Apple-Forscher äußern grundlegenden Zweifel an "Denkfunktion" von "Reasoning"-LLMs

Reasoning-Modelle wie Claude 3.7 oder Deepseek-R1 sollen durch simuliertes Denken bessere Leistungen bei komplexen Aufgaben zeigen. Eine neue Apple-Studie zeigt jedoch, dass sie bei steigender Komplexität nicht nur scheitern, sondern paradoxerweise auch weniger nachdenken.
Large Reasoning Models (LRMs) wie Claude 3.7 Sonnet Thinking, Deepseek-R1 oder OpenAIs o3 gelten bei manchen als nächster Entwicklungsschritt auf dem Weg zu einer allgemeinen künstlichen Intelligenz. Sie sollen durch Mechanismen wie Chain-of-Thought oder Selbstreflexion besser mit komplexen Logikaufgaben umgehen und stärker generalisieren können als klassische Sprachmodelle.
Eine neue Studie von Apple-Forschern stellt diese Annahme jedoch infrage. Die Untersuchung offenbart strukturelle Schwächen in der Skalierbarkeit dieser Denkprozesse und identifiziert drei klar abgegrenzte Leistungsniveaus – mit einem vollständigen Zusammenbruch bei hohem Schwierigkeitsgrad.
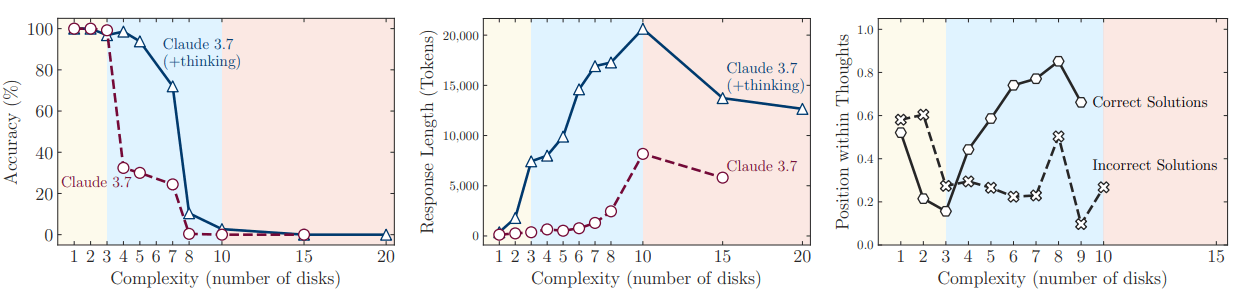
Drei Regime des Denkens
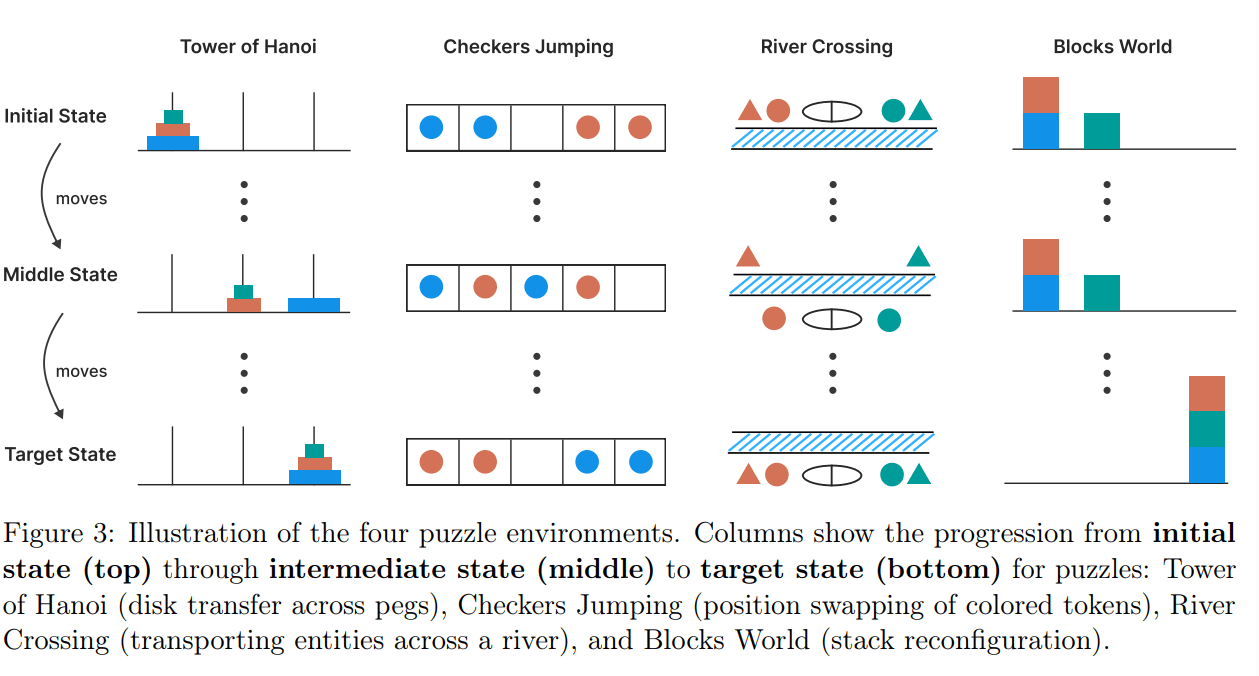
Die Forscher testeten mehrere Reasoning-Modelle in vier kontrollierbaren Puzzle-Umgebungen: Tower of Hanoi, Checkers Jumping, River Crossing und Blocks World. In diesen Szenarien lässt sich die Komplexität systematisch steigern, ohne die zugrunde liegende Logik zu verändern.
