Forscher widersprechen Apple-Studie: LRMs meistern komplexe Aufgaben durch Werkzeuge
Forscher von Pfizer haben untersucht, ob die in Studien beobachteten Fähigkeitseinbrüche von Reasoning-Modellen bei komplexen Aufgaben durch den Einsatz von Werkzeugen ausgeglichen werden können.
Ein Forschungsteam von Pfizer kritisiert in einem Kommentar zentrale Schlussfolgerungen der Studie "The Illusion of Thinking", die bei wachsender Aufgabenkomplexität einen drastischen Leistungsabfall bei Large Reasoning Models (LRMs) dokumentiert.
Die Autoren der Studie, darunter mehrere Apple-Forscher, werten diesen Einbruch als Hinweis auf eine fundamentale Grenze maschinellen Denkens. Andere Studien kamen zu ähnlichen empirischen Ergebnissen, interpretieren sie jedoch weniger drastisch.
Das Pfizer-Team widerspricht der Apple-Interpretation deutlich: Der beobachtete Leistungseinbruch sei kein Ausdruck kognitiver Schranken, sondern ein Artefakt der Testumgebung. Insbesondere das Fehlen von Werkzeugen wie Programmierschnittstellen zwinge die Modelle in ein rein textbasiertes Format, das komplexe Aufgaben unnötig erschwert. So werde aus einem eigentlich lösbaren Problem ein Ausführungsproblem.
Warum LRMs an einfachen Aufgaben scheitern
Die Originalstudie testete LRMs wie Claude 3.7 Sonnet-Thinking oder Deepseek-R1 mit textbasierten Rätseln wie Tower of Hanoi oder River Crossing. Bei zunehmender Komplexität zeigten alle Modelle einen plötzlichen Einbruch ihrer Lösungskompetenz – ein sogenanntes "Reasoning Cliff".
Die Pfizer-Forscher sehen dieses Ergebnis jedoch als Artefakt einer unnatürlich eingeschränkten Umgebung: Die Modelle durften keine Werkzeuge wie Programmierschnittstellen nutzen und mussten ihre Überlegungen rein textbasiert formulieren. Das führe nicht zu einem Denk-, sondern zu einem Ausführungsproblem.
Das Pfizer-Team überprüfte diese These am Beispiel des Modells o4-mini: Ohne Toolzugriff erklärte das Modell eine eigentlich lösbare Variante des River-Crossing-Puzzles für unlösbar – offenbar, weil es sich die bisherigen Schritte nicht zuverlässig merken konnte. Ein bekanntes Problem aktueller Sprachmodelle, das auch durch die Apple-Studie belegt ist.
Das Versagen des Modells ohne Werkzeuge interpretieren die Forscher als eine Form von "erlernter Hilflosigkeit": Weil das LRM an der perfekten Ausführung einer langen Befehlskette scheitert, schlussfolgert es fälschlicherweise, dass die Aufgabe selbst unlösbar sei.
Außerdem hätten die Apple-Forscher das Problem des "kumulativen Fehlers" ignoriert: Bei einer Aufgabe mit tausenden Schritten sinke die Wahrscheinlichkeit einer perfekten Lösung mit jedem Schritt. Selbst bei einer extrem hohen pro-Schritt-Genauigkeit von 99,99 % liegt die Chance, ein komplexes "Tower of Hanoi"-Rätsel fehlerfrei zu lösen, bei unter 45 %. Der beobachtete Leistungsabfall könnte also im Rahmen der statistischen Erwartung liegen.
Werkzeuge ermöglichen höhere Denkebenen
In einem erweiterten Test untersuchten die Forscher zwei Modelle – GPT-4o und o4-mini – diesmal mit Zugriff auf ein Python-Tool. Beide lösten einfache Puzzlevarianten korrekt. Bei höherer Komplexität zeigten sich jedoch deutliche Unterschiede beim Umgang mit Fehlern.
GPT-4o nutzte ein Python-Tool zur Umsetzung einer plausiblen, aber fehlerhaften Strategie – und erkannte den Fehler nicht. Im Gegensatz dazu erkannte o4-mini Elemente die Schwäche seiner ursprünglichen Strategie, analysierte sie selbstständig und wählte eine neue, korrekte Lösungsmethode. Erst dadurch gelang die erfolgreiche Lösung.
