FlexOlmo ermöglicht KI-Training ohne Datenaustausch zwischen Organisationen
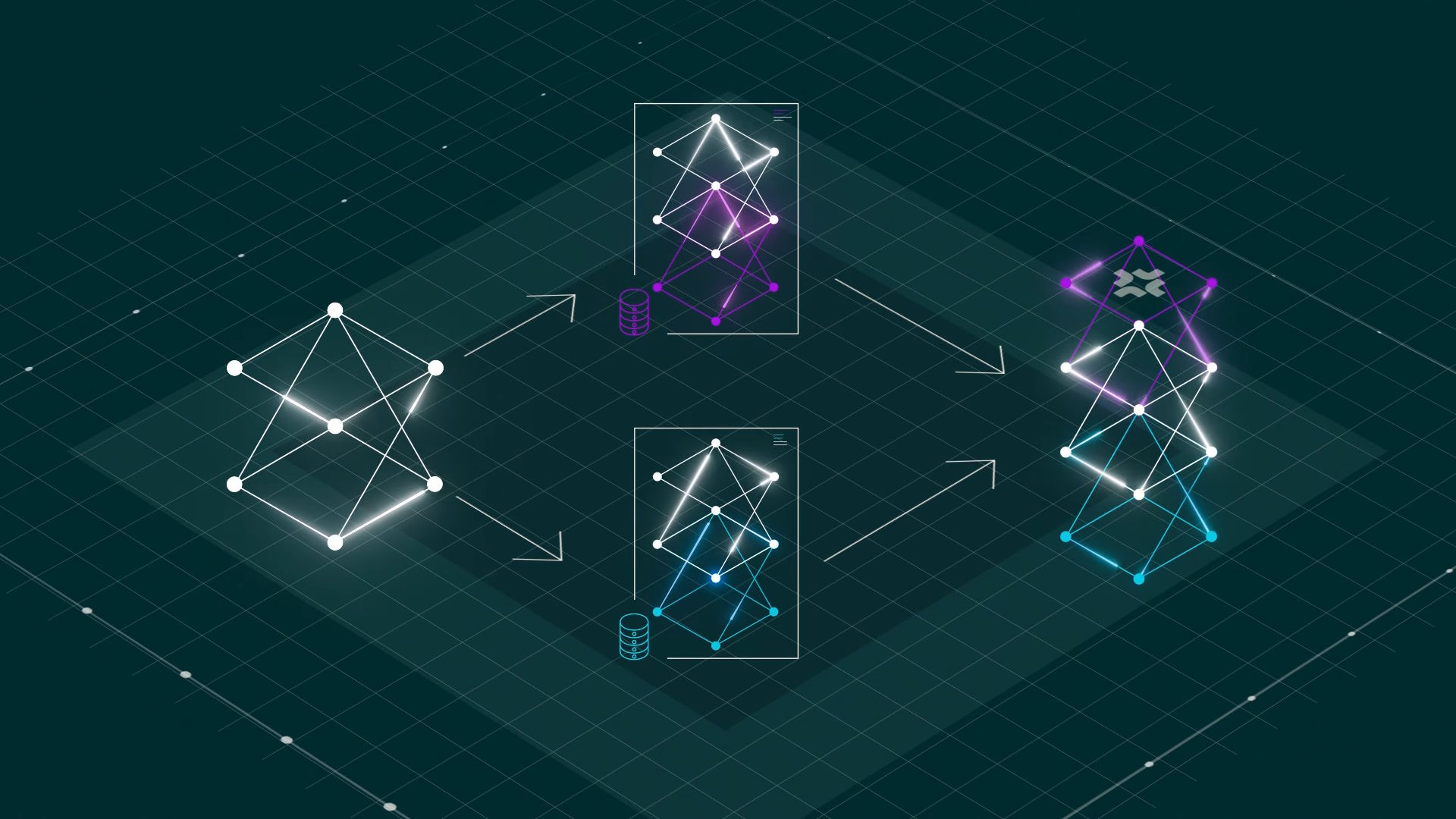
FlexOlmo zeigt, dass gemeinsames KI-Training auf lokalen Datensätzen möglich ist, ohne dass Datenbesitzer:innen ihre Informationen teilen müssen.
Organisationen in regulierten Branchen besitzen oft wertvolle Daten für das Training von Sprachmodellen, können diese aber nicht extern teilen. Das Allen Institute for AI hat mit FlexOlmo eine Alternative entwickelt, die diese Probleme umgeht.
Mixture-of-Experts mit unabhängigem Training
FlexOlmo verwendet eine Mixture-of-Experts Architektur, bei der jeder Experte unabhängig auf geschlossenen Datensätzen trainiert wird, ohne dass die Rohdaten geteilt werden müssen. Alle Datenbesitzer:innen trainieren ihr eigenes Experten-Modul lokal und tragen nur die trainierten Modellgewichte zum gemeinsamen System bei.
Das Hauptproblem beim unabhängigen Training verschiedener Experten liegt in der späteren Koordination. FlexOlmo löst dies durch ein gefrorenes öffentliches Modell, das als Referenzpunkt für alle Experten dient.