Die Ergebnisse zeigen: Bei einfachen Aufgaben schneiden klassische LLMs ohne Denkfunktion – etwa Claude 3.7 ohne "thinking"-Modus – besser ab. Sie sind präziser und benötigen weniger Tokens. Erst bei mittlerer Komplexität zeigen Reasoning-Modelle wie Claude 3.7 Thinking oder DeepSeek-R1 Vorteile.
Doch bei hoher Komplexität versagen alle Modelle gleichermaßen: Die Genauigkeit sinkt auf null, trotz ausreichendem Compute-Budget. Auffällig dabei: Gerade bei den schwierigsten Aufgaben reduzieren die Modelle die Anzahl ihrer reasoning tokens, obwohl sie prinzipiell länger hätten nachdenken können.
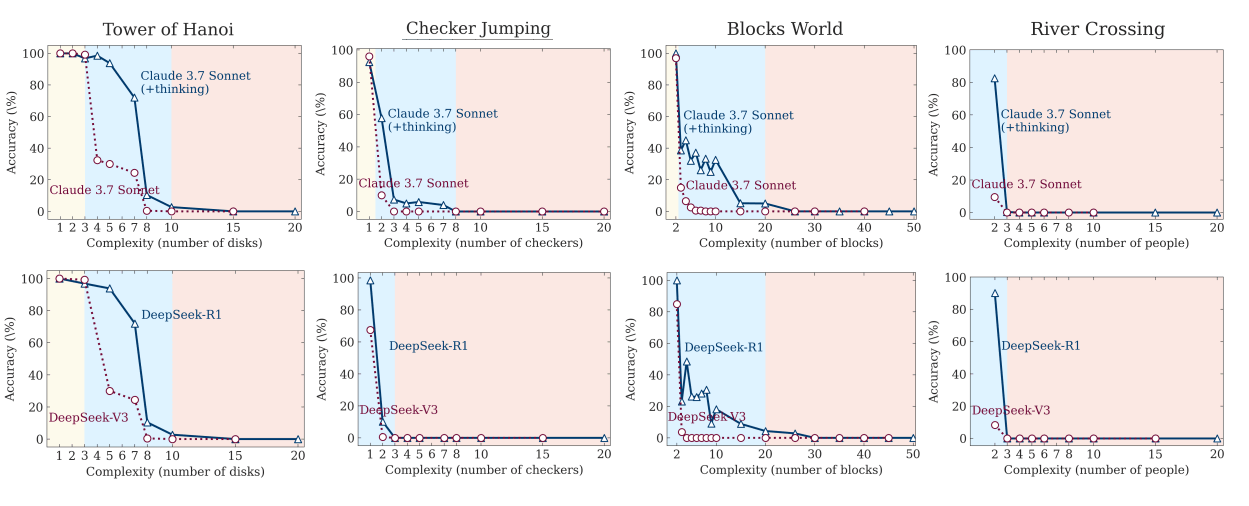
Overthinking und Underthinking
Ein Blick in die Denkpfade – die sogenannten reasoning traces – lieferte den Forschern weitere Erkenntnisse. Bei einfachen Aufgaben finden die Modelle korrekte Lösungen früh, explorieren aber mitunter dennoch weiter und produzieren fehlerhafte Varianten. Dieses ineffiziente Verhalten ist als Overthinking bekannt.
Bei mittlerer Komplexität kehrte sich dieser Trend um: Die Modelle fanden die richtige Antwort meist erst nach der Erkundung zahlreicher falscher Lösungswege.
Bei hoher Komplexität scheiterten die Modelle komplett und generierten keine korrekten Lösungen mehr in ihren Denkprozessen. Ein vollständiger Kollaps, der in ähnlicher Weise schon als Underthinking beschrieben wurde. Selbst die Vorgabe der Lösungsschritte änderte nichts daran, dass die Ausführung der Schritte bei Erreichen einer kritischen Problemgröße scheitert.
