reihe mit anderen Arbeiten, die ebenfalls zeigen, dass parallele Suchstrategien mit gutem Sprachverständnis leistungsfähige Systemkomponenten hervorbringen können, etwa AlphaEvolve von Deepmind und Gemini 2.5 Pro Deep Think.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.