Während des Trainings bleibt dieser öffentliche Experte unverändert, während der neue Experte auf dem lokalen Datensatz trainiert wird. Dadurch lernen alle Experten, mit demselben Referenzmodell zu arbeiten und können später ohne zusätzliches Training zusammengeführt werden.
Flexible Datennutzung
FlexOlmo eignet sich besonders für Szenarien mit privilegierten Zugriffen, weil sich bestimmte Datenquellen je nach Anwendungskontext deaktivieren lassen. Toxische Inhalte könnten beispielsweise für Forschungszwecke aktiviert, aber für allgemeine Anwendungen ausgeschaltet werden.
Die Forschenden demonstrierten diese Flexibilität, indem sie in einem Test den News-Experten entfernten. Die Leistung bei News-Aufgaben sank erwartungsgemäß, während andere Bereiche weitgehend unbeeinträchtigt blieben.
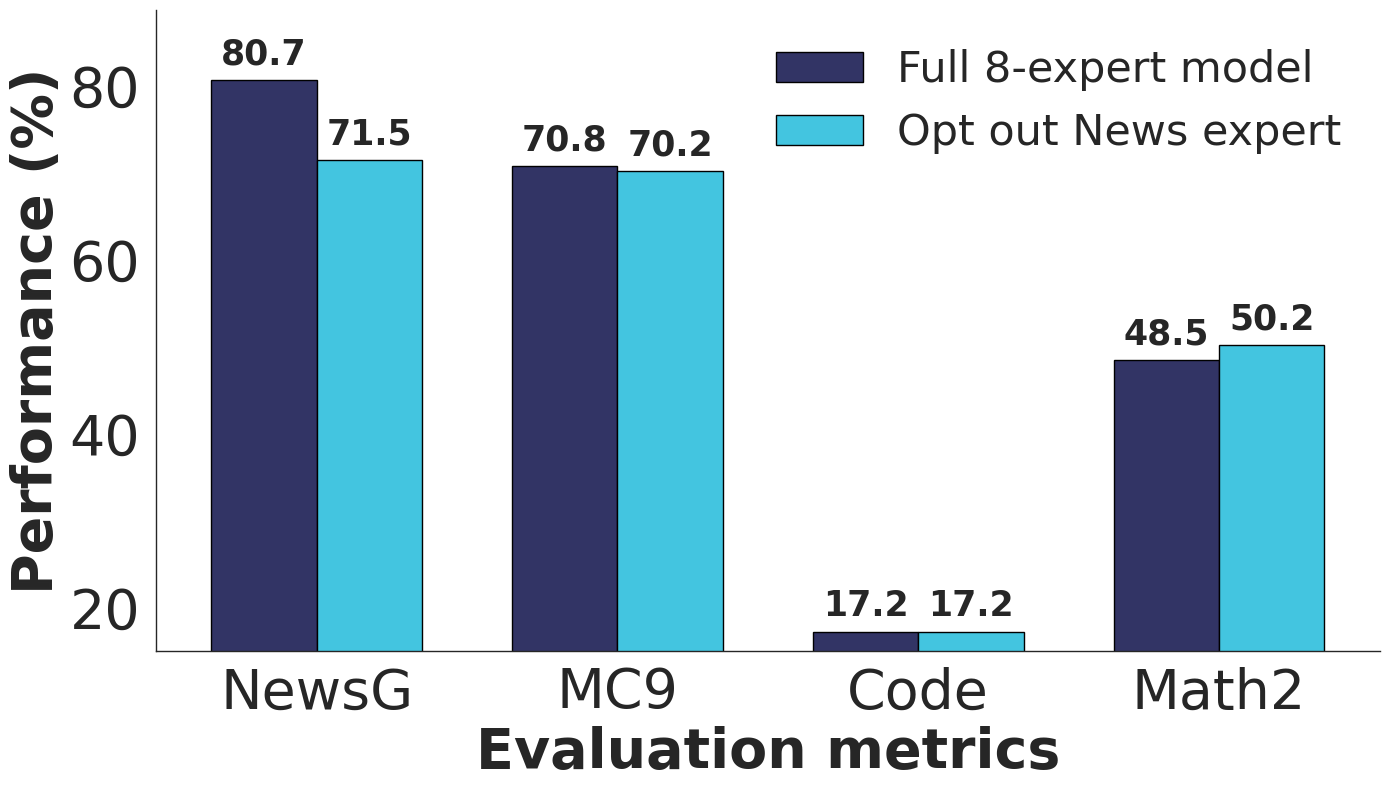
Auch bei sich ändernden Lizenzbestimmungen oder ablaufenden Nutzungsrechten können Datenquellen nachträglich deaktiviert werden, ohne das gesamte Modell neu trainieren zu müssen.
Deutliche Leistungsverbesserungen in Tests
Die Wissenschaftler:innen testeten FlexOlmo mit einem Korpus aus öffentlichen Daten und sieben spezialisierten Datensätzen: News, Creative Writing, Code, Academic Papers, Educational Text, Math und Reddit-Inhalte. Das finale Modell verfügt über 37 Milliarden Parameter, von denen 20 Milliarden aktiv sind.