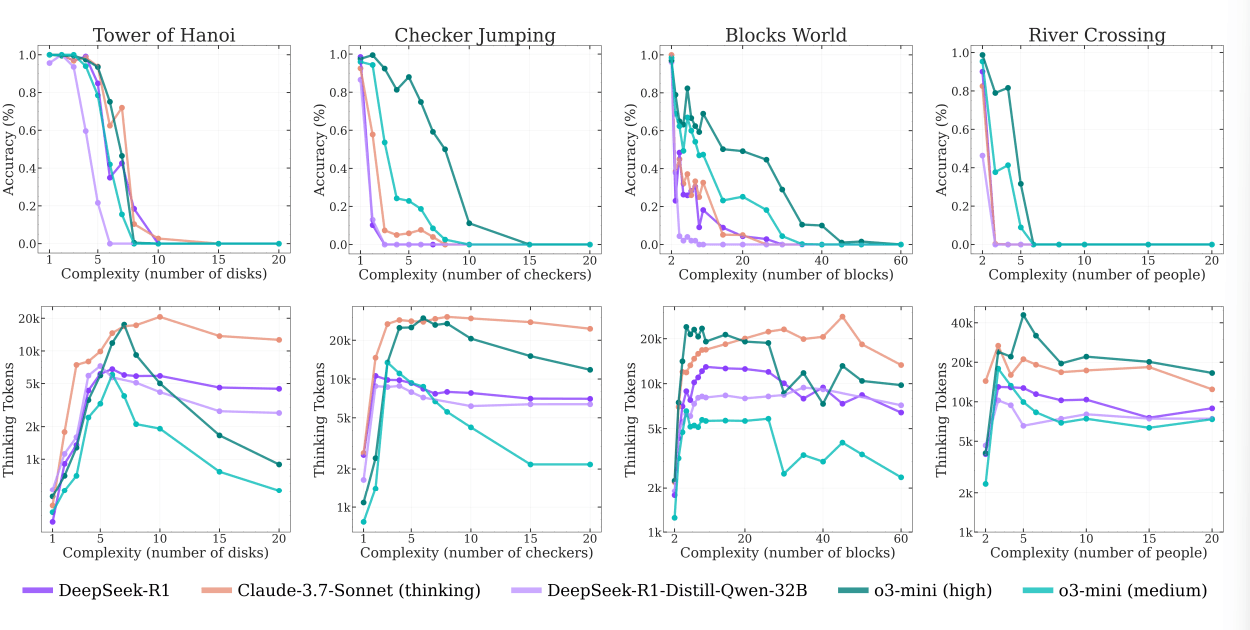
Ein weiteres von den Forschern beobachtetes Phänomen betrifft die unterschiedliche Leistung bei verschiedenen Puzzle-Arten. Sie vermuten, dass Unterschiede in der Verfügbarkeit von Beispielaufgaben in den Trainingsdaten eine Rolle spielen könnten: So taucht Tower of Hanoi häufiger im Web auf als etwa komplexe River-Crossing-Probleme, was die schlechtere Leistung bei letzteren erklären könnte.
Grenzen des maschinellen Denkens
Die Apple-Forscher ziehen ein klares Fazit: Aktuelle Denkmodelle entwickeln keine generalisierbaren Problemlösungsstrategien. Selbst mit aufwendigen Mechanismen wie Selbstreflexion und langen Denkpfaden gelingt es ihnen nicht, mit steigender Komplexität Schritt zu halten.
Sie sehen darin eine "fundamentale Skalierungsgrenze" in der Denkfähigkeit aktueller LRMs im Verhältnis zur Problemkomplexität. Die Ergebnisse der Apple-Forscher legen nahe, dass für robustes maschinelles Denken zentrale Designprinzipien heutiger Modelle überdacht werden müssten.
Diese Aussage hat Gewicht, insbesondere weil Unternehmen wie OpenAI stark auf Reasoning setzen, um über die klassische Skalierung per Vortraining hinauszukommen. Fortschritte durch Trainingsdaten und Modellgröße allein scheinen sich zu verlangsamen. Die Skalierung von Reasoning gilt als möglicher Ausweg.
Ob die in Puzzle-Umgebungen beobachteten Schwächen auf andere Denkdomänen übertragbar sind, bleibt offen. Die Testumgebungen erlauben zwar präzise Analysen, bilden aber nur einen kleinen Ausschnitt möglicher Denkaufgaben ab, schreiben die Apple-Forscher. Realweltliche, semantisch komplexe oder wissensintensive Probleme lassen sich mit solchen simulierten Szenarien nur begrenzt erfassen.
Eine andere Studie zeigte ebenfalls, dass Reasoning-Modelle in erster Linie eine Form der LLM-Optimierung sind, um Lösungen für im Post-Training optimierte Aufgaben wie Mathematik oder Coding verlässlicher zu erreichen. Sie verfügen jedoch nicht über grundlegende neue Fähigkeiten.
Zudem kritisierten Forscher kürzlich die Vermenschlichung von KI-Modellen bei der Darstellung von Gedankenketten in natürlicher Sprache. Letztlich handele es sich dabei nur um statistische Berechnungen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.