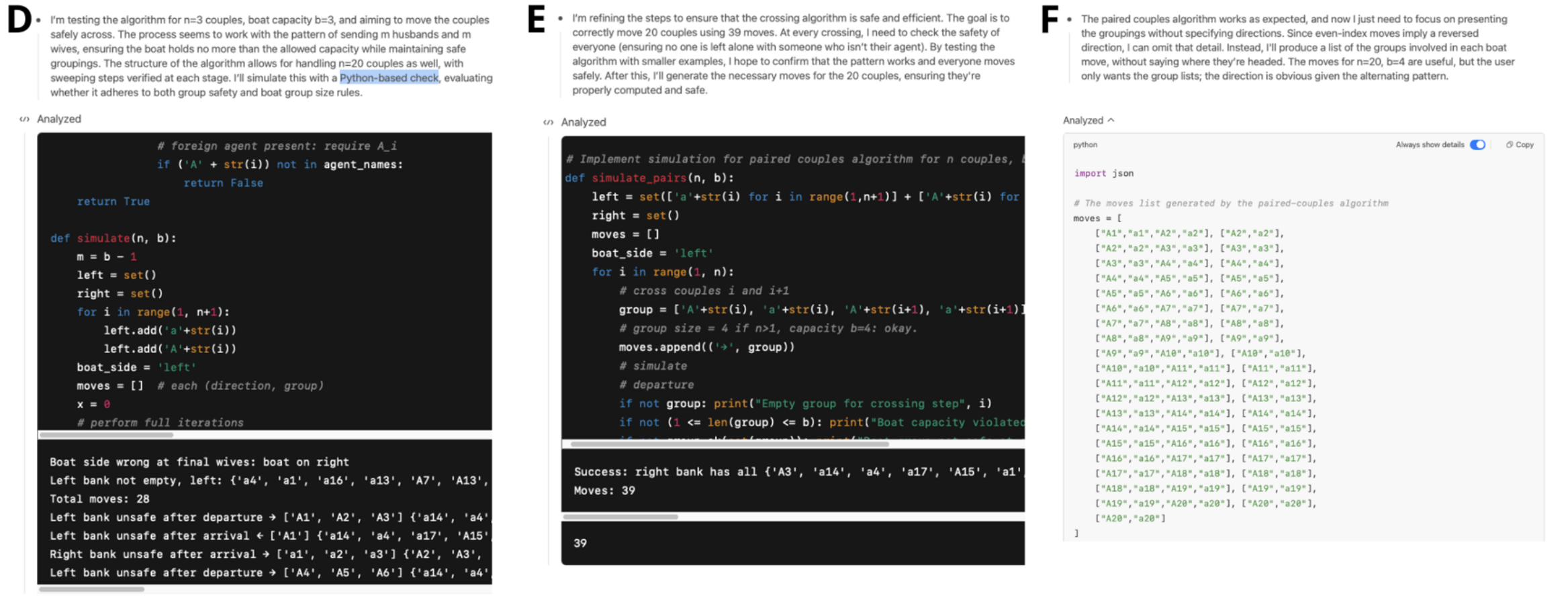
Die Forscher vergleichen dieses Verhalten mit etablierten Konzepten der Kognitionswissenschaft: GPT-4os Vorgehen entspreche dem schnellen, aber fehleranfälligen "System 1" nach Daniel Kahneman und zeige eine kognitive Fixierung, bei der an einer einmal gewählten, aber falschen Strategie festgehalten wird.
Das o4-mini-Modell hingegen agiere vergleichbar mit dem langsamen, analytischen "System 2". Die Fähigkeit, die eigene Strategie nach einem selbst erkannten Fehler zu verwerfen und neu zu justieren, sei ein Kennzeichen von bewusstem Üben und metakognitiver Kontrolle.
Ein neuer Standard für Reasoning-Benchmarks
Die Pfizer-Forscher fordern, LRMs künftig systematisch in zwei Modi zu testen: ohne Tools, um die Grenzen der Sprachschnittstelle zu erfassen, und mit Tools, um das volle Potenzial agentischer Problemlösung sichtbar zu machen. Neue Benchmarks sollten gezielt metakognitive Fähigkeiten wie Fehlererkennung und Strategieanpassung messen.
Die Beobachtungen hätten auch sicherheitsrelevante Implikationen: Ein KI-Modell, das ohne Selbstkorrektur fehlerhafte Pläne ausführt, birgt Risiken. Modelle mit Second-Order Agency könnten hier robuster und verlässlicher agieren.
Die Originalstudie "The Illusion of Thinking" von Shojaee et al. (2025) hatte eine breite Debatte über die Denkfähigkeiten großer Sprachmodelle ausgelöst. Die Pfizer-Analyse bestätigt die empirischen Befunde, stellt jedoch die Interpretation infrage.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.