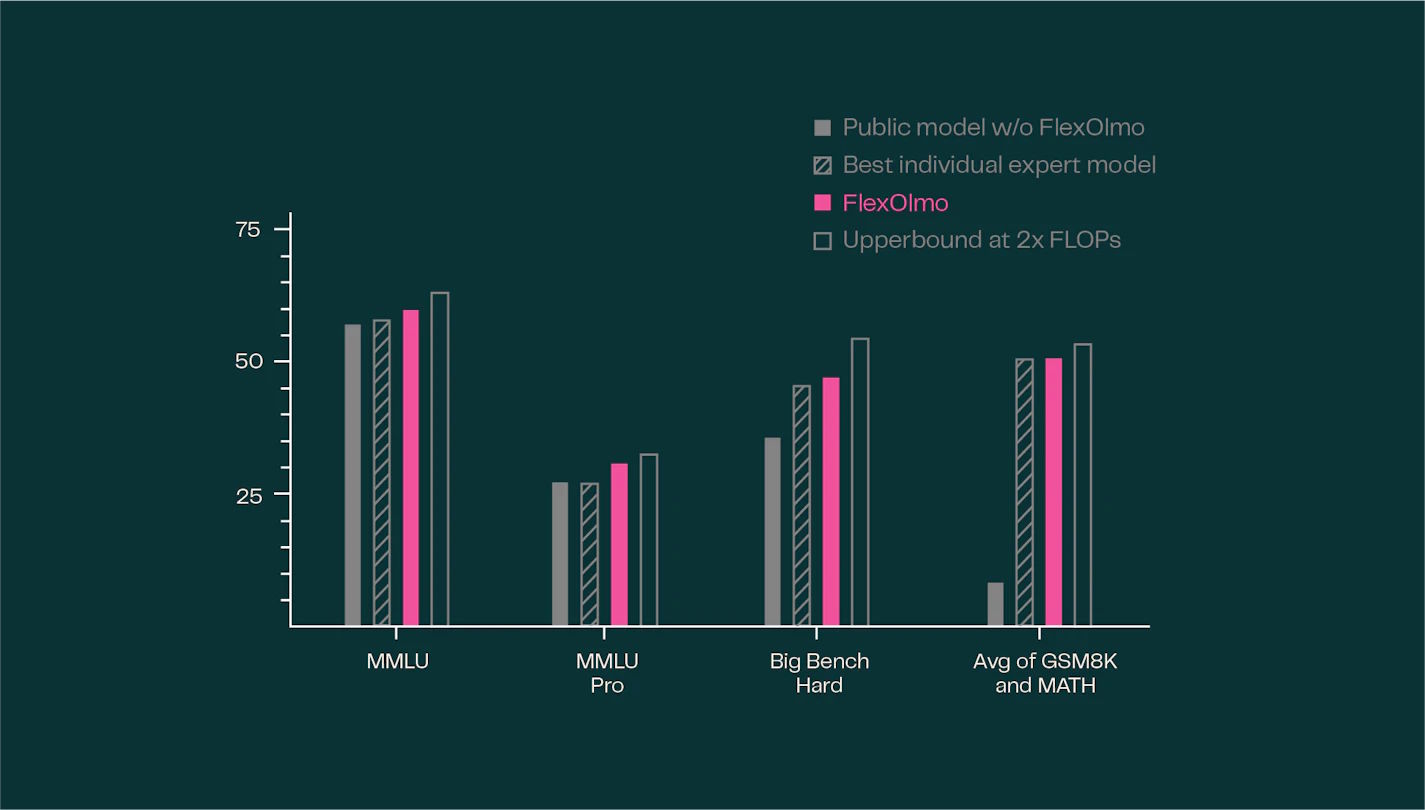
Bei Tests auf 31 generellen und spezialisierten Aufgaben erreichte FlexOlmo eine durchschnittliche Verbesserung von 41 Prozent gegenüber dem nur auf öffentlichen Daten trainierten Modell.
Im Vergleich mit einem hypothetischen Modell, das Zugriff auf alle Daten hatte, schnitt FlexOlmo in generellen Benchmarks bei gleichem Rechenaufwand sogar besser ab. Lediglich ein Modell, das mit doppeltem Aufwand auf dem gesamten Datensatz trainiert wurde, erzielte eine leicht höhere Leistung.
Da Datenbesitzer:innen ihre trainierten Modellgewichte teilen, untersuchten die Forschenden auch das Risiko der Datenwiederherstellung. Bei Angriffen zur Extraktion von Trainingsdaten lag die Erfolgsrate bei niedrigen 0,7 Prozent.
Organisationen mit besonders sensiblen Daten können zusätzlich sogenanntes "Differentially Private"-Training verwenden, das formale Datenschutzgarantien bietet. Diese Methode könnten alle Parteien unabhängig anwenden. Um Ausgaben von Sprachmodellen auf ihr Trainingsmaterial zurückführen zu können, hat das Allen Institute kürzlich OLMoTRace vorgestellt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.